
It is the process of analyzing any given piece of software to determine if it meets shareholders’ needs as well as detecting defects, and ascertaining the item’s overall quality by measuring its performance, features, quality, utility, and completeness. Bottom line, it’s quality control.
Quality control is the process of running a program to determine if it has any defects, as well as making sure that the software meets all of the requirements put forth by the stakeholders. Quality assurance is a process-oriented approach that focuses on making sure that the methods, techniques, and processes used to create quality deliverables are applied correctly.
Automation testing is a software testing strategy in which a tester programmatically runs the tests using a tool or a framework instead of manually going through the test cases and executing them one by one.
- Unit tests: These are written by software developers and test a unit of code in isolation.
- Integration tests: These test how well different software components work with each other.
- Regression tests: Verify that the new code didn’t break any existing functionality.
- Performance tests: Ensure that the software won’t crash and perform reasonably under heavy load or stringent conditions.
- UI tests: Ensure that the software uses a consistent user experience and no visual or graphical elements on the screen are broken.
A test is a good candidate for automation under the following conditions.
- The test is repeatable.
- The feature under the test doesn’t change its behavior frequently.
- It’s time-consuming for a human tester.
- The test involves complicated calculations.
- The test ensures the previous functionality didn’t break after a new change.
Hire QA is hiring for the position of Mobile App Automation Engineers for our clients.
- Location: Hyderabad / Bengaluru / Pune
- Experience: 3-6 Years
- Skills Required: Appium, Selenium WD, Java/Python, POM, TestNG / BDD Cucumber, ExtentReport, Git, Jenkins
Strong knowledge and experience in
- Immediate joiner with strong experience in mobile app automation using Appium and Java.
- Strong experience in Selenium WD, POM, TestNG/BDD Cucumber, ExtentReport, Git, Jenkins.
- Experience or knowledge in automation framework design or improvisation.
Hire QA is hiring for the position of Selenium plus Functional API Test Engineers for our clients.
- Location: Hyderabad / Bengaluru / Pune
- Experience: 3-6 Years
- Skills Required: Selenium WebDriver, JAVA, TestNG/BDD Cucumber, POM, Maven, Extent Reports, Jenkins, Postman
Strong knowledge and experience in
- SDLC Models, Agile Methology.
- Requirement analysis, test case design, test case execution.
- Identify, record and track bugs to closure.
- Test Strategy and Test Planning.
- Estimate, prioritize, plan and coordinate testing activities.
- Perform feasibility study for test automation.
- Designing and building Selenium Test Automation Frameworks (Hybrid & CUCUMBER).
- API / Web Services Testing using Postman.
- Configuring and scheduling jobs in Jenkins.
Performance testing is a specific type of testing that determines a system’s responsiveness to a particular workload in a particular context.
It also allows to verify and validate non-functional attributes such as scalability, reliability, availability, and resource usage.
It is essential to test to verify that the product or software built behave s as expected by the customer, meets or exceeds the expectations.
Personal information shared by the end-user is secured while using the product, application, or services. The features provided in the application perform as per expectation and requirement.
The product has no serious anomalies.
By testing an application, any deviation from expected behavior can be identified and reported to the stakeholders.
Testing is a process of running an application to identify any defects that breaks the functionality, Features provided in software offer results as expected, System securely display output as quickly as possible. Software features should display same output and behave as expected every repeated instance of running it.
The software can be tested manually by testers or can run automatically using a script and follow steps that tester execute to test the application.
Quality of a product or service can be defined as a level of reliability that meets or exceeds expectations of end-user. For Example, the taste of Amul ice cream or any of the dairy products available in the market produced by Amul is reliable for the quality, new products introduced in market also exceed the expectation.
Following are important artifacts essential for testing any software application
Test strategy is high-level document that defines test approach for the software, what features are essential to test (objective of testing), how to test (methodology), Types of testing to be carried out, and execution of tests.
Test plan decides which tests are for manual testing and which one is for automated testing (distribution of testing task), Who will test what(test schedule), and when to start testing and end testing (duration within which testing should complete)
Test cases are scenarios with steps to be carried out, mapped to requirements with the expected output, to be carried out during testing of an application with status for each scenario, based on the actual result. Test cases can be executed manually or converted into scripts to be executed with the help of tools like selenium or QTP.
Test Data is the valid values that are fed to an application as inputs while running an application in order to test it. It is mandatory to design valid test data as per the scenario that results in expected output. In case the actual output differs from the expected output, the deviation is reported as a bug in the defect management system.
Test Environment is a system configured that mimic or match to system specifications at the client, in order to run software on this system to verify how the system at client be have for the tests and use cases.
- In order to test, a tester should first understand –
- The requirements and output expected by using a software application and from software requirement document approved by the customer and project owner.
- How software works, domain knowledge (software used in specific discipline or field such as e-commerce, Banking, Insurance, Enterprise Resources planning, Gaming, Education or training, or Search – based application)
- Whether the software is desktop based or web based
- What are the features and its functionality,
- How many input forms to be filled in, what are the input fields and their valid values,
- How user interface elements like text field, radio button, checkbox, drop -down list, buttons and their types (submit, reset, cancel) functions.
- What to expect in an output form.
- Working of computer, types of networks.
- In case of desktop application, what technology is used in developing a software How to install the software?
- What technology is used in building user interface? (HTML, XHTML, JSP, ASP, JavaScript, VBScript, JQuery)
- Where reference data gets stored, where data for analysis will be uploaded and then processed What database type is used to store data?
Desktop applications are those software that can be installed on standalone machine called as client machine (desktop or laptop). These software use native resources of standalone machine such as network, CPU, memory and storage, in order to perform specific task for which they are designed for.
Desktop applications are designed to run on standalone machine, by single user. Multiple users can access the printer, scanners if they are LAN connected with desktop applications.
Some Examples of desktop application are Windows file explorer – to access files stored on hard drive of local machine, Microsoft’s office applications such as word, excel, PowerPoint to write and access documents, generate tabular reports on finance and design presentations, Web browsers to access websites and searching information on the internet.
Desktop applications are feature-based applications, where users should be proficient in operating such applications, understand its features, accessing the menu, submenu. Software’s features can be tested with Graphical user interface tests, end to end testing, and functional testing. Non – functional testing will depend on stand-alone machine’s limited resources such as CPU, memory, storage, accessing files, or use features like printer/scanner if desktop applications are connected in local network.
Web-based application need web server in order to host them, visitors need internet connection and need a browser to access the web site, and internally web sites process user requests and send responses via hyper Text Transfer Protocol (HTTP). Multiple users can access same feature of web application at same time simultaneously.
Examples of web-based application are e-commerce portals for online purchase of products of our choice (amazon.com, Flipkart, bookmyshow.com), websites of most of the companies, universities, search engines (google.com, altavista.com).
Web-based applications require browsers such as (Internet Explorer, Chrome, Firefox, Safari, Opera), and a reliable internet connection to explore. Web-based applications can be tested for functionality testing for any invalid page redirects, broken links, page not displaying.
Working of web elements such as input field, drop-down list, checkbox, radio button, submit button. verify for valid input data entered, methods used while data submits, compatibility tests for browsers used, performance to test latency (time taken to access pages), delay in opening next pages or output, and Security testing for verifying login for authentication.
- Anomalies are something that deviates from normal, standard or expected. Based on different situations anomalies are termed as listed below :-
- Error – When the developer identifies mistakes in his code, he says Error for the anomaly.
- Defect – When Tester discovers and reports the anomaly, he says Defect to the anomaly.
- Bug – When the reported defect is accepted by the developer, it is called Bug.
- Failure – When software build does not meet requirements, it is called a failure by the product owner.
- Wrong – when there is a deviation from specification or requirements not understood, the anomaly is termed as wrong
- Missing – when a feature is missing after the software is deployed at the client site, it is said features are missing.
- Extra – when the developer produces the feature more than the requirement, it is calle d an extra feature. It will be termed as an anomaly as you are giving what is not asked for
- Arithmetic defects – are numerical data related defects, like not displaying decimal points in case of banking, scientific, or e-commerce sites, these defects occur due to mistakes from the developer side.
- Logical defects – are due to not understanding business logic for the required output , like if age >=18 you will get driving license, in case developer reverses the condition, even with age equal to or greater than 18, you won’t get a license, but will get for age less than 18 years, that adversely affect real -time situation.
- Syntax defects – occur if the condition required is not applied properly by developer, like in software that corrects grammar in sentence, say to locate vowels in sentence i.e. word beginning with a, e, i, o, and u characters, will be a vowel, and should proceed with letter ‘an’. If developer forgets to enforce this condition, vowel can’t be found or corrected if ‘an’ is not preceding it.
- Multithreading defects – multithreading is an ability of CPU to execute multiple tasks simultaneously. If developer cannot able to produce such ability programmatically, then application cannot execute multitasking, such as downloading an image in web page and rendering it on screen.
- Interface defects – If developer cannot maintain order in which data flow should follow or page displayed after current displayed page, then it is called interface related defect.
- Performance defects – If latency (delay in displaying page) is too high, if server crashes during multiuser access, these are Examples of performance defect. This can affect adver sely and user will not return back to website.
It is expected while testing a software, tester should reveal all the defects and deviations from requirements, while running an application such that it should break. Tester should understand domain knowledge, able to design actual scenarios, conditions that are not thought of and not handled by developer, able to configure specifications and preconditions to verify how appli cation performs. Have analytical knowledge and logical thinking; think out of box while testing software.
Unit testing is primary test level, one way is static testing, where code is verified for syntax, rules followed by organization which is conducted by developer, second way is dynamic testing where small snippet of code is debug (tested) with sample test data to validate the output. Various tools for unit testing are JUnit, Hansel, and Testing are used to verify code coverage.
When application build is released after bugs fixed from the developer, and or changes due to additional requirement, the testing carried out is called sanity test, to verify that bugs are fixed, still functionality is in place, and no new bugs or defects are observed. In case while running sanity tests, bugs still exists, testers can reject the build.
When software build is released, tester conducts primary tests like all the menus and submenus are clickable, and display the corresponding page, tester make sure that mod ules and feature are present in application, and there is absence of ‘Page Not found’ message while accessing any page, Forms and Pages have all usable web elements and display stable pages.
Example, drop down list in all the input form does not display it ems for user to select, due to any reason, this if found during the smoke test, then tester will stop testing and can reject the build by informing the short coming to development team.
Tester use testing experience, while testing an application, explores the features and learn about how the application works, during testing, he makes note of how the application be have s, and such tests are called exploratory testing. The requirement document is absent, and testers are exposed to the application first time, without any test cases created.
Integration testing is the second level of testing after unit testing, where different modules are combined together and then tested for verifying that data flow in sync between the modules and there is no a broken page or failed functionality.
Example –During integration testing, IRCTC site can be checked where after searching train, booking seats in particular train, when payment gateway, which is integrated into application found not working.
System testing is the third level of testing after integration testing, where the application under test is tested for an end to end functionality, to confirm that it works as desired.
Example – matrimonial portal can be tested from registration, searching candidate, receiving contact details and meet or fix appointments with prospects.
Interface testing is a verifying communication and data transfer between two different systems, where interface can be API or web services.
Example – Booking air tickets using ticketing portals like goibibo.com, where ticket is booked using web service of the airlines showing flight time, destinations, availability of seats and fare to travel to destination from starting point.
Regression testing is conducted on the build after bugs are fixed build, to validate that code change to fix bug has not adversely affected functionality and there should not be another defect.
Alpha testing is a type of acceptance testing, where testers are employees of an organization who has built the application, these tests are conducted to verify that all the issues found have been resolved and have not reoccurred, before releasing to the client.
Beta testing is tests conducted at the client’s site after application is deployed and handed over to client. These tests include usability, functionality, and reliability of application.
Performance testing falls under non-functional testing type, where latency (speed or delay in accessing or loading a page), responsiveness and stability of application, network, stress or load tests are carried out to check efficiency/performance of application.
Load testing is one form of non-functional testing, in which behavior of application is observed when itis exposed to load.
Example, verifying behavior of Netflix portal during movie streaming by viewers between evening 7 pm to 9 pm in any time zone.
This non-functional testing is conducted by subjecting an application to overload in order to verify till how long system is sustaining to the stress, hence the name – Stress testing.
Example – during amazon festive season sale, subjected to overload when users multifold times than expected will access the portal and book a newly arrived mobile, there by website server may fail to handle such a heavy load.
Security testing is a testing of an application against malpractice from hacker, how effective protective software like firewall or antivirus installed are in data protection, and vulnerabilities of login system by sql injection.
Software or an application is tested without executing code, such as Code Review, coverage that business logic is properly taken care is called Static testing. Variable declared but not used in code, undefined variables, unreachable code, syntax violations and code structure approved in organization.
Tools like code compare, coverity, parasoft are used for s tatic code analysis
For dynamic testing, application should have compiled code and executed in order to run application, various parameters such as CPU, memory, latency or time taken for output, are analyzed and recorded. Valid input values are prepared and expected output values are listed as requirement.
Main test types included in dynamic testing are functional and non-functional testing. test level included in dynamic testing are Unit, integration, system and acceptance testing.
Compatibility testing are conducted to verify that software runs on various environments, operating systems without any conflicts. Compatibility of an application is tested across different Hardware configuration, operating systems like Ubuntu, Linux, windows, MacOS, Network, Browsers like firefox, chrome, opera, safari, various devices like desktop pc, laptop pc, mobile, etc.
Reliability testing is carried out in order to confirm that software display reliable output that is same irrespective of test environment, operating system, browser etc.
Compliance testing is a non-functional test that validates that the software designed meets all the prescribed standards as described in requirement document. for Example Vehicles in North America are made according to Canadian Environmental Protection Act 1999 (CEPA 1999), under this act Environment Canada has an authority to regulate emission from on-road engines
Localization tests verify that application can be used in specific region. The test includes user interface, language, currency format, date and time format for that specific continent or country having particular language dominance.
Example, In case software developed specific for middle east, language will be Arabic, currency being riyal and dirham for united arab emirates. date format in Saudi Arabia is dd/mm/yyyy.
Test case is set of instructions and steps to be followed to validate particular feature should fulfill requirement specified in software requirement document. test cases can be derived from requirement traceability matrix, which is derived from requirement document.
Test case template should have details common across test case such as test case created by, tested by, tested on, module name tested with their details. Test case template should contain columns as listed and explained below :-
Test case id – unique identification of test case
Requirement Traceability Matrix id – test case scenarios or condition mapped with RTM id. Test
scenario – short description of what should be tested eg. user should able to log in
Pre Requisite – assumption for test to carry out, such as application log in page is already displayed in browser or desktop.
Test steps – steps to follow in order to test the scenario, manually or using scri pt automatically
Test data used – valid test data created specific to the scenario eg. username – admin and password test123 to be used
Expected Result – what is expected from the feature being tested e.g. welcome page with menus of other features should be displayed after user successfully logged in to the application.
Actual Result- what is actual output or result after testing application, this is to be filled in by tester
Status –If there is difference between actual and expected result test will fail, else test will pass
Remarks – In case test fails, bug report details can be mentioned here
Use case describes how person utilizes system or process to achieve his goal. it helps to assess entire process, which part of the process is error prone. Main elements of use case are Actor, System and Goal. Stakeholders, preconditions, and triggers are additional element s of the use case.
main elements of use case are Actor, System and Goal.
Actor in Use case – is an end user, single or group of people, interacting with a process
System is the process required to reach final outcome.
Goal is successful user outcome.
Test scenario is functionality or feature that can be tested. It also provides high level idea of what need to be tested, in order to create scenario we need set of test case s where we can understand features of application and any short comings of application.
positive test cases ensure that using valid data, application performs required output as expected or not. With positive test case, tester decides that feature provided works if provided with valid test data.
Negative test cases are performed to try break the system, by providing invalid data, or following path not proposed, main intension here is to uncover hidden defects, that are otherwise remain in the software.
Behavior driven testing focuses more on user behavior in certain conditions (say how printing a document in case he receives a message for “page area out of margin” =- how will he reacts…, normally) rather than technical functionality of software.
Acceptance testing is final level in software testing, where purpose of test is to anal yze if software features are in compliance with business requirement, and can we deliver to the client, does all features functions as expected, and with the features can we deploy software on production environment
Vulnerability testing are assessment of software and underlined infrastructure, to reveal security loopholes or risks that are critical present in software due to which some loss should be incurred.
Example – some application requires end user’s email address as username as log in credential,registering email can offer a risk of receiving unsolicited mails.
When we test application without worrying or having knowledge about details of implementation, how internal code structure applied to software to achieve required output. it is called black box testing. This type of testing is carried out mainly by testers. Some of the testing techniques for black box testing are Equivalence Partitioning, Boundary Value Analysis, and Cause Effect Testing.
When internal implementation and internal code structure are known to the tester, while testing an application, it is called white box testing. White box testing involves code veri fication for security holes, poorly structured code process path, data flow of inputs in code, conditional loop, testing of statement, object, and functions in each code class. Some of the testing techniques for white box testing are Statement Coverage, Branch Coverage, Decision, Condition, Control flow and Data flow testing.
When tester has partial knowledge of internal working and features of an application. Grey box testing is conducted to find defects due to code structure, improper functionality and missing condition in the feature. Various techniques used in grey box testing are Matrix testing, regression testing, orthogonal array testing, pattern testing.
In Software Development Life Cycle, there are mainly four testing levels –starting from Unit testing, followed by Integration testing, System testing, and finally user Acceptance testing.
When testers testing of various modules that are linked together in order to accomplish features expected to accomplish. Testing modules in combination are called integration tests.
Example – After log in to Amazon portal, user can view his orders history, pending orders, Amazon wallet details, Prime videos streamed from where he can re order already procured item using his wallet balance amount as well as check video or movies already streamed. Integration tests require tester to check log in details of a user, that has placed orders and has purchased from amazon in past, also should be a prime member to avail facility like music, movie and free of charge deliveries.
Top Down Approach of testing is breaking down complex module into smaller portions till it becomes easy for assessment.
Example – Top management forms rules for organization, middle level management and lower level employees has to follow the rules enforced.
Stubs are the called programs that temporarily replace the missing modules, help in testing integration testing, where flow of data is takes place from Top to down approach.
Bottom Up Approach of testing is combining smaller modules which are easy to test, into larger single complex module.
Example – Small group of students assess the situation or problem, find solution to resolve it. The solution is discussed with teachers and then applied to other groups, and on successful outcome, becomes appeal to higher management, who can make it implementation
Test Drivers are calling modules that are temporary replacement of upper level module that are not yet integrated. Drivers fill the gap of absence of modules to verify flow of data to higher level modules.
GUI ie. Graphical User interface, relates to frame or screen displayed to end user as an interface that makes them easier to access an application or software. In case of desktop application, Microsoft office or paint opens up user interface when paint.exe file gets executed, In case of web based application, all the portals that opens index.html page where user can check all general information about the website, and has login and signup links, allowing new user to register and existing user to log in.
Functional testing is test working of web elements; drop down, buttons, check box or radio button, and features of an application. Functional testing is categorized into various types such as unit test, integration tests, GUI tests, localization tests, usability tests, regression tests, system tests.
Example: on clicking print button, a pop menu should display showing existing page and print configuration window, with print button. On clicking on print button, contents such as text, images or spreadsheets on selected page should be sent for printing.
Nonfunctional testing deals with testing parameters other than features of an application, these include performance, reliability, security, integrity, scalability, portability, etc.
Example: In case of desktop software say calculator, how quickly it displays an output, for multiplication of four digit numerals. In web based application, how quickly an image is rendered on the webpage, or if site is available 24×7 or is subjected to frequent maintenance, making it non-available to end users.
Requirement traceability matrix (RTM) is a document that maps test cases with the requirements discussed in software requirement document. RTM is a single document that make sure that all the requirements are mapped and are covered and has test cases corresponding to the requirement.
Defect traceability matrix is a document that maps defects if any with corresponding test cases, this document helps to trace defects, test cases and requirements thereby gives an idea of whether defects have been resolved or not, if resolved and build is received, then test cases selected for regression tests corresponding to this defect and some integration test cases to make sure defect has been
resolved.
Following are few techniques used in test case design :-
i) Equivalence Partitioning
ii) Boundary Value Analysis
iii) Decision Table
iv) State Transition
v) ErrorGuessing
Test Scenario- In order to get a driving license the age of applicant should be between 18 to 49 years.
There will be 3 (three) partition where tester should check possibility
i) If applicant’s age is less than or equal to 17 years – Invalid
ii) If applicant’s age is between 18 to 49 years. – Valid
iii) If applicant’s age is greater than or equal to 50 – Invalid
So there will be 3 possible scenarios where only one valid group of applicant having age is between 18 to 49 years, will get driving license.
Test Scenario- In order to get a driver’s license, the age range should be between 18 to 49 years.
Boundary values to be verified here is
First Boundary value
Minimum age – 1 i.e. 18-1 = 17 years – invalid age
Second Boundary value
Minimum i.e. 18 years, minimum +1 i.e. 19 years, maximum -1 i.e. 48 years, and maximum i.e. 49 years (18, 19, 48, 49) – Valid values for age criteria.
Third Boundary value
Maximum +1 = 50 years – invalid age
Scenario – You want to buy headphone and have budget Rs.1000
You have following buying options
i) Vijay Sales
ii) Reliance Digital
iii) Chroma
iv) Amazon
Based on Answers to the following queries, we will be able to decide
Where should we buy headphone from
Can take trials before purchase
Have EMI options
Accepts Credit Cards
Accepts Cash on Delivery
Do they have return policy
Have Item in your budget?
When tester finds a defect while testing application, he will confirm deviation with expected result, registers defect (bug) in bug management tool like Bugzilla or JIRA. Bug status will be ‘New’, If defect is not agreed by product team or developer, its status will become ‘Rejected’.
When developer agrees with the defect in application, when assigned to developer, bug status will be ‘Open’, If Developer does not agree to the defect; its status will be ‘Deferred’.
‘Open’ bugs when resolved by developer its status becomes ‘Fixed’, once the bugs are fixed and build is retested for regression testing, defect is verified, i f defect is not resolved, bug will be ‘Reopen’, which will be reassigned to the developer for fixing. if defect is resolved and confirmed by tester then Bug status will be ‘Closed’.
Severity of bug is an extreme level of damage like financial loss, company’s reputation and loss of life, due to presence of the bug. Example such as if point of sales machine does not function as expected, and does not dispense bill, thereby customer may not pay the amount for the purchases, in such situation, the defect due to which bills are not displaying amount of purchase, is termed as severe test case, as due to such defect, there will be huge financial loss. Further say, infrared machine that used for removing decay in the teeth malfunction and damages the jaw of patient, it may result into loss of life.
Defect severity are categorized into following levels
Blocker – Due to this defect type, it becomes impossible to further run the application, there for the name – Blocker
Critical – There are some workarounds to accomplish the task, e.g. pdf format of file type is not downloaded, whereas word type is possible.
Major – some error may lead to understanding the title or content by end user, e.g. software display s title and content in English, but does not display some of the title in Arabic language, but display it in English only.
Minor – there are some defects which has very minor impact on functionality of application, e.g. missing space between words, commas are missed in sentences.
Low –These defects does not impact at all, however if fixed it will be aesthetically pleasing, eg. Size of button, form border go out of screen and need to scroll in order to view the content.
Priority gives a need of urgency to fix or resolve the defect, Example can be if a reputed pen manufactures company while printing the pen model or company name will wrong spellings, then such bugs should be fixed on priority basis.
Defect priority are categorized into following levels
Urgent – this must be fixed immediately e.g. payment gateway pages not displaying, or conformance of order processed not sent via email or sms, or transaction records not printed in account details in banking software.
High – this should be resolved in subsequent releases, e.g. presentation or video does not have company logo or has written content, but does not have voice that narrates above content.
Medium – should be fixed based on the level of severity- eg. Error occurring while user updates his mobile number, while communication has options such as his email and mobile.
Low – May or may not be fixed e.g. spelling or grammar mistake in introductory page of portal, as long as meaning is conveyed to the audience.
Quality assurance (QA) is targeted for avoiding defect, whereas quality control (QC) is aimed at identify defect and fix these defects. QA is process focused whereas QC is end product focused. Quality Assurance team usually in manufacturing industry gathers certification related to quality of raw materials used, machineries used in processing the end product and final product. Whereas Quality Control team is software testers inspects by running or analyzing steps followed in products and services to make sure that it is working fine as per expected standards.
Inspection is an observation where a site is expected to perform or follow standards as compliance obligations, whereas audit is a process of checking if obligations are met or not. Inspections are simple, quantitative and help create actions, whereas audits are complex, qualitative and forms recommendations.
It is a analysis to observe deviation between actual performance and expected performance. Basis of assessment is an improvement in actual performance, whether new hardware, or additional storage capacity or memory improvement or line of code that does not consume processing power, but quickly display output.
It is important for test managers to keep an account of test procedures followed, test plan, test methodology, justification of number of test cases required to be conducted manually in order to verify complete feature coverage, and why these manual test case not able to be carried out using script, automatically, and finally after executing said number of tests both manua l and automatically, how many defects have been captured. There are various test management tools that help manager with reports on what is optimum effort put in testing and what is final outcome. These tools have built-in test ware management; test scheduling, test tracking, incident management, and test reporting.
Based on the level of maturity model i.e. implementation of various processes of software life cycle, adherence of procedures even during critical and crisis situation is called test maturity model
Based on Capability Maturity Model (CMM), software development organization’s level are decided. There are five levels
Level 1 – there is an ad hoc testing, chaotic work culture and no adherence to process during time of crisis, they always use new and undocumented repeat process during software life cycle.
Level 2 – The processes are defined and same steps are repeated during each new p roject.
Level 3 – There is standard business process in each of the defined processes followed without any alterations.
Level 4 – The mapping of the processes are managed accordance with agreed upon metrics.
Level 5 – there is regular and frequent process optimization and improvement during process management
There is a measure of process capability calculated using specification limits and standard deviation of the process, which is Cp index. Most companies require Process Cp = 1.33 or greater.
The term used in short is CAPA, stands for Corrective Action Preventive Action.
Corrective Action Preventive Action (CAPA) is a process which
investigates and solves problems,
identifies causes,
takes corrective action and
Prevents recurrence of the root causes.
Example – when we fall sick, we seek medical attention, and health care specialist offer us remedy and relief, but what if we do not get relief or do not recover. We ask for corrective actions and we think of preventive action as well.
Software Testing Life Cycle (STLC) is a sequence of activities performed by testers such as
Requirement & Analysis – Understanding the client’s requirement and what actually requires, How to test the requirements,
Test Planning – what should be tested in an application, How and who will test the application
Test Case Design – test scenarios, mapping with requirement traceability matrix, test case creation, and test data used
Test Environment Setup – what hardware and software need to install or configure to build test environment.
Test Execution – running the application in order to verify features as per test case designed, reporting bugs, track the bugs and regression test till it gets resolved.
Test Closure – Creation of test reports, total bugs pending, critical bugs if any, justification for releasing application to client.
Document approved by customers and project owners that describe, what is expected from the software to perform, how many features and functionality, what is requirement ( what to verify/validate). In short, Software requirement specification document has a purpose for software to be built, description of software to accomplish and requirement in specific required to fulfill using the software.
In order to understand features and their functionality we refer requirement document (SRS). In order to understand overview of data flow, integration between systems, we should refer design document, For understanding documentation on code, algorithms, interfaces and APIs used in software technical documents or process documentation containing UML diagrams, How end user will use the software we can find from user manual, and finally how to install the software can be found from installation guide of the software.
Regression testing is the testing of an application that verifies that there is no adverse effect of the changes made due to defect fix or change request to other areas of application. regression testing involves test cases other than those that are related to defect or change as per client request, but it also tests features that directly or indirectly connected with the feature that was rectified by developer against the defect raised, such as integration tests, test case related to web components and their functions along with those involved directly with defect raised. Regression testing is usually car ried out using automated scripts by selecting test cases and re executing the scripts to run those test cases.
Retesting is a testing to make sure that previously failed test cases due to defect are passed and the defect has been resolved. The test cases involved in retesting focus only on the failed test cases due to the defect or the scenarios or steps followed result in failed functionality. It is better to carry out manual testing in case of retesting to make sure that defect has actually been resolved.
Selection of test cases for regression testing for the build received from release, should based on following scenario priority for testing those test cases that were failed due to defect, on testing if they are passed. All integration tests, boundary value scenarios, testing functionality of components related to defect, end to end tests that involve change request or resolved test cas es after release,
should be considered for regression.
System testing is a test level after unit tests and integration tests in software testing life cycle, where application as a whole is tested end to end for functional as well as non -functional requirements. It is performed after integration testing. Usability, performance, scalability and secu rity testing are involved.
Integration testing is testing of interconnected units and their interfaces, the data flow between these units and to make sure that feature is working as per expected. it is carried out after unit testing.
Various test approach like top down, bottom up or hybrid integration are carried out during testing.
- Test plan document should include following details
- Features to be tested
- Features not to be tested
- Approach like should we test manually, automated scripts, test techniques (white,black or grey box)
- Criteria for Failed tests / pass tests
- What condition for suspending test activities
- Test environment such as hardware, software, network etc.
- Man hours estimated while testing
- specific training required, Risks involved, any assumptions or dependencies
Tests that are carried out while exploring an application, and learning about the business requirements are called exploratory testing. These tests are carried out by manual testers without referring to any test cases or test scripts. Exploratory tests are carried out by experienced Software testers based on their previous testing expertise thereby test cases are designed during test execution. Test steps carried out should be noted In case of any defect found during exploratory testing, as there is no test cases and test steps written to carry out exploratory testing.
Software Peer Review is a detailed examination of low level and high level design documents by one or more individuals working on the project to find and resolve errors or defects in application during early stages of SDLC.
Code Review – review of code by peer developer will ensure that functionality is met with as expected; there are no memory leaks or dead code which is not utilized while coding.
Pair Programming – Is a process where same portion of code is developed by pair of developers individually and then most efficient code is finalized.
Software Management Review – The project head verifies project progress, status of plans and their status, infrastructure allocation to test and develop the application during management review.
Software Audit Reviews is an independent examination of product, process, assessment with compliance to specifications.
Software Testing Metrics is a quantitative measure that helps in estimating progress, quality and well being of software testing efforts. This helps in improving efficiency and effectiveness of software testing processes.
Test entire application – It is virtually impossible to test and verify entire application with each and every scenario. Even one of the seven principles of software testing says, “Exhaustive Testing is Not Possible”.
Relationship with developers: Tester’s responsibility to check for any defects in the software and how to break an application, it becomes tough to keep amicable relations hip with developers
Regression testing: In every build released from developer, tester has to check entire application for end to end functionality every time along with resolved defect and components or units that are integrated that may get affected due to change request or resolved defect.
Testing always under time constraint: All the stack holders keep an eye on how the built has came out, testers has to quickly start testing the build with sanity test, smoke test and regression tests as send their observations as soon as possible.
Which tests to execute first? – Based on available timeline, and complexity of modules, test lead has to distribute testing like user interface or feature testing using script automatically and regression and integration tests manually. Non functional testing using tools like load runner, API testing using Postman or REST assured. Regression tests using selenium and mobile testing using Appium.
Understanding the requirements: There should be a walkthrough and review of software, domain knowledge, how to test features etc. is mandatory for each member of tester.
Decision to stop the testing: Testing manager should explain testers when should testing be stopped, based on what critical bugs should get resolved, any blockers affecting feature pending by developers.
Main objective for using bug tracking tool is to deliver high quality software product by keeping track of defect discovered and track these defects till it gets resolved, Improve Return on Investment (ROI) by reducing cost of development, when quality product is developed, so that it will have more reliable quality product, satisfied customers with long loyalty. Product and Project team can keep a track of detect Issues Earlier and understand defect trends in ongoin g software development.
Better Communication, Teamwork and connectivity amongst stack holders about software quality.
Website usability testing is to measure and understand how web visitor would experience navigating website to verify its features, accomplish their tasks and any pain points in doing so.
Pesticide paradox is a principle wherein same set of test case if executed again and again over interval of time, then these test cases are not capable of identifying any new defects in the system. in order to overcome this effect, the set of test cases are regularly reviewed and revised to make them effective.
V model is a SDLC methodology where software development instead of moving downwards like waterfall model, moves downwards and then back upwards in V shape, starting with requirement analysis, system design, module design, unit testing, integration testing, system testing, user acceptance testing.
Client Server application is distributed on at least two systems, Client and Server where client has visual pages like input forms, validation for valid data before sending requests to server and output pages as response from server. Server has all business logic, database storage where request received from client machines are responded back after processing through logic and database tables, procedures. Client Server applications require LAN connection and Database Drivers so that they are connected whenever request is sent forresponse. SomeExamples areATM machine, Banking software, and Stock Trading etc.
Web application are built in one server with all front end files, back end and processing logic placed on single web server, various technologies such as HTML or ASP with JavaScript or JS libraries are used for front end design, whereas back end storage and processing is done on server in class files and DB procedures and tables. web application are accessed using web browser, hence it require internet in
addition to web application files placed on web server. Examples of web applications are Amazon, Flipkart and Snapdeal online portal, Gmail, Saavn online music streaming services
: In case of White box testing it is mandatory to know internals of software applications, such as structure, program functions, and implementation of how data flows between components. The tests covers white box testing are unit testing and integration testing. These tests are performed by developers, and it is mandatory to know programming and implementation knowledge, the test is based on design document provided by design team. Various testing techniques used in White box testing are Statement Coverage, Branch coverage, decision coverage, path coverage.
Black box testing does not need any understanding about internal structure of application, the tests coveres black box testing are system and acceptance testing, testing is based on requirement document received from product team. Various testing techniques used in Black box testing are Equivalence partitioning, Boundary value analysis, Decision table testing, and Error Guessing.
Authentication is verify logged in user’s genuineness, in real world you were required to show photo identity documents such as Aadhar card, Driving license, PAN card or Passport in order to receive documents addressed to you from courier, know your account ba lance at your bank.
whereas authorization is verifies what module access rights the logged in user has. real life Examples are You are allowed to explore feature of an application based on your trial period, once you become registered user by paying the registration fees, you can access more features of the software.
In addition to functionality and feature testing, we should test browser compatibility, security tests for authentication and authorization rights, latency – how long it takes to load a web page, or request to come back as a response, load testing based on number of users logged in during peak hours, and scalability testing.
The criteria and conditions are specified in exit document that guides us on when testing should be stopped. When most of blockers and critical bugs have been resolved and application has performance in acceptable limits, we can stop testing. This is however based on some risk that have to be undertaken and time limit.
Cookies are small text files that contain web visitor information such as websites explored, pages visited, visitor’s ip address to identify already visited user. There are various types of cookies,
Session cookies – user navigating websites actively, once they leave particular site, session cookie disappears.
Tracking cookies – are used to keep record of multiple visits that was made to same particular web site.
Authentication cookies – whether a a valid registered user has logged in again and if so with what name?
This one is a tricky question; interviewer wants to know firsthand information from you about your weakness in handling difficult or crisis situation. Answering this question like what is your weakness – you need to keep yourself specific and not to lament problem or difficulties or show any kind of annoyance or hatred for particular stack holder or reporting manager, colleague or developer or some process. You can explain situation however, but should end your statement expla ining how you were successful in controlling the situation.
There are a situation where testing a new build is allotted a bare minimum time, or you are given several tasks or projects to look into. In such case, where you cannot able to completely cover all the scenarios of testing, you can focus on main functionality and features released and check if any critical or blocking defect should not be present in an application during regression tests. Usability, functionality, security, performance are few testing that should be carried out either using scripts automatically or test manually.
Software Quality Assurance (SQA) is a set of activities that validates that the software being designed or built, meets desired quality measures and specifications. Test Assurance team has tasks like auditing and training the stack holders about standards for quality that software should satisfy as per user expectations.
A defect report should inform description about the defect.
Which version or build of software release being tested during which defect occurred.
Which is the module name, how to access this module (path), what were the steps carried out What was the functionality affected, how severe you think the defect is.
Name of the tester who discovered the defect, name of the developer to whom defect has been assigned.
Test case affected mapped to requirement specification document ids and number of test cases that may not be tested due to the defect.
Big Bang test type is an integration tests where multiple modules are being tested simultaneously which may get affected due to change request or defect if any. This helps exploring software with end to end functionality and gives tester an idea about features included and
functionality carried out using the software.
Traceability Matrix & Coverage Matrix is a document that is mapped with software requirement documents and test case or scenarios all in single document. The purpose of such document will ensure that the entire requirements have been covered by test cases and there is no feature or functionality that has been left unchecked.
User Acceptance Test (UAT) is a final test by end user or client’s representative before software is handed over to production environment. It is an end to end functionality testing and verify that proposed features have been included in the software. User Acceptance test are essential as end user will test and verify the application, to make sure tha t the developer has incorporated the features and functionality expected by end user in the software. In addition change requests asked for have been properly incorporated by developers.
HotFix is a workaround which can be some sort of configuration change in order to resolve an issue that could occur in running application or server, with minimum downtime.
Entry criteria are written document without referring to which one cannot begin any of the SDLC phases. In order to begin SDLC phase Requirement document and complete flow diagram of the application as well as Test Plan should be ready and available. An exit criterion is the detailed document that decides moving from current phase of SDLC to the next phase. In order to exit SDLC phases test cases should be written and reviewed, test data has been identified and ready to use, scripts for automate the execution of test cases must be ready.
In order to verify email address, the front end tester should consider foll owing criteria:-
Email address may contain alphanumeric characters as initial portion, special character allowed are dot (.), underscore (_), in initial portion, there should only be single @ symbol separating local part and domain.
Domain name may end separating dot (.) with net, org, com and edu as well as country specific characters eg. In for india, ca for canada.
Mistake in company logo on a product, does not impact its functionality or working , as well as buying or selling activities of product, the defect has low severity. But, this defect will impact greatly brand identity and impact how user will interact or may take as duplicate product, hence such defect is of high priority.
A/B testing is comparing two version of same product, for difference in user experience, performance and any changes that are evident during tests. E.g. comparison of features of microsoft’s word 95 and word 97.
When requirements are specific to test cases, such that code can be improved or defect in code can be fixed in order to meet with the requirements, such kind of development is known as test driven development. The test cases are designed around various scenarios to cover the expected requirements.
Based on testing experience, testers design their test cases or scenarios, such method or tests which are exploratory in nature, in order to locate defect in software, are called error guessing.
Mutation testing is white box testing usually conducted in unit testing level, by changing few statements in source code and validate using debugger. Objective of mutation testing is to assess test case quality based on fault-based test strategy that fails mutant code while debugging.
Ad-hoc is an informal test that can be carried out without referring to requirement specification documents for the application being tested. Ad-hoc tests primarily tests negative scenarios.
Exploratory is formal tests are carried out by experienced Software testers based on their previous testing expertise thereby test cases are designed during test execution.
There is no test case or scenario created during exploratory testing.
While exploratory tests, both positive as well as negative tests should be tested thoroughly.
HTTP is short for Hypertext Transfer Protocol, when you enter http:// in your browser, you inform browser to allow connection via http protocol which is TCP (transmission control protocol), in order to send and receive data packets over the web.
HTTPS is short for Hypertext Transfer Protocol Secure, when you enter http:// in your browser, you inform browser to allow connection via http protocol over secured connection encrypted by transport layer security
Retesting is required to verify that the test cases failed in previous release, are passed after the defects are fixed.
Regression is mandatory to verify all relative or dependent modules and integration tests that are intact even after defect is fixed or after change request.
You need to retest the portion of application where defect was fixed. This may be a portion of tests in regression testing. Experience says, it is safe to do regression after retest ing as to make sure that other portions of software are intact and not affected after defect fix.
Web server is an infrastructure that uses hypertext transfer protocol to respond client request s over internet. Its main function is to store, process and deliver web pages requested to web site visitors. In addition web server also supports Simple Mail Transfer Protocol (SMTP) and File Transfer Protocol (FTP) protocols for email, file transfer and storage. Microsoft Internet Information Services (IIS) and Apache Tomcat are some Examples of a web server.
When various systems are internally connected with each other and can access or exc hange information as well as process one system with another system as interface. Real Life Example is ATM machines, if you have account in State Bank of India of any branch and you have SBI debit card. You need to withdraw cash immediately, you have ICICI bank ATM machine near you. You insert SBI debit card in ICICI bank ATM machine, you enter your credential, the system will internally access SBI server and verify your authentication details along with account balance. When you request the amount to be withdrawn, ICICI bank ATM machine will dispense the cash requested for. with amount remaining in your SBI account. Another Example is you can access and use all banking related functionality from different branch of SBI bank across India.
The software build is application compiled and integrated in order to get tested by software testers.
Release is deploying software with new version deployed to the customer, it has additional features that were absent in previous release, and change request requested by customers using previous release.
Production server is a server used to host website contents such as front end pages, css files, javascript files, backend tables, sql files, procedures etc. integrated and deployed so that end users can access them through their website address using browser and internet, or download on their mobile for using the features of application.
Recovery testing is to test how quick the application is recovered after it has gone through system crash or hardware failure. Tester can change interface, protocol, firmware, hardware, and software configurations as close as the actual conditions. Recovery tests after hardware restored will be tested for getting application again coming back and start running as before. The expense and risk to carry out recovery testing may be substantial and prohibitive for smaller startup companies.
The requirement should be feasible, completely explained in requirement specification document. There should be single requirement, easily read and understood by non-technical people, should not contain definitions, reasons for need of requirement. The requirement should not have any guess work or any confusion (e.g. for how long, 50% or more) should not conflict with other requirements, must include same terminology across document, Can be achieved with existing technologies, met within the schedule.
Accessibility testing is a subset of usability testing, is a process of testing an amount of ease of using the application by disabled individuals. Based on the type of disability various tests are carried out on software to check accessibility features designed specifically for disabled either manually or automatically using tools.
The objective of accessibility testing is listed below
To make sure that application or software can be used by a disabled individual with ease,
To verify that the software is in compliance with the laws formed over requirements for accessing
software by disabled individuals.
To make sure that there is no legal action against the software provider in the future.
Screen Readers like JAWS, NVDA, VoiceOver, Window-Eyes, and Digital voice recorders of brands like EVISTR, OLYMPUS WS-852, Zoom, Tascam and SONY can be integrated with software to add accessibility feature for disabled individuals.
To learn more about accessibility testing visit https://www.qafox.com/importance -of-accessibilitytesting-for-disabled/.
Smoke à Sanity à Integration à System à Functional à Retesting à Regression
Installation testing is to verify that the application has been successfully installed on environment as per the steps and order of installation listed in installation guide and is working as user acceptance tests and expected as requirement document. During every build deployed by software testers on test servers installation testing is carried out. The steps written in installation guide for different operating system can be verified and application is run to check that installation is successful
There are various scenarios like additional load of uploaded files for processing, logged in users, time taken to receive response back due to which bug are reproduced at client side (production environment) and not in the test environment.
The steps or scenario carried out to reproduce defect at test environment but the same steps carried out at development server if does not produce defect. It may happen that there can be some files missing at test environment, code changes at development server due to update on build. Tester has to reproduce the defect carefully conducting steps at development server and advice developer to fix the defect.
Migration testing validates migration of application from old system to new system wi th data integrity, no loss of data, and minimal downtime, with functional and non-functional aspects are met post migration. Pre migration, migration and post migration tests are phases of migration test. In addition backward compatibility and rollback tes ts are executed along with.
A CAPTCHA is a type of challenge–response test used in computing to determine whether or not the user is human. e.g. of captcha are sum of two digits, selection of charact ers containing symbols, numerals, and alphabets which are distorted for user to identify and write in text field provided.
Selection of pictures that contain some of the images asked for. The pages where sensitive user information may get revealed CAPTCHA can be installed, They prevent hackers from performing attacks where they try to break into an account by guessing every possible password combination, and they can also prevent fraudulent sweepstakes entries or illegitimate contest votes.
Many websites have changed their privacy policies after the law and the recent developments of user data breaches in the tech industry. This will help make the users understand what data are collected using cookies and what happens to it after they are collected.
Latent Defect is a hidden defect in software still unknown to end user until particular task or operation is not performed by running the application. this type of defect are difficult to identify, pass through all testing, remains hidden even after production, occurs only in certain scenario, can surface after release of the product.
Fault masking is a technique wherein one defect prevents the detection of another. there are many features that may have defects but remain hidden until these feature are utilized. For eg. In case of login page, developer has provided option to log in with email address and mobile number, until user logs in with valid credentials, the defect as below, wherein forgot password when registered mobile number is entered OTP is not received on mobile (unhandled task by developer), remains un noticed. This is known as fault masking.
Latent defect is a failure that is still hidden as the set of condition were never met that can uncover a defect.
Masked defect is a defect that has not yet caused because another defect has prevented the area of code from being executed so that masked defect can be found.
When set of condition or scenario are executed, latent defect will be discovered. Masked defect can be found once the defect preventing to execute area of application is resolved.
Fuzz testing is an automatic test technique where invalid, random and unexpected data is sent as an input that may result into exceptions like crash, memory leaks or fails to build -in code assertions.
Fuzz testing tools for web security testing are Burp Suite, Peach Fuzzer, Spike Proxy.
- Once tester finds a defect in an application, he should complete following steps in order to register the defect.
- Verify and validate the steps followed and try reproducing the defect.
- Repeat the test steps and ensure that the defect occurs repeatedly.
- Attach screenshots, backend server logs and/or database logs,
- Understand the requirement and analyze the deviation from expected output for the scenario.
- Include the scenario or test case in case, the scenario tested is not covered.
- Report the bug in bug tracking system like Bugzilla or JIRA,
- Analyze the defect and rank it based on its severity.
It is essential to work in team environment for software development industries. Team members may face challenges amongst their colleagues while communicating, exchanging their views, mentoring or allocating the work. Team member conflicts are common while delivering tasks in high pressure environment.
To resolve conflict amongst team members as a test lead you should talk individually to each person and note their concerns.
Find a solution to the common problems raised by team members.
Arrange a team meeting, reveal the solution and ask people to co-operate.
Charles Proxy testing is a testing for decrypting web traffic on computers and mobile devices. It is a cross platform HTTP debugging proxy server application that enables user to view HTTP, HTTPS, and enabled TCP port traffic from and to local computer or mobile device. In addition, it also records requests and responses along with HTTP headers and metadata (e.g. cookies, caching and encoding information) during web traffic.
- There can be various mistakes that may create issues in project delivery.
- Assigning incompetent resource to manage the project.
- Lack of resources and skills.
- Doing everything myself approach instead of distribution of work as per resource and their skills Lack.
- of proper communication and failure to pass the message across the stack holders.
- Project initiation or start up is poorly managed.
- uncertain or unclear objective of project and processes.
- Wrong Estimation of time and budget.
- Failure to manage scope described in project.
- Over micro managing of projects like police and enforcing the pressure in order to achieve the tasks.
- Daily or weekly meets amongst team to update and understand the progress. Not following the Processes.
- These are few of the mistakes that may result in delays in project delivery and there by losing the project.
Risk based testing starts with accessing risks related to complexity of logic, business criticality, defect prone areas in application, frequency of use of sensitive computation of application features. This involves priority of testing those areas of an software that involve critical features and functionalities that are likely to fail. Such type of testing involves experienced testers that have understanding of possible risks involved in mission critical applications.
Positive impact of risk based testing are opportunity to learn and improve business sustainability when you test application based on the risks involved negative impact of risk based testing are threat of customer dissatisfaction, impact of overall project cost due to detailed testing, bad or negative user experience, and possible loss of customers.
Decision table testing are used to validate system behavior with different input combinations.
Best Example of such tests can be login to the application where there are two input values, namely username and password and possible output can either be an error with not allowing to enter in application or allowed to enter the welcome page.
scenario 1 – username and password both can be wrong, resulting in error
scenario 2 – username can be correct, but password could be wrong, resulting in error
Scenario 3 – username can be wrong, but password could be right, resulting in error.
Scenario 4 – username and password both can be right and valid, allowing user to the welcome page.
Test scenario can be a description of test objective, tester can accomplish by testing an application in multiple ways to ensure that the scenario has been covered with satisfaction.
Test case is summary of test scenario with steps or procedure to carry out with test data to the application in order to validate that the application behave s as expected, or reproducing the defect by following the steps written in test case, there by validate that the actual result deviate from expected result.
Test script is steps in order to mimic test case to validate applicatio n’s behavior as expected or behaves differently to locate defect.
Defect triage is process of analyzing defect priority based on factors such as severity, risk, and time required to fix /resolve the defect. During defect triage meet, stack holders discuss and decide the priority of fixing the defects.
Software complexity – making developer difficult to understand requirement, or how to design the desiredoutput.
Miscommunication between product team and customer in knowing the exact requirement.
Programming errors during runtime or compile time of code base during integration process.
Timeline pressure that limits unit testing of all possible scenarios on design codes or programs.
Change in requirements by customer that can introduce defect in already running application code.
Error Guessing – It is a test case design technique in which testers have to imagine the defects that might occur and write test cases to represent them.
Error Seeding – It is the process of adding known bugs in a program for tracking the rate of detection & removal. It also helps to estimate the number of faults remaining in the program.
In some situations, reporting failures can be a delicate process. Perhaps a deve loper spent a lot of time on some code which does not exactly meet specifications. QA engineers need to be able to stand up for what they know is right.
The correct Answer is NO. All test cases need to be run, and making assumptions frequently leads to issues down the road, because as a Software quality tester it is your duty to cover all the scenarios for the application for test coverage. It may happen that in case some area of test uncovered may contain error at client side, and you can fall on your face by not testing that area.
The meaning of validation is to confirm if application or system designed is in compliance with the client’s requirements and its feature functions as desired and thereby meets goals and needs of end user. In short it is to verify the software build is right product.
The meaning of verification is to confirm that the designed product delivers and satisfies all the functionalities expected to fulfill as expected by end user. In short it is to test whether the product build is right (functions as expected)?
Software testing activities can be stopped based on following factors – How many Test case execution completed and bugs occurred fixed during the regression testing Based on the Testing deadline decided in test plan by project manager Mean Time between Failures (MTBF) rate if reduced and is within the acceptable rate.
Code Coverage Ratio can be calculated based on various tests like statement coverage, branch coverage etc.
Testing shows presence of defects – testing any software will uncover defects in it Early
Testing is essential and will help to detect defect in the initial stage of development.
Exhaustive testing is not possible – It is not possible to check each and every condition and criteria of application.
Testing is context Dependent – Different domains are tested differently, thus testing is purely based on the context of the domain or application.
Defect clustering – 80% of the problems are found in 20% of the modules.
Pesticide paradox – the set of test cases needs to be regularly reviewed and revised.
Absence of Error is fallacy as it will be impossible to imagine software without a defect.
Defect Density is number of confirmed defects identified in software/module during a development period divided by the size of the software. It is calculated as defect count/size of the release, where size of release is total line of code in release.
e.g. if module1 has 25 bugs, module2 has 15 bugs, and module3 has 50 bugs, total number of code per modules are module1 has 1250 LOC (lines of code), module2 has 2575 LOC , and module3 has 7500 LOC, then Total bugs = 25+15+50 = 90, and size = 1250+2575+7500 = 11325, Defect density will be = 90/11325 = 0.00794 defects/loc = 7.94 defects/Kloc.
Age of Defect is the difference of time from date when defect was detected till the date defect was fixed or a current date if defect is still open (not resolv ed).
The Design software gets stuck or hangs often when enter key have been pressed to review the final draft. This is defect of high priority and high severity and should be resolved and corrected as such product cannot be shipped to client.
If a Company name is misspelled on the home page of web portal, is an Example of high priority to be fixed as it may impact company reputation or may represent as fake product with misspel led company name. However other functionality in the web portal will function perfectly.
A printer printing multiple copies instead of single copy has a high severity as the customer will experience wastage, due to printing task still pending. This can be fixed in next release of the product.
The Example of Low priority and low severity can be Spelling, Grammatical, punctuation marks not properly placed, and such mistakes in product labels.
Interviewer wants to know, how do you react real time scenario when there is a de livery and acceptance testing is on the way, what tests will you take on priority? The Answer to this question will depend on how did you work and perform under pressure environment. The most critical feature that was not working and have been send with a defect, It is mandatory to check if the critical and major bugs have been resolved or not, The regression tests should be carried out and integration tests that validates feature, end to end testing should be carried out. Based on the test results, we can decide to release the build or not.
Native application refers to the development of a mobile application for a single platform only. The application is built using computer programming languages and tools that are explicit to a single platform. For example, you can develop a native Android application using Java or Kotlin and select Swift and Objective-C for iOS applications.
Native mobile apps don’t run in the browser, unlike websites and web applications. You’ll need to download them from specific app stores like the Apple App Store and Google Play. Once installed, you can easily access any application just by tapping its icon on your device screen.
Benefits :
o Native Apps live on the device and are accessed through icons on the device home screen.
o They can take full advantage of all the device features — they can use the camera, the GPS, the accelerometer, the compass, the list of contacts, and so on. They can also incorporate gestures (either standard operatingsystem gestures or new, and app-defined gestures).
o Native apps can use the device’s notification system and can work offline.
o Publishers can make use of push-notifications, alerting users every time a new piece of content is published or when their attention is required.
o Native Apps maintain UI design of each operating system, thus they offer the best user experience. For example, a Native App can have a left-aligned header in Android and a center-aligned header in iOS.
o Redistribution is easy, as it is found in app store.
Disadvantages :
o High cost for building the app : Native apps developed for one platform will not run on another platform. An App built for Android will not run on iOS. We need to build a different App altogether for iOS. Because of this reason, we need to maintain multiple versions of the App.
o Even though you might publish native Apps, you’ll want to keep the mobile website well maintained, as mobile brings more traffic. So maintenance is higher.
A hybrid app is one that is written with the same technology used for websites and mobile web implementations, and that is hosted or runs inside a native container on a mobile device.
Benefits :
o Developing a Hybrid App is cheaper than developing a Native App. It can be built for cross-platforms, i.e., reduced cost for App development.
o Maintenance is simple, as there are not many versions to be maintained.
o It can take advantage of a few features available in the device.
o It can be found in the App Store, which makes the distribution easy.
o It has a browser embedded within the app only.
Disadvantages :
o Graphics are less accustomed with the operating system as compared to Native Apps.
o Hybrid Apps are slower than Native Apps.
Web apps are not real applications; they are actually websites that open in your smartphone with the help of a web browser. Mobile websites have the broadest audience of all the primary types of applications.
Benefits :
o Easy access.
o Easy Development: Developing responsive design and restructuring the content to be properly displayed on a smaller screen/hardware will make any desktop website mobile friendly.
o Easy update: Just update in one location and all the users automatically have access to the latest version of the site.
o No installation required, as compared to native or hybrid app.
Disadvantages :
o Mobile websites cannot use some of the features. For example, access to the file system and local resources isn’t available in websites.
o Many existing websites don’t support offline capabilities.
o Users won’t have the app’s icon on their home screen as a constant reminder. The website needs to be opened in a web browser only.
o While native and hybrid apps appear on the App Store and Google Play, web apps won’t. So redistribution is not that sensible.
By testing on virtual machines, developers and testers can monitor how the software is performing on a specific device. Compared to real device testing, virtual testing mimics real devices and creates a virtual mobile device on a computer. The two types of programs used for virtual testing devices are emulators and simulators. Even though these terms are used interchangeably, each type comes with different capabilities and limitations.
What are Emulators?
Emulation is the process of enabling a computer system (the host) to mimic the hardware and software features of another target device (the guest). Emulators are essentially used as “substitutes”, which replaces the original device for real use.
- Emulator’s Capabilities: The emulator provides virtual device instances with near-native capabilities and extended controls to adjust the target/mobile device’s physical sensors, battery state, geolocation, and more.
- Emulator’s Limitations: In most cases, the near-native capabilities of an emulator include significant performance overhead due to binary translation. For Android apps and website testing, virtual mobile device emulators can be unreliable since they run slower than real Android devices. Because emulators cannot fully mimic real-world conditions, the testing results won’t be accurate for final releases.
What are Simulators?
Simulation is the process of modeling an environment to mimic the behavior and configuration of another target device. Compared to emulation, a simulator is used for “analysis and study”. By using a simulator, you create a virtual environment that mimics the target device from the real world. Ultimately, the simulation process shows you how the device would work in the real environment. However, a simulator doesn’t exactly follow the activity of the real environment.
- Simulator’s Capabilities: An iOS simulator sits on top of your operating system and mimics the iOS by running your app inside it. You can view this simulation in an iPhone or iPad window. Machine-language translation isn’t involved, so the iOS simulator is faster than the Android emulator.
- Simulator’s Limitations: Unfortunately, the iOS simulator can only be used on a macOS platform. This is because the simulator relies on Apple’s native Cocoa API to handle the GUI, runtime, and more. Compared to Android emulators, simulators cannot mimic battery states or cellular interrupts as well.
Functional Testing :-
Functional testing is the most basic test for any application to ensure that it is working as per the defined requirements.
Compatibility Testing :-
The purpose of a mobile app compatibility test, is to ensure an app’s key functions behave as expected on a specific device, platform and OS version.
Localization Testing :-
Nowadays, most of the apps are designed for global use and it is very important to care about regional trails like languages, time zones, etc.
Laboratory Testing :-
Laboratory testing, usually carried out by network carriers, is done by simulating the complete wireless network. This test is performed to find out any glitches when a mobile application uses voice and/or data connection to perform some functions.
Performance Testing :-
Mobile performance test covers client application performance, server performance, and network performance.
Stress Testing :-
Stress testing is a must to find exceptions, hangs, and deadlocks that may go unnoticed during functional and user interface testing.
Security Testing :-
Vulnerabilities to hacking, authentication, and authorization policies, data security, session management and other security standards should be verified as a part of mobile app security testing. Applications should encrypt user name and passwords when authenticating the user over a network.
One way to test security related scenarios is to route your mobile’s data through a proxy server like OWASP Zed Attack Proxy and look for vulnerabilities.
Memory Leakage Testing :-
Mobile devices have very limited memory as compared to other computers, and mobile operating systems have a default behavior to terminate applications that are using excessive memory and causing a poor user experience.
Memory testing is exceptionally important for mobile applications to ensure that each application maintains optimized memory usage throughout the user journey. It is recommended that we conduct memory testing on the actual target device, since the system architecture is different from an emulator to an actual device.
Power Consumption Testing :-
There are several types of batteries used in different mobile devices (i.e. nickel cadmium/lithium ion/ Nickel metal hybrid). While we focus on power consumption testing, we are required to measure the state of the battery at each activity level. It will give us a better understanding of power consumption by an individual application.
Power Consumption test can be done manually; also there are some free tools available in the market such as Trepn Profiler, Power Tutor, and Nokia Energy Profiler. These are applications which can display the real-time power consumption on a smartphone or tablet.
Interrupt Testing :-
An application, while functioning, may face several interruptions like incoming calls or network coverage outage and recovery. This can again be distinguished for:
Incoming and Outgoing SMS and MMS
Incoming and Outgoing calls
Incoming Notifications
Battery Removal
Cable Insertion and Removal for data transfer
Usability Testing :-
Usability testing evaluates the application based on the following three criteria for the target audience:
Efficiency: The accuracy and completeness with which specified users can achieve specified goals in a particular environment.
Effectiveness: The resources expended in relation to the accuracy and completeness of goals achieved.
Satisfaction: The comfort and acceptability of the work system to its users and other people affected by its use.
Installation Testing :-
Installation testing verifies that the installation process goes smoothly without the user having to face any difficulty.
Uninstallation Testing :-
The basics of uninstallation testing can be summarized in one line as “Uninstallation should sweep out data related to the App in just one go”.
Updates Testing :-
We need to be very much cautious about mobile app updates. People frequently complain about applications not working satisfactorily after an update. So it is very important that under the update testing, we qualify that the App will work as it was working previously.
In a nutshell, it should not break anything. Mobile application updates can take place in two ways – Automatic update and Manual update.
API stands for Application Programming Interface. It is a software interface that enables two applications to communicate and exchange data with each other. It is a set of functions that can be executed by another software program.
Let us now understand how an API works. When you use an application on your smartphone, the application connects to the Internet. It sends data to a server. The server will retrieve that data, interpret it, and perform the required actions. Then it sends it back to your phone. The application interprets that data and provides you with the information in a readable way without exposing the internal details.
API is a part of integration testing to check whether the API meets expectations in terms of functionality, reliability, performance, and security of applications.
Unit testing: To test the functionality of individual operation
Functional testing: To test the functionality of broader scenarios by using a block of unit test results tested together
Load testing: To test the functionality and performance under load
Runtime/Error Detection: To monitor an application to identify problems such as exceptions and resource leaks
Security testing: To ensure that the implementation of the API is secure from external threats
UI testing: It is performed as part of end-to-end integration tests to make sure every aspect of the user interface functions as expected
Interoperability and WS Compliance testing: Interoperability and WS Compliance Testing is a type of testing that applies to SOAP APIs. Interoperability between SOAP APIs is checked by ensuring conformance to the Web Services Interoperability profiles. WS-* compliance is tested to ensure standards such as WS-Addressing, WS-Discovery, WS-Federation, WS-Policy, WS-Security, and WS-Trust are properly implemented and utilized
Penetration testing: To find vulnerabilities of an application from attackers
Fuzz testing: To test the API by forcibly input into the system in order to attempt a forced crash
API protocols facilitate a standardized exchange of information. They provide a collection of defined rules that specifies the accepted data types and commands. Below are some of the common protocols used in API testing:
- HTTP
- JSON-RPC
- REST
- SOAP
- JMS
- UDDI
- XML-RPC
Some of the popular API testing tools for 2022 are:
- SoapUI
- PostMan
- Karate DSL
- Rest Assured
- Alertsite API monitoring
- Apigee
- Assertible
1. Test for Core Functionality
API testing allows accessing the application without the UI (User Interface). The core functionality of the application is tested before the GUI tests. It helps in identifying the minor issue which can become bigger during the GUI testing.
2. Time Effective
API Testing does not need GUI to be ready. It can be performed earlier in the development cycle. API testing is less time-consuming than GUI testing. API tests offer test results quickly. They significantly accelerate development workflows. This helps in speeding up the feedback loop and identifying issues faster.
3. Reduced Cost
API testing requires less code and provides better and faster test coverage compare to GUI test automation. You can identify issues at an early stage. It is easier and comparatively inexpensive to fix the issue at the early stages. This reduces the cost of the testing project.
4. Language-Independent
The data in API testing is exchanged data using XML or JSON. These transfer modes are completely language-independent. It means that you can select any core language when using automated testing services for the application.
5. Easy Integration with GUI
API testing allows highly integrable tests. This is useful if you plan to perform functional GUI tests after API testing. For example, simple integration will allow for the creation of new users within the application before the start of a GUI test.
SOAP stands for Simple Object Access Protocol. It is an XML-based protocol for exchanging information between computers. It is a communication protocol for communicating through the Internet. SOAP is platform-independent and language-independent and can be used for broadcasting a message.
REST stands for Representational State Transfer. REST API is an API that conforms to the principles of the REST architectural style. It allows for interaction with RESTful web services. This is why REST APIs are sometimes referred to as RESTful APIs.
| It is an architectural style that follows six constraints – Uniform Interface, Client-Server, Layered System, Stateless, Cacheable, Code on Demand. REST is not restricted to XML. It permits different data formats such as Plain text, XML, HTML, and JSON. It requires less bandwidth. |
All Web services are APIs but not all APIs are Web services.
Web services might not contain all the specifications and cannot perform all the tasks that APIs would perform.
A Web service uses only three styles of use: SOAP, REST and XML-RPC for communication whereas API may be exposed to in multiple ways.
A Web service always needs a network to operate while APIs don’t need a network for operation.
Test for Core Functionality: API testing provides access to the application without a user interface. The core and code-level of functionalities of the application will be tested and evaluated early before the GUI tests. This will help detect the minor issues which can become bigger during the GUI testing.
Time Effective: API testing usually is less time consuming than functional GUI testing. The web elements in GUI testing must be polled, which makes the testing process slower. Particularly, API test automation requires less code so it can provide better and faster test coverage compared to GUI test automation. These will result in the cost saving for the testing project.
Language-Independent: In API testing, data is exchanged using XML or JSON. These transfer modes are completely language-independent, allowing users to select any code language when adopting automation testing services for the project.
Easy Integration with GUI: API tests enable highly integrable tests, which is particularly useful if you want to perform functional GUI tests after API testing. For instance, simple integration would allow new user accounts to be created within the application before a GUI test started.
- Accuracy of data
- Schema validation
- HTTP status codes
- Data type, validations, order and completeness
- Authorization checks
- Implementation of response timeout
- Error codes in case API returns, and
- Non-functional testing like performance and security testing
API testing is now preferred over GUI testing and is considered as most suitable because:
It verifies all the functional paths of the system under test very effectively.
It provides the most stable interface.
It is easier to maintain and provides fast feedback.
A Web service is a web application that can communicate with other web-based applications over a network.
Web service implementation allows two web applications developed in different languages to interact with each other using a standardized medium like XML, SOAP, HTTP etc.
As web services are based on open standards like XML, HTTP so these are operating system independent.
Likewise, web services are programming language independent, a java application can consume a PHP web service.
Web services can be published over the internet to be consumed by other web applications.
The consumer of web service is loosely coupled with the web service, so the web service can update or change their underlying logic without affecting the consumer.
Client-Server – Client and server are separated by a uniform interface and are not concerned with each other’s internal logic
Stateless – Each client request is independent and contains all the necessary information required to get executed. No client data is saved at the server.
Cacheable – Client should have the ability to cache the responses
Layered System – A layered system having multiple layers wherein each layer communicates with adjacent layer only
Uniform Interface – A uniform interface design requires each component within the service to share a single and uniform architecture
Code on Demand – This constraint is optional. It extends client-side execution of code transfer of executable scripts like javascript from the server.
REST architecture treats any content as a resource, which can be either text files, HTML pages, images, videos or dynamic business information.
REST Server gives access to resources and modifies them, where each resource is identified by URIs/ global IDs.
REST uses different representations to define a resource like text, JSON, and XML. XML and JSON are the most popular representations of resources.
RESTful web services use the HTTP protocol as a medium of communication between the client and the server.
RESTful web services use the HTTP protocol as a communication tool between the client and the server. The technique that when the client sends a message in the form of an HTTP Request, the server sends back the HTTP reply is called Messaging. These messages comprise message data and metadata, that is, information on the message itself.
An HTTP request contains five key elements:
An action showing HTTP methods like GET, PUT, POST, DELETE.
Uniform Resource Identifier (URI), which is the identifier for the resource on the server.
HTTP Version, which indicates HTTP version, for example-HTTP v1.1.
Request Header, which carries metadata (as key-value pairs) for the HTTP Request message. Metadata could be a client (or browser) type, format supported by the client, format of a message body format, cache settings, and so on.
Request Body, which indicates the message content or resource representation.
GET is only used to request data from a specified resource. Get requests can be cached and bookmarked. It remains in the browser history and haS length restrictions. GET requests should never be used when dealing with sensitive data.
POST is used to send data to a server to create/update a resource. POST requests are never cached and bookmarked and do not remain in the browser history.
PUT replaces all current representations of the target resource with the request payload.
DELETE removes the specified resource.
OPTIONS is used to describe the communication options for the target resource.
HEAD asks for a response identical to that of a GET request, but without the response body.
PUT and POST operation are quite similar, except the terms of the result generated by them.
PUT operation is idempotent, so you can cache the response while the responses to POST operation are not cacheable, and if you retry the request N times, you will end up having N resources with N different URIs created on server.
GET /device-management/devices : Get all devices
POST /device-management/devices : Create a new device
GET /device-management/devices/{id} : Get the device information identified by “id”
PUT /device-management/devices/{id} : Update the device information identified by “id”
DELETE /device-management/devices/{id} : Delete device by “id”
The OPTIONS Method lists down all the operations of a web service supports. It creates read-only requests to the server.
URI stands for Uniform Resource Identifier. It is a string of characters designed for unambiguous identification of resources and extensibility via the URI scheme.
The purpose of a URI is to locate a resource(s) on the server hosting of the web service.
A URI’s format is :////.
The “payload” is the data you are interested in transporting. This is differentiated from the things that wrap the data for transport like the HTTP/S Request/Response headers, authentication, etc.
appends data to the service URL. But, its size shouldn’t exceed the maximum URL length. However, doesn’t have any such limit.
So, theoretically, a user can pass unlimited data as the payload to POST method. But, if we consider a real use case, then sending POST with large payload will consume more bandwidth. It’ll take more time and present performance challenges to your server. Hence, a user should take action accordingly.
Caching is just the practice of storing data in temporarily and retrieving data from a high-performance store (usually memory) either explicitly or implicitly.
When a caching mechanism is in place, it helps improve delivery speed by storing a copy of the asset you requested and later accessing the cached copy instead of the original.
Use the SOAP API to create, retrieve, update or delete records, like accounts, leads, and user-defined objects. With more than 20 different calls, you can also use the SOAP API to manage passwords, perform searches, etc. by using the SOAP API in any language that supports web services.
When using SOAP, users often see the firewall security mechanism as the biggest obstacle. This block all the ports leaving few like HTTP port 80 and the HTTP port used by SOAP that bypasses the firewall. The technical complaint against SOAP is that it mixes the specification for message transport with the specification for message structure.
It is a common XML document that contains the elements as a SOAP message
Envelope: It is an obligatory root element that translates the XML document and defines the beginning and end of the message.
Header: It is an optional item which contains information about the message being sent.
Body: It contains the XML data comprising the message being sent.
Fault: It provides the information on errors that occurred while during message processing.
- SOAP is both platform and language independent.
- SOAP separates the encoding and communications protocol from the runtime environment.
- Web service can retrieve or receive a SOAP user data from a remote service, and the source’s platform information is completely independent of each other.
- Everything can generate XML, from Perl scripts through C++ code to J2EE app servers.
- It uses XML to send and receive messages.
- It uses standard internet HTTP protocol.
- SOAP runs over HTTP; it eliminates firewall problems. When protocol HTTP is used as the protocol binding, an RPC call will be automatically assigned to an HTTP request, and the RPC response will be assigned to an HTTP reply.
- Compared to RMI, CORBA and DCOM, SOAP is very easy to use.
- SOAP acts as a protocol to move information in a distributed and decentralized environment.
- SOAP is independent of the transport protocol and can be used to coordinate different protocols.
- SOAP is typically significantly slower than other types of middleware standards, including CORBA, because SOAP uses a detailed XML format. A complete understanding of the performance limitations before building applications around SOAP is hence required.
- SOAP is usually limited to pooling and not to event notifications when HTTP is used for the transport. In addition, only one client can use the services of one server in typical situations.
- If HTTP is used as the transport protocol, firewall latency usually occurs since the firewall analyzes the HTTP transport. This is because HTTP is also leveraged for Web browsing, and so many firewalls do not understand the difference between using HTTP within a web browser and using HTTP within SOAP.
- SOAP has different support levels, depending on the supported programming language. For instance, SOAP supported in Python and PHP is not as powerful as it is in Java and .NET
Postman is a free HTTP client-based software application and a collaboration platform for API development. It is mainly used to perform API testing. It is a very popular API client which facilitates developers and provides a platform to design, build, share, test, and document APIs. Postman supports testing of HTTP requests by utilizing GUI (Graphical User Interface), which later we can execute and validate the responses.
The Postman tool also facilitates us to send HTTP/s requests to a service and get their responses. We can ensure that the service is up and running by using this.
- It is free: Postman is free software that we can use for API testing. It is free to download and use for teams of any size.
- It is easy to use: Postman is an easy-to-use software tool. We can send HTTP requests of various types (such as GET, POST, PUT, PATCH, etc.). We have to download it, and we can send our first request in minutes. It also gives us the ability to save environments for future use.
- Community & Support: It has a huge community forum for customer support and extensive documentation.
- It is extensible: Postman facilitates us customizing it according to our needs with the Postman API.
- APIs Support: It facilitates us to make any API call (REST, SOAP, or plain HTTP) and easily inspect even the largest responses. It also helps manage the end-to-end lifecycle of the API – starting from design to mocking to testing and finally maintaining the APIs.
- Runtime Services: Postman provides Runtime Services that help us manage API collections, environments, work-spaces, and different examples.
- Integration: Postman facilitates us to easily integrate test suites into our preferred CI/CD tools and services, such as Jenkins with Newman (command-line collection runner).
- API Key
- Oauth 1.0
- Oauth 2.0
- Bearer Token
- Basic auth
- Digest auth
- Hawk Authentication
- AWS Signature
- NTLM Authentication
In Postman, a collection is used to group similar requests. It systematically arranges the requests into folders.
- Status/Response Code – These are response codes issued by a server to a client’s request. For example, 404 means Page Not Found, and 200 means Response is OK.
- HTTP Version – describes HTTP version, for example-HTTP v1.1.
- Response Header – Includes information for the HTTP response message. For example, Content-type, Content-length, date, status and server type.
- Response Body – It contains the data that was requested by a client to server.
- GET
- POST
- PUT
- PATCH
- COPY
- DELETE
- HEAD
- OPTIONS
- LINK
- UNLINK
- PURGE
- LOCK
- UNLOCK
- PROPFIND
- VIEW
HTTP methods: It is a set of request methods used to perform needed action for a given resource (GET, PUT, POST, and DELETE).
Uniform Resource Identifier (URI): It is a kind of address that describes the resource.
HTTP Version: It specifies the version of the HTTP. For example HTTP v1.1
Request Headers: It specifies the content type and content length of the request. For example: Content-type: application/ JSON, Content-Length: 511
Payload: It is used to specify the Request Body that includes message content.
Postman accepts authorization credentials in Base64 encoding only. This is inbuilt in Postman, or else you can refer to a third-party website to convert the credentials in base64. The Base64 authorization credentials are generally used because they transmit the data into a textual form and send it in an easier form, such as HTML form data.
In Postman, the term environment is a set of key-value pairs. You can create multiple environments in Postman and switch among them quickly by pressing a button. There are 2 types of environment, global and local.
In Postman, if 2 variables have the same name (one being local, the other global), then the higher priority is of the local variable. The local variable will overwrite the global variable.
The Postman monitor is used for running collections. Collections run till the specified time defined by the users. It requires the users to be logged in, and the users share the Monitor reports over an email on a daily or monthly basis.
A workspace is a collaborative environment for users to develop and test APIs. In the same way, a team workspace is a workspace that is shared by the whole team working on the same collections of requests. Usually, it is time-consuming and hard to share the collections through external drives or other sharing; the team workspace synchronizes and collaborates all the team’s work in one place.
Query Params or Query Parameters are used for sorting or filtering the resources. On the other hand, Path Variables are used for identifying specific resources.
Path params are part of the url where as query parameters are added after the ? mark symbol and separated from other query parameters by & symbol.
PathParam example
GET http://base-url/students/{roll-number}
QueryParam example
GET http://base-url/students?grade=10
The Postman Collection runner is used to perform Data-driven testing. It runs a group of API requests for multiple iterations with different data sets.
In Postman, Basic Auth is an authorization technique provided for HTTP user agents like web browsers to enter username and password. After entering the username and password, it gets associated with the request.
Yes, we can import local variables in Postman Monitors, but it is not allowed to import global variables in Postman Monitors.
- Postman cannot process 1000+ API requests.
- In the case of huge projects, it isn’t easy to manage the collections and requests.
- Postman is not suitable for managing the workspace in the form of code. This is because there would be a lot of code duplication for dynamic API requests.
In POST methods, the binary form is designed to send data easily in a format it is impossible to enter data manually. This is mainly used when sending large files like images, CSV files, etc., in the POST request. The binary representation is one of the easiest representations used for sending complex data with the request.
The Postman cloud is a common repository of companies to access Postman collections. That is why we use it when we are working in a company. We can save the work instantly in the Postman cloud after logging in. It facilitates the team members to access data/collections from anywhere.
The digest auth or digest authorization is one of the authorization techniques provided by Postman. This technique lets the clients send the request first to the API and get responses from the server, including a number that can be used only once a real value and 401 unauthorized responses. After that, the client can send back an encrypted data array with both username and password and the data received from the server earlier. Now, the server uses this data to generate an encrypted data string and compares this with what was sent for authenticating the request.
The status code 201 means created when you have successfully created a resource using POST or PUT request. It returns a link to a newly created resource using the location header.
The status code 304 means NOT MODIFIED. It is used to minimize the network bandwidth usage in conditional GET requests. The response body should be empty. Headers should have a date, and location, etc.
In Postman, the 301 status code is used to specify that the page has been permanently redirected from one website page to another. It tells the search engine that the old page is outdated, and the search engine has to index the new page URL.
Global Variables: Global variables allow data access between different collections, requests, and scripts. They are available throughout the workspace.
Local Variables: Local variables are the temporary variables that can be accessed only within the scope of requests scripts. Depending on the requirements, these variables are either scoped to a single request or single collection. These variables are not available once the script execution is completed.
Environment Variables: The Environment variables allow us to tailor the requests about different development environments such as local testing, stage testing, or prod testing.
Collection Variables: The Collection variables are independent of the environment and scoped to be available for all the requests present within the collection.
Data Variables: The Data variables come from external JSON or CSV files and define the datasets required to run the collection in Collection Runner or Newman
We can use the different forms of data content types as defined by the W3C committee. They’ve defined multiple formats for sending the data over the Network Layer. These include form-data, x-www-form-urlencoded, and raw data. By default, we can send data in simple text/ASCII format by using the x-www-form-urlencoded format.
However, using the x-www-form-urlencoded data type has a data limit. As such, we can use form-data for sending large binary or non-ASCII text to the server.
The raw data type sends any plain text or JSON to the server, as the name suggests. It supports multiple content types, and Postman will send the raw data without any modifications, unlike with the other data types.
We can use the raw data type to send any type of data in the request body. This also includes sending the Javascript functions that could be executed on the server side. We can send the scripts under the Javascript option. The raw data type also supports markup languages, such as HTML and XML. This can be helpful when there’s no logic at the front end and we need to consume the whole HTML/XML page.
Yes, it is possible to reuse the authentication token for multiple requests. We can achieve it by creating a collection and adding all the requests having the same authentication token to that collection and then assigning the auth token to the same collection. We can apply it to the individual requests by selecting the “Inherit auth from parent” option in the Authorization tab.
The pre-request scripts at the compilation level are executed first in a collection run.
We can access a Postman variable by entering the variable name as {{var}}.
We can use the Newman tool to run Postman collections in Jenkins.
200 (OK): Status code 200 specifies that the request was correct.
201 (Created): Status code 201 specifies that the value wrapped with the request has been created in the database. Here, it is obvious that the request was correct.
204 (No Content): Status code 204 specifies that the request was correct and received, but there is no content to send. It means there is no response to send to the client by the server.
400 (Bad Request): Status code 400 specifies a bad request. A bad request means that the syntax of the request was incorrect. It appears when we have sent the wrong parameters along with the request URL or in the request’s body.
401 (Unauthorized request): Status code 401 specifies an unauthorized request. An unauthorized request is a request for which you are not authorized. This status code appears when we are not authorized to access the server or enter the wrong credentials.
404 (Not Found): Status code 404 specifies that the server was connected, but it could not find what was requested. It simply means “request not found”. This status code normally appears when we request a web page not available on the server.
Postman provides a space known as Scratch Pad. The Scratch Pad facilitates us to work without being connected to Postman servers and also provides the flexibility to utilize some of the features of Postman offline. These features include collection creation, creating requests, and the ability to send requests. The Scratch Pads are stored locally, and once logged in; the work is saved into the workspace.
We can iterate a request 100 times in Postman using Collection Runner.
Some examples of the JS libraries available in Postman are Lodash, Moment, GUID, etc.
GUID is an acronym that stands for Global Unique Identifier. It is a set of hexadecimal digits separated by hyphens and solves the purpose of uniqueness.
In Postman, it is used to generate and send a random value to APIs.
Example:
{
“id”: “{{$guid}}”,
}
const customerId = Math.floor((Math.random() * 100 + 1));
pm.globals.set(“customerId”, customerId);
Java Runtime Environment contains Java Virtual machine, libraries and other components to run applets and applications written in Java.
JVM + libraries+other components= JRE
Java virtual machine helps run java bytecodes. when .java file are compiled using javac compiler into .class file. These .class file contain bytecode understood by Java virtual machine.
Java Development Kit (JDK) contains JRE and compile rs and debuggers for developing applets and applications.
JVM help run java byte codes created by compiling .java files into .class files.
JRE contains JVM (Java Virtual Machine), libraries and other components t o run Java applets and applications.
JDK contains JRE, compilers and debugger (development environment for applications using Java programming language).
(Java Runtime Environment) JRE contains Java Virtual Machine (JVM) + Java packages (util, math, lang, awt, etc) + runtime libraries You need to install JRE on your machine in order to run Java applications or applets.
Java compiler Javac converts .java file into .class files which contain bytecode, (Java Virtual Machine) JVM converts bytecode into machine language. JVM is platform dependent, there are different JVM for different OS, Bytecode converted into machine language for particular machine, executes depending on its kernel. Without JVM you cannot run Java Applications.
Both compilers and interpreters are used to convert program written in high level language into machine code understood by computers.
Interpreter converts program one statement at a time, takes less time in analyzing source code, slower than compiler, there is no intermediate object formed, hence memory efficient.
Compilers scans entire program and then converts it as a whole into machine language, takes more time analyzing source code, however it is faster than interpreter, generates intermediate object code hence takes more memory.
Programming languages like JavaScript, Python and Ruby use interpreters.
Programming languages like C, C++ and Java use compilers.
Java doesn’t support multiple inheritance in classes because of “Diamond Problem”.
However multiple inheritance is supported in interfaces. An interface can extend multiple interfaces because they just declare the methods and implementation will be present in the implementing class. So there is no issue of diamond problem with interfaces.
Java is not said to be pure object oriented because it support primitive types such as int, byte, short, long etc. I believe it brings simplicity to the language while writing our code.
Obviously java could have wrapper objects for the primitive types but just for the representation, they would not have provided any benefit.
As we know, for all the primitive types we have wrapper classes such as Integer, Long etc that provides some additional methods.
PATH is an environment variable used by operating system to locate the executables. That’s why when we install Java or want any executable to be found by OS, we need to add the directory location in the PATH variable.
Classpath is specific to java and used by java executables to locate class files. We can provide the classpath location while running java application and it can be a directory, ZIP files, JAR files etc.
main() method is the entry point of any standalone java application. The syntax of main method is public static void main(String args[]).
main method is public and static so that java can access it without initializing the class. The input parameter is an array of String through which we can pass runtime arguments to the java program.
When we have more than one method with same name in a single class but the argument are different, then it is called as method overloading.
Overriding concept comes in picture with inheritance when we have two methods with same signature, one in parent class and another in child class. We can use @Override annotation in the child class overridden method to make sure if parent class method is changed, so as child class.
Yes, we can have multiple methods with name “main” in a single class. However if we run the class, java runtime environment will look for main method with syntax as public static void main(String args[]).
We can’t have more than one public class in a single java source file. A single source file can have multiple classes that are not public.
Java package is the mechanism to organize the java classes by grouping them. The grouping logic can be based on functionality or modules based. A java class fully classified name contains package and class name. For example, java.lang.Object is the fully classified
name of Object class that is part of java.lang package.
java.lang package is imported by default and we don’t need to import any class from this package explicitly.
Java provides access control through public, private and protected access modifier keywords. When none of these are used, it’s called default access modifier.
A java class can only have public or default access modifier.
final keyword is used with Class to make sure no other class can extend it, for example String class is final and we can’t extend it.
We can use final keyword with methods to make sure child classes can’t override it.
final keyword can be used with variables to make sure that it can be assigned only once.
However the state of the variable can be changed, for example we can assign a final variable to an object only once but the object variables can change later on.
Java interface variables are by default final and static.
static keyword can be used with class level variables to make it global i.e all the objects will share the same variable.
static keyword can be used with methods also. A static method can access only static variables of class and invoke only static methods of the class.
finally block is used with try-catch to put the code that you want to get executed always, even if any exception is thrown by the try-catch block. finally block is mostly used to release resources created in the try block.
finalize() is a special method in Object class that we can override in our classes. This method get’s called by garbage collector when the object is getting garbage collected. This method is usually overridden to release system resources when object is garbage collected.
We can’t declare a top-level class as static however an inner class can be declared as static.
If inner class is declared as static, it’s called static nested class. Static nested class is same as any other top-level class and is nested for only packaging convenience.
If we have to use any static variable or method from other class, usually we import the class and then use the method/variable with class name.
import java.lang.Math;
//inside class
double test = Math.PI * 5;
We can do the same thing by importing the static method or variable only and then use it in the class as if it belongs to it.
import static java.lang.Math.PI;
//no need to refer class now
double test = PI * 5;
Use of static import can cause confusion, so it’s better to avoid it. Overuse of static import can make your program unreadable and unmaintainable.
Java 7 one of the improvement was multi-catch block where we can catch multiple exceptions in a single catch block. This makes are code shorter and cleaner when every catch block has similar code.
If a catch block handles multiple exception, you can separate them using a pipe (|) and in this case exception parameter (ex) is final, so you can’t change it
Java static block is the group of statements that gets executed when the class is loaded into memory by Java ClassLoader. It is used to initialize static variables of the class. Mostly it’s used to create static resources when class is loaded.
Interfaces are core part of java programming language and used a lot not only in JDK but also java design patterns, most of the frameworks and tools. Interfaces provide a way to achieve abstraction in java and used to define the contract for the subclasses to implement.
Interfaces are good for starting point to define Type and create top level hierarchy in our code. Since a java class can implements multiple interfaces, it’s better to use interfaces as super class in most of the cases.
Abstract classes are used in java to create a class with some default method implementation for subclasses. An abstract class can have abstract method without body and it can have methods with implementation also.
abstract keyword is used to create an abstract class. Abstract classes can’t be instantiated and mostly used to provide base for sub-classes to extend and implement the abstract methods and override or use the implemented methods in abstract class.
- abstract keyword is used to create abstract class whereas interface is the keyword for interfaces.
- Abstract classes can have method implementations whereas interfaces can’t.
- A class can extend only one abstract class but it can implement multiple interfaces.
- We can run abstract class if it has main() method whereas we can’t run an interface.
Interfaces don’t implement another interface, they extend it. Since interfaces can’t have method implementations, there is no issue of diamond problem. That’s why we have multiple inheritance in interfaces i.e an interface can extend multiple interfaces.
A marker interface is an empty interface without any method but used to force some functionality in implementing classes by Java. Some of the well known marker interfaces are Serializable and Cloneable.
Enum was introduced in Java 1.5 as a new type whose fields consists of fixed set of constants. For example, in Java we can create Direction as enum with fixed fields as EAST, WEST, NORTH, SOUTH.
enum is the keyword to create an enum type and similar to class. Enum constants are implicitly static and final.
Java Annotations provide information about the code and they have no direct effect on the code they annotate. Annotations are introduced in Java 5. Annotation is metadata about the program embedded in the program itself. It can be parsed by the annotation parsing tool or
by compiler. We can also specify annotation availability to either compile time only or till runtime also. Java Built-in annotations are @Override, @Deprecated and @SuppressWarnings.
Java ternary operator is the only conditional operator that takes three operands. It’s a one liner replacement for if-then-else statement and used a lot in java programming. We can use ternary operator if-else conditions or even switch conditions using nested ternary operators.
super keyword can be used to access super class method when you have overridden the method in the child class.
We can use super keyword to invoke super class constructor in child class constructor but in this case it should be the first statement in the constructor method.
We can use break statement to terminate for, while, or do-while loop. We can use break statement in switch statement to exit the switch case. You can see the example of break statement at java break. We can use break with label to terminate the nested loops.
The continue statement skips the current iteration of a for, while or do-while loop. We can use continue statement with label to skip the current iteration of outermost loop
this keyword provides reference to the current object and it’s mostly used to make sure that object variables are used, not the local variables having same name.
classTest
{
inta;
intb;
// Parameterized constructor
Test(inta, intb)
{
this.a = a;
this.b = b;
}
voiddisplay()
{
//Displaying value of variables a and b
System.out.println("a = "+ a + " b = "+ b);
}
publicstaticvoidmain(String[] args)
{
Test object = newTest(10, 20);
object.display();
}
}
No argument constructor of a class is known as default constructor. When we don’t define any constructor for the class, java compiler automatically creates the default no-args constructor for the class. If there are other constructors defined, then compiler won’t create
default constructor for us.
Yes, we can have try-finally statement and hence avoiding catch block.
Garbage Collection is the process of looking at heap memory, identifying which objects are in use and which are not, and deleting the unused objects. In Java, process of deallocating memory is handled automatically by the garbage collector.
We can run the garbage collector with code Runtime.getRuntime().gc() or use utility method System.gc().
Java System Class is one of the core classes. One of the easiest way to log information for debugging is System.out.print() method.
System class is final so that we can’t subclass and override it’s behavior through inheritance. System class doesn’t provide any public constructors, so we can’t instantiate this class and that’s why all of it’s methods are static.
Some of the utility methods of System class are for array copy, get current time, reading environment variables.
- Pass by value: The method parameter values are copied to another variable and then the copied object is passed to the method. The method uses the copy.
- Pass by reference: An alias or reference to the actual parameter is passed to the method. The method accesses the actual parameter.
Often, the confusion around these terms is a result of the concept of the object reference in Java. Technically, Java is always pass by value, because even though a variable might hold a reference to an object, that object reference is a value that represents the object’s location in memory. Object references are therefore passed by value.
Both reference data types and primitive data types are passed by value.
Heap memory is used by all the parts of the application whereas stack memory is used only by one thread of execution.
Whenever an object is created, it’s always stored in the Heap space and stack memory contains the reference to it.
Stack memory only contains local primitive variables and reference variables to objects in heap space.
Memory management in stack is done in LIFO manner whereas it’s more complex in Heap memory because it’s used globally.
String is a Class in java and defined in java.lang package. It’s not a primitive data type like int and long. String class represents character Strings. String is used in almost all the Java applications and there are some interesting facts we should know about String. String is
immutable and final in Java and JVM uses String Pool to store all the String objects.
Some other interesting things about String is the way we can instantiate a String object using double quotes and overloading of “+” operator for concatenation.
We can create String object using new operator like any normal java class or we can use double quotes to create a String object. There are several constructors available in String class to get String from char array, byte array, StringBuffer and StringBuilder.
String str = new String(“abc”);
String str1 = “abc”;
When we create a String using double quotes, JVM looks in the String pool to find if any other String is stored with same value. If found, it just returns the reference to that String object else it creates a new String object with given value and stores it in the String pool.
When we use new operator, JVM creates the String object but don’t store it into the String Pool. We can use intern() method to store the String object into String pool or return the reference if there is already a String with equal value present in the pool.
A String is said to be Palindrome if its value is same when reversed. For example “aba” is a Palindrome String.
String class doesn’t provide any method to reverse the String but StringBuffer and StringBuilder class has reverse method that we can use to check if String is palindrome or not.
private static boolean isPalindrome(String str) {
if (str == null)
return false;
StringBuilder strBuilder = new StringBuilder(str);
strBuilder.reverse();
return strBuilder.toString().equals(str);
}
We can use replaceAll method to replace all the occurance of a String with another String. The important point to note is that it accepts String as argument, so we will use Character class to create String and use it to replace all the characters with empty String.
private static String removeChar(String str, char c) {
if (str == null)
return null;
return str.replaceAll(Character.toString(c), “”);
}
We can use String class toUpperCase and toLowerCase methods to get the String in all upper case or lower case. These methods have a variant that accepts Locale argument and use that locale rules to convert String to upper or lower case.
Below are 5 ways to compare two Strings in Java:
- Using user-defined function : Define a function to compare values with following conditions :
- if (string1 > string2) it returns a positive value.
- if both the strings are equal lexicographically
i.e.(string1 == string2) it returns 0. - if (string1 < string2) it returns a negative value.
- Using String.equals()
- str1.equals(str2);
- Using String.equalsIgnoreCase()
- str2.equalsIgnoreCase(str1);
- Using Objects.equals() : Objects.equals(Object a, Object b)
- Objects.equals(string1, string2);
- Using String.compareTo()
- int str1.compareTo(String str2);
This is a tricky question because String is a sequence of characters, so we can’t convert it to a single character. We can use use charAt method to get the character at given index or we can use toCharArray() method to convert String to character array.
import java.util.Arrays;
public class StringChar {
public static void main(String[] args) {
String st = "This is great";
char[] chars = st.toCharArray();
System.out.println(Arrays.toString(chars));
}}
Output
[T, h, i, s, , i, s, , g, r, e, a, t]
We can use String getBytes() method to convert String to byte array and we can use String constructor new String(byte[] arr) to convert byte array to String.
package com.javaprogramto.arrays.bytearray;
public class StrintToByteArrayExample {
public static void main(String[] args) {
// creating string
String string = "javaprogrmto.com";
// string to byte array
byte[] array1 = string.getBytes();
// printing byte array
for (int i = 0; i < array1.length; i++) {
System.out.print(" " + array1[i]);
}
}}
Output:
106 97 118 97 112 114 111 103 114 109 116 111 46 99 111 109
This is a tricky question used to check your knowledge of current Java developments. Java 7 extended the capability of switch case to use Strings also, earlier java versions doesn’t support this.
If you are implementing conditional flow for Strings, you can use if-else conditions and you can use switch case if you are using Java 7 or higher versions.
public class Demo {
public static void main(String[] args) {
String department = “AKD05”;
switch(department) {
case “AKD01”:
System.out.println(“Finance”);
break;
case “AKD02”:
System.out.println(“Sales”);
break;
case “AKD03”:
System.out.println(“Production”);
break;
case “AKD04”:
System.out.println(“Marketing”);
break;
case “AKD05”:
System.out.println(“Operations”);
break;
default:
System.out.println(“None!”);
}
}
}
Output
Operations
// Java program to print all the permutations
// of the given string
public class GFG {
// Function to print all the permutations of str
static void printPermutn(String str, String ans)
{
// If string is empty
if (str.length() == 0) {
System.out.print(ans + " ");
return;
}
for (int i = 0; i < str.length(); i++) {
// ith character of str
char ch = str.charAt(i);
// Rest of the string after excluding
// the ith character
String ros = str.substring(0, i) +
str.substring(i + 1);
// Recursive call
printPermutn(ros, ans + ch);
}
}
// Driver code
public static void main(String[] args)
{
String s = "abb";
printPermutn(s, "");
}}
Output
abb abb bab bba bab bba
// program to check if the string is palindrome or not
function checkPalindrome(string) {
// find the length of a string
const len = string.length;
// loop through half of the string
for (let i = 0; i < len / 2; i++) {
// check if first and last string are same
if (string[i] !== string[len - 1 - i]) {
return 'It is not a palindrome';
}
}
return 'It is a palindrome';
}
// take input
const string = prompt('Enter a string: ');
// call the function
const value = checkPalindrome(string);
console.log(value);anana radar
Output
String is immutable and final in java, so whenever we do String manipulation, it creates a new String. String manipulations are resource consuming, so java provides two utility classes for String manipulations – StringBuffer and StringBuilder.
StringBuffer and StringBuilder are mutable classes. StringBuffer operations are threadsafe and synchronized where StringBuilder operations are not thread-safe. So when multiple threads are working on same String, we should use StringBuffer but in single threaded environment we should use StringBuilder.
StringBuilder performance is fast than StringBuffer because of no overhead of synchronization.
- There are several benefits of String because it’s immutable and final. String Pool is possible because String is immutable in java.
- It increases security because any hacker can’t change its value and it’s used for storing sensitive information such as database username, password etc.
- Since String is immutable, it’s safe to use in multi-threading and we don’t need any synchronization.
- Strings are used in java classloader and immutability provides security that correct class is getting loaded by Classloader.
// Java program to demonstrate working of split(regex, limit) with small limit.
publicclassGFG {
// Main driver method
publicstaticvoidmain(String args[])
{
// Custom input string
String str = "geekss@for@geekss";
String[] arrOfStr = str.split("@", 2);
for(String a : arrOfStr)
System.out.println(a);
}
}
String is immutable in java and stored in String pool. Once it’s created it stays in the pool until unless garbage collected, so even though we are done with password it’s available in memory for longer duration and there is no way to avoid it. It’s a security risk because anyone having access to memory dump can find the password as clear text.
If we use char array to store password, we can set it to blank once we are done with it. So we can control for how long it’s available in memory that avoids the security threat with String.
There are two ways to check if two Strings are equal or not – using “==” operator or using equals method. When we use “==” operator, it checks for value of String as well as reference but in our programming, most of the time we are checking equality of String for value only. So we should use equals method to check if two Strings are equal or not.
There is another function equalsIgnoreCase that we can use to ignore case.
String s1 = “abc”;
String s2 = “abc”;
String s3= new String(“abc”);
System.out.println(“s1 == s2 ? “+(s1==s2)); //true
System.out.println(“s1 == s3 ? “+(s1==s3)); //false
System.out.println(“s1 equals s3 ? “+(s1.equals(s3))); //true
As the name suggests, String Pool is a pool of Strings stored in Java heap memory. We know that String is special class in java and we can create String object using new operator as well as providing values in double quotes.
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String
object is returned.
This method always return a String that has the same contents as this string, but is guaranteed to be from a pool of unique strings.
Strings are immutable, so we can’t change its value in program. Hence it’s thread-safe and can be safely used in multi-threaded environment.
Since String is immutable, its hashcode is cached at the time of creation and it doesn’t need to be calculated again. This makes it a great candidate for key in a Map and its processing is fast than other HashMap key objects. This is why String is mostly used Object as
HashMap keys.
Collection is the root of the collection hierarchy. A collection represents a group of objects known as its elements. The Java platform doesn’t provide any direct implementations of this interface.
Set is a collection that cannot contain duplicate elements. This interface models the mathematical set abstraction and is used to represent sets, such as the deck of cards.
List is an ordered collection and can contain duplicate elements. You can access any element from its index. List is more like array with dynamic length.
A Map is an object that maps keys to values. A map cannot contain duplicate keys: Each key can map to at most one value.
In Java, an Iterator is one of the Java cursors. Java Iterator is an interface that is practiced in order to iterate over a collection of Java object components entirety one by one.
The Java Iterator is also known as the universal cursor of Java as it is appropriate for all the classes of the Collection framework. The Java Iterator also helps in the operations like READ and REMOVE.
Java Iterator Methods
The following figure perfectly displays the class diagram of the Java Iterator interface. It contains a total of four methods that are:
hasNext()
next()
remove()
forEachRemaining()
import java.io.*;
import java.util.*;
public class JavaIteratorExample {
public static void main(String[] args)
{
ArrayList cityNames = new ArrayList();
cityNames.add(“Delhi”);
cityNames.add(“Mumbai”);
cityNames.add(“Kolkata”);
cityNames.add(“Chandigarh”);
cityNames.add(“Noida”);
// Iterator to iterate the cityNames
Iterator iterator = cityNames.iterator();
System.out.println(“CityNames elements : “);
while (iterator.hasNext())
System.out.print(iterator.next() + ” “);
System.out.println();
}
}
Enumeration is twice as fast as Iterator and uses very less memory. Enumeration is very basic and fits to basic needs. But Iterator is much safer as compared to Enumeration because it always denies other threads to modify the collection object which is being iterated by it.
Iterator takes the place of Enumeration in the Java Collections Framework. Iterators allow the caller to remove elements from the underlying collection that is not possible with Enumeration. Iterator method names have been improved to make its functionality clear.
- We can use Iterator to traverse Set and List collections whereas ListIterator can be used with Lists only.
- Iterator can traverse in forward direction only whereas ListIterator can be used to traverse in both the directions.
- ListIterator inherits from Iterator interface and comes with extra functionalities like adding an element, replacing an element, getting index position for previous and next elements.
HashMap and Hashtable both implements Map interface and looks similar, however there are following difference between HashMap and Hashtable.
- HashMap allows null key and values whereas Hashtable doesn’t allow null key andvalues.
- Hashtable is synchronized but HashMap is not synchronized. So HashMap is better for single threaded environment, Hashtable is suitable for multi-threaded environment.
- LinkedHashMap was introduced in Java 1.4 as a subclass of HashMap, so incase you want iteration order, you can easily switch from HashMap to LinkedHashMap but that is not the case with Hashtable whose iteration order is unpredictable.
- HashMap provides Set of keys to iterate and hence it’s fail-fast but Hashtable provides Enumeration of keys that doesn’t support this feature.
- Hashtable is considered to be legacy class and if you are looking for modifications of Map while iterating, you should use ConcurrentHashMap.
For inserting, deleting, and locating elements in a Map, the HashMap offers the best alternative. If, however, you need to traverse the keys in a sorted order, then TreeMap is your better alternative. Depending upon the size of your collection, it may be faster to add elements to a HashMap, then convert the map to a TreeMap for sorted key traversal.
ArrayList and Vector are similar classes in many ways.
- Both are index based and backed up by an array internally.
- Both maintains the order of insertion and we can get the elements in the order of insertion.
- The iterator implementations of ArrayList and Vector both are fail-fast by design.
- ArrayList and Vector both allows null values and random access to element using index number.
These are the differences between ArrayList and Vector.
- Vector is synchronized whereas ArrayList is not synchronized. However if you are looking for modification of list while iterating, you should use CopyOnWriteArrayList.
- ArrayList is faster than Vector because it doesn’t have any overhead because of synchronization.
- ArrayList is more versatile because we can get synchronized list or read-only list from it easily using Collections utility class
- Arrays can contain primitive or Objects whereas ArrayList can contain only Objects.
- Arrays are fixed size whereas ArrayList size is dynamic.
- Arrays doesn’t provide a lot of features like ArrayList, such as addAll, removeAll, iterator etc.
Although ArrayList is the obvious choice when we work on list, there are few times when array are good to use.
- If the size of list is fixed and mostly used to store and traverse them.
- For list of primitive data types, although Collections use autoboxing to reduce the coding effort but still it makes them slow when working on fixed size primitive data types.
- If you are working on fixed multi-dimensional situation, using [][] is far more easier than List<List>
ArrayList and LinkedList both implement List interface but there are some differences between them:
- ArrayList is an index based data structure backed by Array, so it provides random access to its elements with performance as O(1) but LinkedList stores data as list of nodes where every node is linked to its previous and next node. So even though there is a method to get the element using index, internally it traverse from start to reach at the index node and then return the element, so performance is O(n) that is slower than ArrayList.
- Insertion, addition or removal of an element is faster in LinkedList compared to ArrayList because there is no concept of resizing array or updating index when element is added in middle.
- LinkedList consumes more memory than ArrayList because every node in LinkedList stores reference of previous and next elements.
Vector, Hashtable, Properties and Stack are synchronized classes, so they are thread-safe and can be used in multi-threaded environment. Java 1.5 Concurrent API included some collection classes that allows modification of collection while iteration because they work on the clone of the collection, so they are safe to use in multi-threaded environment.
Both Queue and Stack are used to store data before processing them. java.util.Queue is an interface whose implementation classes are present in java concurrent package. Queue allows retrieval of element in First-In-First-Out (FIFO) order but it’s not always the case.
There is also Deque interface that allows elements to be retrieved from both end of the queue.
Stack is similar to queue except that it allows elements to be retrieved in Last-In-First-Out (LIFO) order.
Stack is a class that extends Vector whereas Queue is an interface.
java.util.Collections is a utility class consists exclusively of static methods that operate on or return collections. It contains polymorphic algorithms that operate on collections, “wrappers”, which return a new collection backed by a specified collection, and a few other
odds and ends.
This class contains methods for collection framework algorithms, such as binary search, sorting, shuffling, reverse etc.
| Comparable | Comparator |
|---|---|
| 1) Comparable provides a single sorting sequence. In other words, we can sort the collection on the basis of a single element such as id, name, and price. | The Comparator provides multiple sorting sequences. In other words, we can sort the collection on the basis of multiple elements such as id, name, and price etc. |
| 2) Comparable affects the original class, i.e., the actual class is modified. | Comparator doesn’t affect the original class, i.e., the actual class is not modified. |
| 3) Comparable provides compareTo() method to sort elements. | Comparator provides compare() method to sort elements. |
| 4) Comparable is present in java.lang package. | A Comparator is present in the java.util package. |
| 5) We can sort the list elements of Comparable type by Collections.sort(List) method. | We can sort the list elements of Comparator type by Collections.sort(List, Comparator) method. |
If we need to sort an array of Objects, we can use Arrays.sort(). If we need to sort a list of objects, we can use Collections.sort(). Both these classes have overloaded sort() methods for natural sorting (using Comparable) or sorting based on criteria (using Comparator).
Collections internally uses Arrays sorting method, so both of them have same performance except that Collections take sometime to convert list to array.
Exception is an error event that can happen during the execution of a program and disrupts its normal flow. Exception can arise from different kind of situations such as wrong data entered by user, hardware failure, network connection failure etc.
Whenever any error occurs while executing a java statement, an exception object is created and then JRE tries to find exception handler to handle the exception. If suitable exception handler is found then the exception object is passed to the handler code to process the exception, known as catching the exception. If no handler is found then application throws the exception to runtime environment and JRE terminates the program.
Java Exception handling framework is used to handle runtime errors only, compile time errors are not handled by exception handling framework.
- throw: Sometimes we explicitly want to create exception object and then throw it to halt the normal processing of the program. throw keyword is used to throw exception to the runtime to handle it.
- throws: When we are throwing any checked exception in a method and not handling it, then we need to use throws keyword in method signature to let caller program know the exceptions that might be thrown by the method. The caller method might handle these exceptions or propagate it to its caller method using throws keyword. We can provide multiple exceptions in the throws clause and it can be used with main() method also.
- try-catch: We use try-catch block for exception handling in our code. try is the start of the block and catch is at the end of try block to handle the exceptions. We can have multiple catch blocks with a try and trycatch block can be nested also. catch block requires a parameter that should be of type Exception.
- finally: finally block is optional and can be used only with try-catch block. Since exception halts the process of execution, we might have some resources open that will not get closed, so we can use finally block. Finally block gets executed always, whether exception occurrs or not.
Java Exceptions are hierarchical and inheritance is used to categorize different types of exceptions. Throwable is the parent class of Java Exceptions Hierarchy and it has two child objects – Error and Exception. Exceptions are further divided into checked exceptions and runtime exception.
Errors are exceptional scenarios that are out of scope of application and it’s not possible to anticipate and recover from them, for example hardware failure, JVM crash or out of memory error.
Checked Exceptions are exceptional scenarios that we can anticipate in a program and try to recover from it, for example fileNotFoundException. We should catch this exception and provide useful message to user and log it properly for debugging purpose. Exception is the parent class of all CheckedExceptions.
Runtime Exceptions are caused by bad programming, for example trying to retrieve an element from the Array. We should check the length of array first before trying to retrieve the element otherwise it might throw ArrayIndexOutOfBoundException at runtime. RuntimeException is the parent class of all runtime exceptions.
Exception and all of its subclasses doesn’t provide any specific methods and all of the methods are defined in the base class Throwable.
String getMessage() – This method returns the message String of Throwable and the message can be provided while creating the exception through it’s constructor.
String getLocalizedMessage() – This method is provided so that subclasses can override it to provide locale specific message to the calling program. Throwable class implementation of this method simply use getMessage() method to return the exception message.
synchronized Throwable getCause() – This method returns the cause of the exception or null id the cause is unknown.
String toString() – This method returns the information about Throwable in String format, the returned String contains the name of Throwable class and localized message.
void printStackTrace() – This method prints the stack trace information to the standard error stream, this method is overloaded and we can pass PrintStream or PrintWriter as argument to write the stack trace information to the file or stream.
- Checked Exceptions should be handled in the code using try-catch block or else main() method should use throws keyword to let JRE know about these exception that might be thrown from the program. Unchecked Exceptions are not required to be handled in the program or to mention them in throws clause.
- Exception is the super class of all checked exceptions whereas RuntimeException is the super class of all unchecked exceptions.
- Checked exceptions are error scenarios that are not caused by program, for example FileNotFoundException in reading a file that is not present, whereas Unchecked exceptions are mostly caused by poor programming, for example NullPointerException when invoking a method on an object reference without making sure that it’s not null.
throws keyword is used with method signature to declare the exceptions that the method might throw whereas throw keyword is used to disrupt the flow of program and handing over the exception object to runtime to handle it.
We can extend Exception class or any of its subclasses to create our custom exception class. The custom exception class can have its own variables and methods that we can use to pass error codes or other exception related information to the exception handler.
package com.journaldev.exceptions;
import java.io.IOException;
public class MyException extends IOException {
private static final long serialVersionUID = 4664456874499611218L;
private String errorCode="Unknown_Exception";
public MyException(String message, String errorCode){
super(message);
this.errorCode=errorCode;
}
public String getErrorCode(){
return this.errorCode;
}
}
OutOfMemoryError in Java is a subclass of java.lang.VirtualMachineError and it’s thrown by JVM when it ran out of heap memory. We can fix this error by providing more memory to run the java application through java options.
$>java MyProgram -Xms1024m -Xmx1024m -XX:PermSize=64M -XX:MaxPermSize=256m- Exception in thread main java.lang.UnsupportedClassVersionError: This exception comes when your java class is compiled from another JDK version and you are trying to run it from another java version.
- Exception in thread main java.lang.NoClassDefFoundError: There are two variants of this exception. The first one is where you provide the class full name with .class extension. The second scenario is when Class is not found.
- Exception in thread main java.lang.NoSuchMethodError: main: This exception comes when you are trying to run a class that doesn’t have main method.
- Exception in thread “main” java.lang.ArithmeticException: Whenever any exception is thrown from main method, it prints the exception is console. The first part explains that exception is thrown from main method, second part prints the exception class name and then after a colon, it prints the exception message.
- final and finally are keywords in java whereas finalize is a method.
- final keyword can be used with class variables so that they can’t be reassigned, with class to avoid extending by classes and with methods to avoid overriding by subclasses, finally keyword is used with try-catch block to provide statements that will always gets executed even if some exception arises, usually finally is used to close resources. finalize() method is executed by Garbage Collector before the object is destroyed, it’s great way to make sure all the global resources are closed.
- Out of the three, only finally is related to java exception handling.
When exception is thrown by main() method, Java Runtime terminates the program and print the exception message and stack trace in system console.
We can have an empty catch block but it’s the example of worst programming. We should never have empty catch block because if the exception is caught by that block, we will have no information about the exception and it wil be a nightmare to debug it. There should be at least a logging statement to log the exception details in console or log files.
TestNG(NG for Next Generation) is a testing framework that can be integrated with selenium or any other automation tool to provide multiple capabilities like assertions, reporting, parallel test execution, etc
- TestNG provides different assertions that help in checking the expected and actual results.
- It provides parallel execution of test methods.
- We can define the dependency of one test method over others in TestNG.
- Also, we can assign priority to test methods in Selenium.
- It permits the grouping of test methods into test groups.
- It allows data-driven testing using @DataProvider annotation.
- It gives inherent support for reporting.
- It has support for parameterizing test cases using @Parameters annotation
Selenium is an automation tool using which we can automate web-based applications. In order to add testing capabilities in the Test Automation suites – Selenium is clubbed with TestNG. With TestNG, we can have different features in our automation suite like different types of assertions, reporting, parallel execution, and parameterization, etc.
In short, for doing Automation Testing, Selenium helps with ‘automation’ and TestNG helps with ‘testing’ capabilities.
The testng.xml file is used for configuring the whole test suite. In testng.xml file, we can create a test suite, create test groups, mark tests for parallel execution, add listeners, and pass parameters to test scripts. We can also use this testng.xml file for triggering the test suite from
the command prompt/terminal or Jenkins.
Using groups attribute in TestNG, we can assign the test methods to different groups.
//Test method belonging to sanity suite only
@Test(groups = {“sanitySuite”})
public void testMethod1() {
//Test logic
}
//Test method belonging to both sanity and regression suite
@Test(groups = {“sanitySuite”, “regressionSuite”})
public void testMethod2() {
//Test logic
}Using the exclude tag in testng.xml file, we can exclude a particular test method from getting executed.
@Test – @Test annotation marks a method as a test method.
@BeforeSuite – The annotated method will run only once before all tests in this suite have run.
@AfterSuite – The annotated method will run only once after all tests in this suite have run.
@BeforeClass – The annotated method will run only once before the first test method in the current class is invoked.
@AfterClass – The annotated method will run only once after all the test methods in the current class have been run.
@BeforeTest – The annotated method will run before any test method belonging to the classes inside the tag is run.
@AfterTest – The annotated method will run after all the test methods belonging to the classes inside the tag have run.
@BeforeMethod – The annotated method will run before each test method marked by @Test annotation.
@AfterMethod – The annotated method will run after each test method marked by @Test annotation.
@DataProvider – The @DataProvider annotation is used to pass test data to the test method.
The test method will run as per the number of rows of data passed via the data provider method.
The test methods in TestNG follow the Suite->Test->Class->Method sequence combined with the Before annotations->Test annotations->After annotations sequence. So, the order of execution is-
@BeforeSuite
@BeforeTest
@BeforeClass
@BeforeMethod
@Test
@AfterMethod
@AfterClass
@AfterTest
@AfterSuite
assertEquals(String actual, String expected, String message) and other overloaded data types in parameter
assertNotEquals(double data1, double data2, String message) and other overloaded data types in parameter
assertFalse(boolean condition, String message)
assertTrue(boolean condition, String message)
assertNotNull(Object object)
fail(boolean condition, String message)
true(String message
By setting the “enabled” attribute as false, we can disable a test method from running.
//In case of a test method
@Test(enabled = false)
public void testMethod1() {
//Test logic
}
//In case of test method belonging to a group
@Test(groups = {“NegativeTests”}, enabled = false)
public void testMethod2() {
//Test logic
}Using dependsOnMethods parameter inside @Test annotation in TestNG we can make one test method run only after the successful execution of the dependent test method.
@Test(dependsOnMethods = { “preTests” })
We can define the priority of test cases using the “priority” parameter in @Test annotation. The tests with lower priority value will get executed first.
Example-
@Test(priority=1)
The default priority of a test when not specified is integer value 0. So, if we have one test case with priority 1 and one without any priority then the test without any priority value will get executed first (as default value will be 0 and tests with lower priority are executed first).
Using invocationCount parameter and setting its value to an integer value, makes the test method to run n number of times in a loop.
@Test(invocationCount = 10)
public void invocationCountTest(){
//Test logic
}
The threadPoolSize attribute specifies the number of threads to be assigned to the test method. This is used in conjunction with invocationCount attribute. The number of threads will get divided with the number of iterations of the test method specified in the invocationCount attribute.
@Test(threadPoolSize = 5, invocationCount = 10)
public void threadPoolTest(){
//Test logic
}
Soft assertions (SoftAssert) allows us to have multiple assertions within a test method, even when an assertion fails the test method continues with the remaining test execution. The result of all the assertions can be collated at the end using softAssert.assertAll() method.
@Test
public void softAssertionTest(){
SoftAssert softAssert= new SoftAssert();
//Assertion failing
softAssert.fail();
System.out.println(“Failing”);
//Assertion passing
softAssert.assertEquals(1, 1);
System.out.println(“Passing”);
//Collates test results and marks them pass or fail
softAssert.assertAll();
}Here, even though the first assertion fails still the test will continue with execution and print the message below the second assertion.
Hard assertions on the other hand are the usual assertions provided by TestNG. In case of hard assertion in case of any failure, the test execution stops, preventing the execution of any further steps within the test method.
We can use the timeOut attribute of @Test annotation. The value assigned to this timeOut attribute will act as an upperbound, if test doesn’t get executed within this time frame then it will fail with timeOut exception.
@Test(timeOut = 1000)
public void timeOutTest() throws InterruptedException {
//Sleep for 2sec so that test will fail
Thread.sleep(2000);
System.out.println(“Will throw Timeout exception!”);
}Using SkipException, we can conditionally skip a test case. On throwing the skipException, the test method is marked as skipped in the test execution report and any statement after throwing the exception will not get executed.
@Test
public void testMethod(){
if(conditionToCheckForSkippingTest)
throw new SkipException(“Skipping the test”);
//test logic
}Using “alwaysRun” attribute of @Test annotation, we can make sure the test method will run even if the test methods or groups on which it depends fail or get skipped.
@Test
public void parentTest() {
Assert.fail(“Failed test”);
}
@Test(dependsOnMethods={“parentTest”}, alwaysRun=true)
public void dependentTest() {
System.out.println(“Running even if parent test failed”);
}Here, even though the parentTest failed, the dependentTest will not get skipped instead it will executed because of “alwaysRun=true”. In case, we remove the “alwaysRun=true” attribute from @Test then the report will show one failure and one skipped test, without trying to run the dependentTest method.
Using @Parameter annotation and ‘parameter’ tag in testng.xml we can pass parameters to test scripts.
Sample testng.xml –
Sample test script
public class TestFile {
@Test
@Parameters(“sampleParamName”)
public void parameterTest(String paramValue) {
System.out.println(“Value of sampleParamName is – ” + sampleParamName); }
Using @DataProvider we can create a data-driven framework in which data is passed to the associated test method and multiple iterations of the test run for the different test data values passed from the @DataProvider method. The method annotated with @DataProvider annotation return a 2D array of object.
//Data provider returning 2D array of 3*2 matrix
@DataProvider(name = “dataProvider1”)
public Object[][] dataProviderMethod1() {
return new Object[][] {{“kuldeep”,”rana”}, {“k1″,”r1”},{“k2″,”r2”}};
}
//This method is bound to the above data provider returning 2D array of 3*2 matrix
//The test case will run 3 times with different set of values
@Test(dataProvider = “dataProvider1”)
public void sampleTest(String s1, String s2) {
System.out.println(s1 + ” ” + s2);
}
TestNG provides us different kinds of listeners using which we can perform some action in case an event gets triggered. Usually, testNG listeners are used for configuring reports and logging. One of the most widely used listeners in testNG is ITestListener interface. It has
methods like onTestSuccess, onTestFailure, onTestSkipped etc. We need to implement this interface creating a listener class of our own. After that using the @Listener annotation we can use specify that for a particular test class our customized listener class should be used.
@Listeners(PackageName.CustomizedListenerClassName.class)
public class TestClass {
WebDriver driver= new FirefoxDriver();@Test
public void testMethod(){
//test logic
}
}@Factory annotation helps in the dynamic execution of test cases. Using @Factory annotation we can pass parameters to the whole test class at run time. The parameters passed can be used by one or more test methods of that class.
Example – there are two classes TestClass and the TestFactory class. Because of the @Factory annotation, the test methods in class TestClass will run twice with the data “k1” and “k2”.
public class TestClass{
private String str;
//Constructor
public TestClass(String str) {
this.str = str;
}
@Test
public void TestMethod() {
System.out.println(str);
}
}
==========================
public class TestFactory{
//The test methods in class TestClass will run twice with data “k1” and “k2”
@Factory
public Object[] factoryMethod() {
return new Object[] { new TestClass(“K1”), new TestClass(“k2”) };
}
}@Factory method creates instances of test class and run all the test methods in that class with a different set of data.
Whereas, @DataProvider is bound to individual test methods and run the specific methods multiple times.
In order to run the tests in parallel just add these two key-value pairs inside the suite tag of the testng.xml file
parallel=”{methods/tests/classes}”
thread-count=”{number of thread you want to run simultaneously}”
Cucumber is a testing framework which supports Behavior Driven Development (BDD). It lets us define application behavior in plain meaningful English text using a simple grammar defined by a language called Gherkin. Cucumber itself is written in Ruby, but it can be used to “test” code written in Ruby or other languages including but not limited to Java, C# and Python.
TDD is an iterative development process. Each iteration starts with a set of tests written for a new piece of functionality. These tests are supposed to fail during the start of iteration as there will be no application code corresponding to the tests. In the next phase of the iteration, Application code is written with an intention to pass all the tests written earlier in the iteration. Once the application code is ready tests are run.
- Unit test proves that the code actually works
- Can drive the design of the program
- Refactoring allows improving the design of the code
- Low-Level regression test suite
- Test first reduce the cost of the bugs
As Gherkin is a structured language it follows some syntax let us first see a simple scenario described in gherkin.
Feature: Search feature for users
This feature is very important because it will allow users to filter products
Scenario: When a user searches, without spelling mistake, for a product name present in inventory. All the products with similar name should be displayed
Given User is on the main page of www.myshopingsite.com
When User searches for laptops
Then search page should be updated with the lists of laptops
- cobertura-2.1.1
- cucumber-core-1.2.5
- cucumber-java-1.2.5
- cucumber-junit-1.2.5
- cucumber-jvm-deps-1.0.5
- cucumber-reporting-3.10.0
- gherkin-2.12.2
- junit-4.12
- mockito-all-2.0.2-beta
This is a file where you will describe your tests in Descriptive language (Like English).
A feature file can contain a scenario or can contain many scenarios in a single feature file but it usually contains a list of scenarios.
Feature: Login Action
Scenario: Successful Login with Valid Credentials
Given User is on Home Page
When User Navigate to LogIn Page
And User enters UserName and Password
Then Message displayed Login Successfully
Scenario: Successful LogOut
When User LogOut from the Application
Then Message displayed LogOut Successfully
package cucumberTest;
import org.junit.runner.RunWith;
import cucumber.api.CucumberOptions;
import cucumber.api.junit.Cucumber;
@RunWith(Cucumber.class)
@CucumberOptions(
features = ""Feature""
,glue={""stepDefinition""}
)
public class TestRunner {
}Feature : Feature defines the logical test functionality you will test in this feature file.
Feature: LogIn Action Test
Or
Feature: LogIn Action Test
Description: This feature will test a LogIn and LogOut functionality
Or
Feature: LogIn Action Test
This feature will test a LogIn and LogOut functionality
Background : Background keyword is used to define steps that are common to all the tests in the feature file.
Scenario: Each Feature will contain a number of tests to test the feature. Each test is called a Scenario and is described using the Scenario: keyword.
Given : Given defines a precondition to the test.
When : When keyword defines the test action that will be executed.
Then : Then keyword defines the Outcome of previous steps.
And : And keyword is used to add conditions to your steps.
But : But keyword is used to add negative type comments.
* : This keyword is very special. This keyword defies the whole purpose of having Given, When, Then and all the other keywords. Basically Cucumber doesn’t care about what Keyword you use to define test steps, all it cares about what code it needs to execute for each step. That code is called a step definition
——————————————————–
Feature: LogIn Action Test
Description: This feature will test a LogIn and LogOut functionality
Scenario: Successful Login with Valid Credentials
* User is on Home Page
* User Navigate to LogIn Page
* User enters UserName and Password
* Message displayed Login Successfully
Step Definition is a java method in a class with an annotation above it.
An annotation followed by the pattern is used to link the Step Definition to all the matching Steps, and the code is what Cucumber will execute when it sees a Gherkin Step.
Cucumber finds the Step Definition file with the help of the Glue code in Cucumber Options.
Create a new Class file in the ‘stepDefinition‘ package and name it as ‘Test_Steps‘, by right click on the Package and select New > Class
@Given("^User is on Home Page$")
public void user_is_on_Home_Page() throws Throwable {
driver = new FirefoxDriver();
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
driver.get("https://www.store.demoqa.com");
}@CucumberOptions are like property files or settings for your test.
dryRun: true (checks if all steps have step definition)
features: set the path of feature files
glue: set the path of step definition files
tags: what tags in the feature files should be executed
monochrome: true (Display the console output in much readable way
format: what all report format to use
strict: true (will fail if there are undefined or pending steps)
package cucumberTest;
import org.junit.runner.RunWith;
import cucumber.api.CucumberOptions;
import cucumber.api.junit.Cucumber;
@RunWith(Cucumber.class)
@CucumberOptions(
features = ""Feature""
,glue={""stepDefinition""}
,dryRun=true
,monochrome = false
,format = {""pretty"", ""html:target/Destination""} )
)
public class TestRunner {
}Feature: Login Action
Scenario: Successful Login with Valid Credentials
Given User is on Home Page
When User Navigate to LogIn Page
And User enters “testuser_1” and “Test@123”
Then Message displayed Login Successfully
---------------------------------------------------------------------------
@When("^User enters \"(.*)\" and \"(.*)\"$")
public void user_enters_UserName_and_Password(String username, String password) throws Throwable {
driver.findElement(By.id("log")).sendKeys(username);
driver.findElement(By.id("pwd")).sendKeys(password);
driver.findElement(By.id("login")).click();
}
-----------------------------------------------------------------------------
@When(“^User enters \”([^\”]*)\” and \”([^\”]*)\”$”)Feature: Login Action
Scenario: Successful Login with Valid Credentials
Given User is on Home Page
When User Navigate to LogIn Page
And User enters ""testuser_1"" and ""Test@123""
Then Message displayed Login Successfully
---------------------------------------------------------------------------
@When(""^User enters \""(.*)\"" and \""(.*)\""$"")
public void user_enters_UserName_and_Password(String username, String password) throws Throwable {
driver.findElement(By.id(""log"")).sendKeys(username);
driver.findElement(By.id(""pwd"")).sendKeys(password);
driver.findElement(By.id(""login"")).click();
}
-----------------------------------------------------------------------------
@When(“^User enters \”([^\”]*)\” and \”([^\”]*)\”$”)Scenario Outline:
This uses Example keyword to define the test data for the Scenario.
This works for the whole test.
Cucumber automatically run the complete test the number of times equal to the number of data in the Test Set.
Data Table:
No keyword is used to define the test data.
This works only for the single step, below which it is defined.
A separate code needs to understand the test data and then it can be run single or multiple times but again just for the single step, not for the complete test.
Scenario: Successful Login with Valid Credentials
Given User is on Home Page
When User Navigate to LogIn Page
And User enters Credentials to LogIn
| testuser_1 | Test@153 |
Then Message displayed Login Successfully
--------------------------------------------------------------------------------
@And(""^User enters Credentials to LogIn$"")
public void user_enters_testuser__and_Test(DataTable usercredentials) throws Throwable {
//Write the code to handle Data Table
List<List> data = usercredentials.raw();
//This is to get the first data of the set (First Row + First Column)
driver.findElement(By.id(""log"")).sendKeys(data.get(0).get(0));
//This is to get the first data of the set (First Row + Second Column)
driver.findElement(By.id(""pwd"")).sendKeys(data.get(0).get(1));
driver.findElement(By.id(""login"")).click();
}Data Tables in Cucumber, we pass Username & Password without Header, due to which the test was not much readable.
Scenario: Successful Login with Valid Credentials
Given User is on Home Page
When User Navigate to LogIn Page
And User enters Credentials to LogIn
| Username | Password |
| testuser_1 | Test@153 |
Then Message displayed Login Successfully
----------------------------------------------------------------------------------
@When(""^User enters Credentials to LogIn$"")
public void user_enters_testuser_and_Test(DataTable usercredentials) throws Throwable {
//Write the code to handle Data Table
List<Map> data = usercredentials.asMaps(String.class,String.class);
driver.findElement(By.id(""log"")).sendKeys(data.get(0).get(""Username""));
driver.findElement(By.id(""pwd"")).sendKeys(data.get(0).get(""Password""));
driver.findElement(By.id(""login"")).click();
}=================================================================================
@When(""^User enters Credentials to LogIn$"")
public void user_enters_testuser_and_Test(DataTable usercredentials) throws Throwable {
//Write the code to handle Data Table
for (Map data : usercredentials.asMaps(String.class, String.class)) {
driver.findElement(By.id(""log"")).sendKeys(data.get(""Username""));
driver.findElement(By.id(""pwd"")).sendKeys(data.get(""Password""));
driver.findElement(By.id(""login"")).click();
}
}We can define each scenario with a useful tag. Later, in the runner file, we can decide which specific tag (and so as the scenario(s)) we want Cucumber to execute. Tag starts with “@”. After “@” you can have any relevant text to define your tag like @SmokeTests just above the scenarios you like to mark. Then to target these tagged scenarios just specify the tags names in the CucumberOptions as tags = {“@SmokeTests”}.
@FunctionalTest
Feature: ECommerce Application
@SmokeTest @RegressionTest
Scenario: Successful Login
Given This is a blank test
@RegressionTest
Scenario: UnSuccessful Login
Given This is a blank test
package cucumberTest;
import org.junit.runner.RunWith;
import cucumber.api.CucumberOptions;
import cucumber.api.junit.Cucumber;
@RunWith(Cucumber.class)
@CucumberOptions(
features = ""Feature""
,glue={""stepDefinition""}
,dryRun=true
,monochrome = false
,format = {""pretty"", ""html:target/Destination""} )
,tags={""smokeTest""}
)
public class TestRunner {
}Execute all tests tagged as @SmokeTest OR @RegressionTest : tags = {"SmokeTest,RegressionTest"}
Execute all tests tagged as @SmokeTest AND @RegressionTest : tags = {"SmokeTest", "RegressionTest"}
Execute all tests of the feature tagged as @FunctionalTests but skip scenarios tagged as @SmokeTest : tags = {"FunctionalTest","~SmokeTest"}Cucumber supports hooks, which are blocks of code that run before or after each scenario. You can define them anywhere in your project or step definition layers, using the methods @Before and @After. Cucumber Hooks allows us to better manage the code workflow and helps us to reduce the code redundancy.
This prerequisite can be anything from:
Starting a webdriver
Setting up DB connections
Setting up test data
Setting up browser cookies
Navigating to certain page
or anything before the test
In the same way, there are always after steps as well of the tests like:
Killing the webdriver
Closing DB connections
Clearing the test data
Clearing browser cookies
Logging out from the application
Printing reports or logs
Taking screenshots on error
or anything after the test
package utilities;
import cucumber.api.java.After;
import cucumber.api.java.Before;
public class Hooks {
@Before
public void beforeScenario(){
System.out.println(""This will run before the Scenario"");
}
@After
public void afterScenario(){
System.out.println(""This will run after the Scenario"");
}
}Feature: Test Tagged Hooks
@First
Scenario: This is First Scenario
Given this is the first step
When this is the second step
Then this is the third step
@Second
Scenario: This is Second Scenario
Given this is the first step
When this is the second step
Then this is the third step
@Third
Scenario: This is Third Scenario
Given this is the first step
When this is the second step
Then this is the third step
"package utilities;
import cucumber.api.java.After;
import cucumber.api.java.Before;
public class Hooks {
@Before
public void beforeScenario(){
System.out.println(""This will run before the every Scenario"");
}
@After
public void afterScenario(){
System.out.println(""This will run after the every Scenario"");
}
@Before(""@First"")
public void beforeFirst(){
System.out.println(""This will run only before the First Scenario"");
}
@Before(""@Second"")
public void beforeSecond(){
System.out.println(""This will run only before the Second Scenario"");
}
@Before(""@Third"")
public void beforeThird(){
System.out.println(""This will run only before the Third Scenario"");
}
@After(""@First"")
public void afterFirst(){
System.out.println(""This will run only after the First Scenario"");
}
@After(""@Second"")
public void afterSecond(){
System.out.println(""This will run only after the Second Scenario"");
}
@After(""@Third"")
public void afterThird(){
System.out.println(""This will run only after the Third Scenario"");
}
}"@Before(order = int) : This runs in increment order, means value 0 would run first and 1 would be after 0.
@After(order = int) : This runs in decrements order, means apposite of @Before. Value 1 would run first and 0 would be after 1.
import cucumber.api.java.en.Given;
import cucumber.api.java.en.Before;
public class PriorityTest {
@Given ("^User navigates to Reorder page$")
public void navigate_reorder () {
System.out.println ("Reorder page is navigated");
}
@Before (order = 2)
public void precondition1 () {
System.out.println ("The precondition1 is to be executed");
}
@Before (order = 1)
public void precondition2 () {
System.out.println ("The precondition2 is to be executed");
}
}Background in Cucumber is used to define a step or series of steps that are common to all the tests in the feature file.
A Background is much like a scenario containing a number of steps. But it runs before each and every scenario were for a feature in which it is defined.
Feature: Test Background Feature
Description: The purpose of this feature is to test the Background keyword
Background: User is Logged In
Given I navigate to the login page
When I submit username and password
Then I should be logged in
Scenario: Search a product and add the first product to the User basket
Given User search for Lenovo Laptop
When Add the first laptop that appears in the search result to the basket
Then User basket should display with added item
Scenario: Navigate to a product and add the same to the User basket
Given User navigate for Lenovo Laptop
When Add the laptop to the basket
Then User basket should display with added item
Profile in cucumber allows a way to define a group of tests in a feature file to run a selected group instead of executing all the commands while testing a feature. Cucumber profiles allow running step definitions and features.
Use the command below to run the cucumber profile.
Cucumber features -pWe can add comments in the Cucumber code. The comments are incorporated in code mostly for documentation and not for including program logic. It makes the code easier to apprehend and to debug the errors. Also, comments can be put at any point in the code.
Inside the feature file, the comments are added after the (#) symbol and the step definition contains comments after the (//) symbol.
Feature file with comments.
- Feature: Customer verification
- # Scenario with customer
- Scenario: Verify customer details
- Given User navigates to Customer Information Page
import cucumber.api.java.en.Given;
public class CustomerInformation {
@Given ("^User navigates to Customer Information Page$")
//method to map @Given scenario in feature file
public void navigate_to_customerInformation () {
System.out.println ("Customer Information Page is navigated");
}
}We can use regular expressions in the Cucumber framework inside the step definition file. The regular expression can be used to combine two or more similar steps in the feature file within a test method in the step definition file. Also, the regular expression is used for data parameterization in Cucumber as the Feature New User Registration in the feature file described previously.
Feature file implementation.
- Feature: Student Study Schedule
- Description: Verify student study schedule
- Scenario: Verify hours spent on science subjects
- Given Student studies Chemistry on Tuesday
- Given Student studies Mathematics on Tuesday
- Given Student has thirty minutes recess
import cucumber.api.java.en.Given;
public class StudentSchedule {
@Given ("^Student studies ([^\"]*) on Tuesday$")
public void student_Tuesday_schedule (String subject) {
if (subject.equals ("Chemistry")){
System.out.println ("Student studies Chemistry on Tuesday");
} else {
System.out.println ("Student studies Mathematics on Tuesday");
}
}
@Given ("^Student has thirty minutes recess$")
public void student_recess () {
System.out.println ("Student recess time is thirty minutes");
}
}For HTML reports, add html:target/cucumber-reports to the @CucumberOptions plugin option.
@CucumberOptions(
features = "src/test/resources/functionalTests",
glue= {"stepDefinitions"},
plugin = { "pretty", "html:target/cucumber-reports" },
monochrome = true
)For JSON reports, add json:target/cucumber-reports/Cucumber.json to the @CucumberOptions plugin option.
@CucumberOptions(
features = "src/test/resources/functionalTests",
glue= {"stepDefinitions"},
plugin = { "pretty", "json:target/cucumber-reports/Cucumber.json" },
monochrome = true
)For JUNIT reports, add junit:targe/cucumber-reports/Cucumber.xml to the @CucumberOptions plugin option.
@CucumberOptions(
features = "src/test/resources/functionalTests",
glue= {"stepDefinitions"},
plugin = { "pretty", "junit:target/cucumber-reports/Cucumber.xml" },
monochrome = true
)Page Object Model is a design pattern which has become popular in test automation for enhancing test maintenance and reducing code duplication. A page object is an object-oriented class that serves as an interface to a page of your AUT.
Page Object model is an object design pattern in Selenium, where web pages are represented as classes, and the various elements on the page are defined as variables on the class.
Page Object Model is a Design Pattern which has become popular in Selenium Test Automation. Page object model (POM) can be used in any kind of framework such as modular, data-driven, keyword driven, hybrid framework etc.
The Page Factory Class is an extension to the Page Object design pattern. It is used to initialize the elements of the Page Object or instantiate the Page Objects itself. Annotations for elements can also be created (and recommended) as the describing properties may not always be descriptive enough to tell one object from the other.
Page Factory is an inbuilt page object model concept for Selenium Web Driver, but it is much optimized. Page Factory can be used in any kind of framework such as Data Driven, Modular or Keyword Driven. Page Factory gives more focus on how the code is being structured to get the best benefit out of it.
Page Object is a class that represents a web page and hold the functionality and members.
Page Factory is a way to initialize the web elements you want to interact with within the page object when you create an instance of it.
Test Class – In Test Class, we will write an actual selenium test script. Here, we call Page Action and mentioned actions to be
performed on Web Pages. For each page, we can write our own test class for better code readability. We can write test cases in @Test annotation.
In Page Action Class, we can write all web pages action as per the pages and functionality. Under Page Action component, for each page in the application, we have corresponding Page class.
Page Factory class is nothing but Object Repository in other term. For each web page, it has its own Page Object definitions. Each web element should uniquely get identified and should be defined at class level. We will use Find By annotation and will define web element so that we will be able to perform actions on them.
package pageObjects;
import java.util.List;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.FindAll;
import org.openqa.selenium.support.FindBy;
import org.openqa.selenium.support.How;
import org.openqa.selenium.support.PageFactory;
public class CheckoutPage {
WebDriver driver;
public CheckoutPage(WebDriver driver) {
this.driver = driver;
PageFactory.initElements(driver, this);
}
@FindBy(how = How.CSS, using = "#billing_first_name")
private WebElement txtbx_FirstName;
public void enter_Name(String name) {
txtbx_FirstName.sendKeys(name);
}
}@FindBy – It is used to locate web elements using different locators strategies.
@FindBy(how = How.ID, using = “userName”)
WebElement username;
@FindBys – To locate a web element with more than one search criteria, you can use @FindBys annotation. This annotation locates the web element by using the AND condition on the search criteria.
@FindBys({
@FindBy(class=”classname”),
@FindBy(id=”idname”)
})
WebElement name;
@FindAll – The @FindAll annotation locates the web element using more than one criteria, given that at least one criteria match. Contrary to @FindBys, it uses an OR conditional relationship between the multiple @FindBy.
@FindAll({
@FindBy(id=”btn”, //doesn’t match
@FindBy(name=”submit”), //Matches
@FindBy(class=”submitclass”) //doesn’t match
})
WebElement submitButton;
@CacheLookUp – The @CacheLookUp annotation is very useful when you are referring to the same web element multiple times. Using @CacheLookUp, we can store the web elements in cache memory right after reading for the first time. It fastens our execution and the code, need not look up for the element on the web page and directly references it from memory.
The @CacheLookUp can be prefixed with any of the annotations discussed above, i.e., @FindBy, @FindBys & @FindAll.
@CacheLookUp
@FindBys({
@FindBy(class=”checkbox-class”),
@FindBy(id=”checkbox-id”)
})
WebElement chkBox;
When we use “initElements” method of PageFactory, all page objects of Page Object class are initialized. It does not mean webdriver locates all web elements of page and store it.
Webdriver will locate element only when page object(Web element) is being used or you can say when any action like click etc are performed on web element and it will through noSuchElementException if web element is not found.
Exceptions are faults or disruptions that occur during the execution of a program/application. Exception handling is crucial for maintaining the natural or normal flow of the application. Selenium exceptions can be broadly categorized into two types: Checked and Unchecked
Exceptions.
Checked exceptions are handled during the coding process itself. Unchecked exceptions occur during run-time and can have a much greater impact on the application flow. We have compiled some of the most common selenium exceptions along with the various ways to
handle them.
Most Common Selenium Exceptions
- NoSuchWindowException
- NoSuchFrameException
- NoSuchElementException
- NoAlertPresentException
- InvalidSelectorException
- TimeoutException
- ElementNotVisibleException
- ElementNotSelectableException
- NoSuchSessionException
- StaleElementReferenceException
Selenium is an open source umbrella project for a range of tools and libraries aimed at supporting browser automation. It provides a playback tool for authoring functional tests across most modern web browsers, without the need to learn a test scripting language.
Most programmers and developers who build website applications and wish to test them every now and then use Selenium. One of the biggest advantages of Selenium, which has made it so popular, is its flexibility. Any individual who creates web programs can use Selenium to test the code and applications. Further, professionals can debug and perform visual regression tests as per the requirements of the website or code.
Automation testing is a Software testing method or technique to test any application and compare the actual result with the expected result. This can be achieved by designing test scripts using any relevant automation testing tool. Now a days Automation is vastly used to automate repetitive tasks and other testing tasks which are difficult to perform manually.
In manual testing test cases are executed manually without any proper support from relevant tools. However, for automated testing, test cases are executed with the assistance of one or more appropriate tools. Automation Testing is also more reliable as there is less chances of human error. In manual testing we have to run test cases manually every time based on our need, hence it is time consuming. However, in
automation testing once scripts are ready we can run the test cases any number of time with different combination of data with minimal time.
Selenium IDE, a Firefox add-on that you can only use in creating relatively simple test cases and test suites.
Selenium Remote Control, also known as Selenium 1, which is the first Selenium tool that allowed users to use programming languages in creating complex tests.
WebDriver, the newer breakthrough that allows your test scripts to communicate directly to the browser, thereby controlling it from the OS level.
Selenium Grid is also a tool that is used with Selenium RC to execute parallel tests across different browsers and operating systems.
- Selenium is open source and free software and hence there is no licensing cost for its usage.
- Scripting can be done in most of the widely used programming languages like Java, C#, Ruby, Perl, PHP and Python
- Automation using selenium can be done in many OS platform like MS Windows, Macintosh and Linux
- It supports most of the popular browsers like Chrome, FireFox, Internet Explorer, Opera and Safari.
- Selenium Grid helps in parallel and distributed testing
- It uses less Hardware resources
- Selenium does not provide desktop application automation support.
- Web Services – REST or SOAP cannot be automated using selenium.
- Selenium WebDriver requires programming language requirement for script creation.
- No vendor support for tool compared to commercial tools like HP UFT
- As there is no object repository concept in Selenium, maintainability of objects becomes difficult
- For performing common tasks required in automation like logging, reading-writing to external files we have to rely on external libraries
- Faster than other tools of Selenium suite (IDE, RC)
- Control the browser by programming
- Supports Data driven Testing and Cross browser testing
- Supports Parallel test execution with the help of either JUnit or TestNG
The locator can be termed as an address that identifies a web element uniquely within the webpage. Locators are the HTML properties of a web element.
- ID – driver.findElement(By.id(“IdName”))
- Name – driver.findElement(By.name(“Name”))
- Class Name – driver.findElement(By.className(“Element Class”))
- Tag Name – driver.findElement(By.tagName(“HTML Tag Name”))
- Link Text – driver.findElement(By.linkText(“LinkText”))
- Partial Link Text – driver.findElement(By.partialLinkText(“partialLinkText”))
- CSS Selector – driver.findElement(By.cssSelector(“value”))
- XPath – driver.findElement(By.xpath(“XPath”))
driver – Object/Instance of WebDriver
findElement – WebDriver method
By – Pre-defined Class in Selenium
id – Element locater/attribute
IdName – Locator value
Basic Xpath – XPath expression select nodes or list of nodes on the basis of attributes like ID , Name, Classname, etc. from the XML document.
Contains() – Contains() is a method used in XPath expression. It is used when the value of any attribute changes dynamically.
Using OR & AND – In OR expression, two conditions are used, whether 1st condition OR 2nd condition should be true. It is also applicable if any one condition is true or maybe both. Means any one condition should be true to find the element.
Starts-with() – It is used to identify an element, when we are familiar with the attributes value (starting with the specified text) of an element
Text() – This mechanism is used to locate an element based on the text available on a webpage.
Following – By using this we could select everything on the web page after the closing tag of the current node.
Ancestor – The ancestor axis selects all ancestors element (grandparent, parent, etc.) of the current node.
Child – Selects all children elements of the current node.
Preceding – Selects all nodes that appear before the current node in the document, except ancestors, attribute nodes and namespace nodes.
Following-sibling – Select the following siblings of the context node. Siblings are at the same level of the current node.
Parent – Selects the parent of the current node.
position() – Selects the element out of all input element present depending on the position number provided
Xpath Symbols
//tagname[@attribute-name=’value1′]
//*[@attribute-name=’value1′]
Xpath Generation using different other methods
Xpath=//*[contains(@type,'sub')]
Xpath=//*[@type='submit' OR @name='btnReset']
Xpath=//input[@type='submit' and @name='btnLogin']
Xpath=//label[starts-with(@id,'message')]
Xpath=//td[text()=‘textname']
Xpath=//*[@type='text']//following::input
Xpath=//*[text()=‘textvalue']//ancestor::div
Xpath=//*[@id=‘idname']/child::li
Xpath=//*[@type=‘typename']//preceding::input
Xpath=//*[@type=' typename ']//following-sibling::input
Xpath=//*[@id=' idname']//parent::div
Absolute Xpath: It uses Complete path from the Root Element to the desire element.
Example: /HTML/body/div/div[@id=’Email’]
Relative Xpath: You can simply start by referencing the element you want and go from there. Always Relative Xpaths are preferred as they are not the complete paths from the Root element. … So Always use Relative Xpaths in your Automation.
Example: //span[@class=’Email’]
/ -> Selects from the root node
// ->Selects nodes in the document from the current node that match the selection no matter where they are
CSS can be generated using different methods:
css=
css=
css=;
Example: input[type=submit]
css=tag.class[attribute=value]
Starts with (^): css=
End with (^): css=
Contains (*): css=
Example: css=input[id*='id']
Using Multiple Symbols:
css = tagname[attribute1='value1'][attribute2='value2']
You can use “submit” method on element to submit a form after all mandatory information filled.
Example: element.submit();
find element(): It finds the first element within the current page using the given “locating mechanism”. It returns a single WebElement. It is the responsibility of developers and testers to make sure that web elements are uniquely identifiable using certain properties such as ID or name.
Syntax: WebElement userid = driver.findElement(By.id(“Id Value”));
findElements() : Using the given “locating mechanism” it will find all the elements within the current page. It returns a list of web elements. It returns an empty list if there are no elements found using the given locator strategy and locator value.
Syntax: List elementName = driver.findElements(By.LocatorStrategy(“LocatorValue”));
TypeKeys() will trigger JavaScript event in most of the cases whereas .type() won’t. Type key populates the value attribute using JavaScript whereas .typekeys() emulates like actual user typing
Assert: Assert allows to check whether an element is on the page or not. The test will stop on the step failed, if the asserted element is not available. In other words, the test will terminated at the point where check fails.
Verify: Verify command will check whether the element is on the page, if it is not then the test will carry on executing. In verification, all the commands are going to run guaranteed even if any of test
To click on specific part of element, you would need to use clickAT command. ClickAt command accepts element locator and x, y co-ordinates as arguments- clickAt (locator, cordString)
driver.findElement(By.xpath(“xpath”)).sendKeys(Keys.ENTER);
The Implicit Wait in Selenium is used to tell the web driver to wait for a certain amount of time before it throws a “No Such Element Exception”. The default setting is 0. Once we set the time, the web driver will wait for the element for that time before throwing an exception.
Selenium Web Driver has borrowed the idea of implicit waits from Watir.
Before Selenium 4 –
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
Now we will see this as deprecated @Deprecated WebDriver.Timeouts implicitlyWait(long time, TimeUnit unit);
After Selenium 4 –
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));
The Explicit Wait in Selenium is used to tell the Web Driver to wait for certain conditions (Expected Conditions) or maximum time exceeded before throwing “ElementNotVisibleException” exception. It is an intelligent kind of wait, but it can be applied only for specified elements. It gives better options than implicit wait as it waits for dynamically loaded Ajax elements.
Once we declare explicit wait we have to use “ExpectedConditions” or we can configure how frequently we want to check the condition using Fluent Wait. These days while implementing we are using Thread.Sleep() generally it is not recommended to use.
Before Selenium 4 –
//Old syntax
WebDriverWait wait = new WebDriverWait(driver,10);
wait.until(ExpectedConditions.visibilityOfElementLocated(By.cssSelector(“.classlocator”)));
After Selenium 4 –
//Selenium 4 syntax
WebDriverWait wait = new WebDriverWait(driver,Duration.ofSeconds(10));
wait.until(ExpectedConditions.visibilityOfElementLocated(By.cssSelector(“.classlocator”)));
The Fluent Wait in Selenium is used to define maximum time for the web driver to wait for a condition, as well as the frequency with which we want to check the condition before throwing an “ElementNotVisibleException” exception. It checks for the web element at regular intervals until the object is found or timeout happens.
Frequency: Setting up a repeat cycle with the time frame to verify/check the condition at the regular interval of time.
FluentWait wait = new FluentWait(driver);
.withTimeout(30, TimeUnit.SECONDS)
.pollingEvery(5, TimeUnit.SECONDS)
.ignoring(NoSuchElementException.class);
WebElement element = wait.until(new Function<WebDriver, WebElement) {
public WebElement apply(WebDriver driver) {
return driver.findElement(By.id("element"));
}
});findElement () will return only single WebElement and if that element is not located or we use some wrong selector then it will throw NoSuchElement exception.
findElements() – FindElements in Selenium command takes in By object as the parameter and returns a list of web elements. It returns an empty list if there are no elements found using the given locator strategy and locator value.
WebElement demos=driver.findElement(By.xpath(""//*[@id='menu-top']/li[1]/a""));
List links=driver.findElements(By.xpath("".//*[@id='menu-top']/li""));- Datadriven framework: In this framework, the test data is separated and kept outside the Test Scripts, while test case logic resides in Test Scripts. Test data is read from the external files ( Excel Files) and are loaded into the variables inside the Test Script. Variables are used for both for input values and for verification values.
- Keyworddriven framework: The keyword driven frameworks requires the development of data tables and keywords, independent of the test automation. In a keyword driven test, the functionality of the application under test is documented in a table as well as step by step instructions for each test.
To work with Basic Authentication pop-up (which is a browser dialogue window), you just need to send the user name and password along with the application URL.
#1 (Chrome & Firefox)
By passing user credentials in URL. Its simple, append your username and password with the URL.
e.g., http://Username:Password@SiteURL
http://rajkumar:myPassword@www.hireqa.co.in
#2 (IE)
First create AutoIt script as below and save it as basicauth.au3
To pass user name and password
WinWaitActive(""Windows Security"")
Send(""admin"")
Send(""{TAB}"")
Send(""admin"")
Send(""{ENTER}"")
--------------------------------------------------
try {
Runtime.getRuntime().exec(""E:/basicauth.exe"");
} catch (Exception e) {
e.printStackTrace();
}WebDriverManager class in Selenium:
- automates the management of WebDriver binaries.
- downloads the appropriate driver binaries, if not already present, into the local cache.
- downloads the latest version of the browser binary, unless otherwise specified.
- Eliminates the need to store driver binaries locally. We also need not maintain various versions of the binary driver files for different browsers.
WebDriverManager.chromedriver().setup();
driver = new ChromeDriver();
ChromeOptions chromeOptions = new ChromeOptions();
WebDriverManager.chromedriver().driverVersion(“85.0.4183.38”).setup();
WebDriverManager.chromedriver().browserVersion(“83.0.4103”).setup();
WebDriver driver = new ChromeDriver(chromeOptions);
"WebDriverManager.chromedriver().architecture(io.github.bonigarcia.wdm.Architecture.X32).setup();
Alternatively, we can also use arch32() or arch64() methods to specify binary types.
chromedriver().arch32().setup();
chromedriver().arch64().setup();"If your organization has a proxy server, you need to specify proxy server details like server name or IP address, username, and password to the WebDriverManager. Otherwise, it may raise/ cause errors like io.github.bonigarcia.wdm.WebDriverManagerException: java.net.UnknownHostException: chromedriver.storage.googleapis.com.
WebDriverManager.chromedriver()
.version(“83.0.0”)
.arch32()
.proxy(“proxyhostname:80”)
.proxyUser(“username”)
.proxyPass(“password”)
.setup();
A proxy acts as an intermediary between clients sending requests and server responding. The primary use of a proxy is to maintain privacy and encapsulation between multiple interactive systems.
A proxy can also add another layer of security on the web by acting as a firewall between Client and web servers. This is especially used when the websites that clients use have to be labeled as allowed or blocked based on the website content.
package HireQADemo;
import java.io.IOException;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class AlertsDemo {
public static void main(String args[]) throws IOException {
System.setProperty(""webdriver.chrome.driver"", ""D:\\Data_Personal\\Software\\chromedriver_win32\\chromedriver.exe"");;
WebDriver driver = new ChromeDriver();
driver.get(""http://hireqa.co.in/test/basic_auth.php"");
// Handling Username alert
driver.switchTo().alert().sendKeys(""HireQA"");
driver.switchTo().alert().accept();
// Handling Password alert
driver.switchTo().alert().sendKeys(""HireQA"");
driver.switchTo().alert().accept();
}
}In Selenium Webdriver Session ID is a unique number that is assigned to your web driver by server . Webdriver uses this session Id to interact with browser launched by them. So a browser window (eg Chrome) launched by a specific driver (chrome driver) will have a unique sessionId.
Since Eclipse is freeware tool so sometime it does not work as per your requirement and some point still point to old location in this case we can clean our project
When you face any inconsistency with Eclipse then clean your project or restart eclipse.
Step 1- Open Eclipse and Click on Project and Click on Clean
Step 2- Now you will get two options- You can select based on your choice
Clean all projects- This will clean the entire project on project explorer
1- Open Eclipse > Click on Window > Click on Preferences.
2- Click on General > Click on Appearance > Click on Color and Fonts > in right side Click on Basic.
3- Once you click on Basics > Now Select Text font and Click on Edit button.
java.lang.IllegalStateException: The path to the driver executable must be set by the webdriver.chrome.driver system property;
System.setProperty(“webdriver.chrome.driver”, “path of the exe file\\chromedriver.exe”);
// Initialize browser
WebDriver driver=new ChromeDriver();
The term Gecko stands for a Web Browser engine that is inbuilt within Mozilla Firefox browser. Gecko driver acts as a proxy between Web Driver enabled clients(Eclipse, Netbeans, etc.) and Mozilla Firefox browser. In short, Gecko driver acts as a link between Selenium Web Driver tests and Mozilla Firefox browser.
Selenium uses W3C Webdriver protocol to send requests to GeckoDriver, which translates them into a protocol named Marionette. Firefox will understand the commands transmitted in the form of Marionette protocol and executes them.
System.setProperty(“webdriver.gecko.driver”, driverPath);
DesiredCapabilities capabilities = DesiredCapabilities.firefox();
capabilities.setCapability(“marionette”,true);
driver= new FirefoxDriver(capabilities);
or
FirefoxOptions options = new FirefoxOptions();
options.setLegacy(true);
1 :- WebDriver is an Interface(interface have only function prototype) in which by default all the method (public ,static)has to declared.
2:- WebDriver handles all activity which is related to Browser.
FireFoxDriver is a Class who has implemented all the method of WebDriver Interface.
1. SearchContext is the super most interface in selenium, which is extended by another interface called WebDriver.
2. All the abstract methods of SearchContext and WebDriver interfaces are implemented in RemoteWebDriver class.
3. All the browser related classes such as FirefoxDriver, ChromeDriver etc., extends the RemoteWebdriver class.
4. All the abstract methods of both the interfaces are implemented in RemoteWebDriver class which is extended by browser classes such as Firefox Driver, Chrome Driver etc.
We cannot write our code like this because we cannot create Object of an Interface. WebDriver is an interface.
WebDriver is an interface and all the methods which are declared in Webdriver interface are implemented by respective driver class.
But if we do upcasting,we can run the scripts in any browser .i.e running the same automation scripts in different browsers to achieve Runtime Polymorphism.
WebDriver is an interface, driver is a reference variable, FirefoxDriver() is a Constructor, new is a keyword, and new FirefoxDriver() is an Object.
- Selenium Remote Webdriver: It is an class that is used to execute the browser automation and to execute assessments in a distributed environment or on a remote computing device. In other words, It is a class that implements the WebDriver interface and this action is performed on the remote server. There are different driver classes for a browser such as ChromeDriver, FirefoxDriver, etc.
- Selenium Webdriver: It helps you to interact with browsers directly with the help of some automation scripts which includes a starting point, various variables with their binding values, and the source code. It is used to give support to various platforms, and its execution is little faster as compared to that of Selenium IDE or RC. It provides multiple client libraries which can be used in different programming languages like Python, C, Java, etc. which is used to build automation for the Selenium test.
Using id – #
Using class name – .
Using attribute – tagname[attribute=’value’]
Using multiple attribute – tagname[attribute1=’value’][attribute2=’value’]
Contains – * – tagname[attribute*=’value’]
Starts with – ^ – tagname[attribute^=’value’]
Ends with – $ – tagname[attribute$=’value’]
XPath starts-with() is a function used for finding the web element whose attribute value gets changed on refresh or by other dynamic operations on the webpage. In this method, the starting text of the attribute is matched to find the element whose attribute value changes dynamically.
Xpath=//label[starts-with(@id,’message’)]
The XPath text() function is a built-in function of selenium webdriver which is used to locate elements based on text of a web element. It helps to find the exact text elements and it locates the elements within the set of text nodes.
Xpath=//td[text()=’UserID’]
XPath Contains() is a method which is used to find the value of those attribute which changes dynamically. For example, login information.
XPath=//tagname[contains(@attribute, 'value')]
XPath ends-with() method checks the ending text of an attribute and finds elements whose attribute changes dynamically on refresh. It has the following syntax as follows:
XPath= //tagname[ends-with(@attribute, 'value')]
By using clear() method
WebDriver driver = new FirefoxDriver();
driver.get(“https://www.gmail.com”);
driver.findElement(By.xpath(“xpath_of_element1”)).sendKeys(“Software Testing Material Website”);
driver.findElement(By.xpath(“xpath_of_element1”)).clear();
isDisplayed()
WebElement radioBtn = driver.findElement (By.id(“gender-male”));
radioBtn.isDisplayed // this returns a Boolean value, if it returns true then said radio button is present on the webpage or it returns False.
isEnabled()
radioBtn.isEnabled() // this returns a Boolean value, if it returns true then said radio button is enabled on the webpage or it returns False
isSelected()
radioBtn.isSelected() // this returns a Boolean value, if it returns true then said radio button is selected or it returns False
Selenium already provides Select class that has some predefined method which help is a lot while working with Dropdown.
WebElement month_dropdown=driver.findElement(By.id(“month”));
Select month=new Select(month_dropdown);
month.selectByIndex(4);
month.selectByValue(“5”);
month.selectByVisibleText("Aug");Select month=new Select(month_dropdown);
WebElement first_value=month.getFirstSelectedOption();
String value=first_value.getText();WebElement month_dropdown=driver.findElement(By.id(""month""));
Select month=new Select(month_dropdown);
List dropdown=month.getOptions();
for(int i=0;i<dropdown.size();i++){
String drop_down_values=dropdown.get(i).getText();
System.out.println(""dropdown values are ""+drop_down_values);
}The bootstrap dropdown is enhanced part of dropdown where you will deal with UL and LI tag of HTML.
List list = driver.findElementsByXPath(""//ul[@class='dropdown-menu']//li/a"");
// We are using enhanced for loop to get the elements
for (WebElement ele : list)
{
// for every elements it will print the name using innerHTML
System.out.println(""Values "" + ele.getAttribute(""innerHTML""));
// Here we will verify if link (item) is equal to Java Script
if (ele.getAttribute(""innerHTML"").contains(""JavaScript"")) {
// if yes then click on link (iteam)
ele.click();
// break the loop or come out of loop
break;
}if(dropdown.isMultiple())
{sysout(""multiple option is allowed"")}
Returns TRUE if the drop-down element allows multiple selections at a time; FALSE if otherwise.dropdown.deSelectAll();
We use click() method in Selenium to click on the hyperlink
driver.findElement(By.linkText(“Software Testing Material Website”)).click();
An exception is thrown. We need to pass HTTP protocol within driver.get() method.
Alternative method to driver.get(“url”) method is driver.navigate.to(“url”)
driver.get(): To open an URL and it will wait till the whole page gets loaded
driver.navigate.to(): To navigate to an URL and It will not wait till the whole page gets loaded
driver.navigate().forward();
driver.navigate().back();
driver.navigate().refresh();
driver.navigate().to(“url”);
Action Class in Selenium is a built-in feature provided by the selenium for handling keyboard and mouse events. It includes various operations such as multiple events clicking by control key, drag and drop events and many more.
clickAndHold() – Clicks (without releasing) at the current mouse location.
contextClick()– Performs a context-click at the current mouse location. (Right Click Mouse Action)
doubleClick() Performs a double-click at the current mouse location.
dragAndDrop(source, target) – Performs click-and-hold at the location of the source element, moves to the location of the target element, then releases the mouse.
dragAndDropBy(source, x-offset, y-offset) – Performs click-and-hold at the location of the source element, moves by a given offset, then releases the mouse.
keyDown(modifier_key) – Performs a modifier key press. Does not release the modifier key – subsequent interactions may assume it’s kept pressed.
modifier_key – any of the modifier keys (Keys.ALT, Keys.SHIFT, or Keys.CONTROL)
keyUp(modifier _key) – Performs a key release.
moveByOffset(x-offset, y-offset) – Moves the mouse from its current position (or 0,0) by the given offset.
moveToElement(toElement) – Moves the mouse to the middle of the element.
release() – Releases the depressed left mouse button at the current mouse location
sendKeys(onElement, charsequence) – Sends a series of keystrokes onto the element.
WebElement ele = driver.findElement(By.xpath(“xpath”));
//Create object ‘action’ of an Actions class
Actions action = new Actions(driver);
//Mouseover on an element
action.moveToElement(ele).perform();
Actions builder = new Actions(driver);
Action seriesOfActions = builder
.moveToElement(txtUsername)
.click()
.keyDown(txtUsername, Keys.SHIFT)
.sendKeys(txtUsername, ""hello"")
.keyUp(txtUsername, Keys.SHIFT)
.doubleClick(txtUsername)
.contextClick()
.build();
seriesOfActions.perform() ;Actions action = new Actions(driver);
action.clickAndHold(slider).moveByOffset(50,0).release();Move To Element:
Actions builder=new Actions(driver);
WebElement ele=driver.findElement(By.xpath("".//*[@id='autosuggest']/ul/li[2]/a""));
builder.moveToElement(ele).build().perform();
builder.click(ele).build().perform();
Right Click on Element:
Actions act=new Actions(driver);
act.contextClick(driver.findElement(By.linkText(“Gujarati”))).perform();
Key Down:
Actions act=new Actions(driver);
act.contextClick(driver.findElement(By.linkText(""Gujarati""))).sendKeys(Keys.ARROW_DOWN).sendKeys(Keys.ARROW_DOWN).sendKeys(Keys.ENTER).build().perform();Approach 1:
Actions act=new Actions(driver);
// find element which we need to drag
WebElement drag=driver.findElement(By.xpath("".//*[@id='draggable']""));
// find element which we need to drop
WebElement drop=driver.findElement(By.xpath("".//*[@id='droppable']""));
// this will drag element to destination
act.dragAndDrop(drag, drop).build().perform();
Approach 2:
Actions act=new Actions(driver);
// find element which we need to drag
WebElement source=driver.findElement(By.xpath(""(//span[text()='Thrillers'])[1]""));
WebElement destination=driver.findElement(By.xpath(""(//span[text()='History'])[2]""));
// it will click and hold the triller box and move to element will move cursor to history in another box and then release
act.clickAndHold(source).pause(2000).moveToElement(destination).release().build().perform();Scenario 1: Tooltip is implemented using the ""title"" attribute
WebElement github = driver.findElement(By.xpath("".//*[@class='soc-ico show-round']/a[4]""));
//get the value of the ""title"" attribute of the github icon
String actualTooltip = github.getAttribute(""title"");
Scenario 2: Tooltip is implemented using a jQuery plugin.
String expectedTooltip = ""What's new in 3.2"";
driver.get(baseUrl);
WebElement download = driver.findElement(By.xpath("".//*[@id='download_now']""));
Actions builder = new Actions (driver);
builder.clickAndHold().moveToElement(download);
builder.moveToElement(download).build().perform();
WebElement toolTipElement = driver.findElement(By.xpath("".//*[@class='box']/div/a""));
String actualTooltip = toolTipElement.getText();
System.out.println(""Actual Title of Tool Tip ""+actualTooltip);
if(actualTooltip.equals(expectedTooltip)) {
System.out.println(""Test Case Passed"");
} Web-Based alert and Java Script alerts are same so do not get confused.
Alert Interface has some methods-
1- accept()- Will click on the ok button when an alert comes.
2- dismiss()- Will click on cancel button when an alert comes.
//Captured Alert Text (Actual Text)
String actualAlertMessage = driver.switchTo().alert().getText();
//Accept the alert (Click OK)
driver.switchTo().alert().accept();
//Accept the alert (Click Cancel)
driver.switchTo().alert().dismiss();
//Send “Hire QA” to Alert’s text box
driver.switchTo().alert().sendKeys(“Hire QA”);
iFrame is a HTML document embedded inside an HTML document. iFrame is defined by an tag in HTML. With this tag, you can identify an iFrame while inspecting the HTML tree.
To Switch between iFrames we have to use the driver’s switchTo().frame command.
We can use the switchTo().frame() in three ways:
- switchTo.frame(int frameNumber): Pass the frame index and driver will switch to that frame.
- switchTo.frame(string frameName): Pass the frame element Name or ID and driver will switch to that frame.
- switchTo.frame(WebElement frameElement): Pass the frame web element and driver will switch to that frame.
//Switch by frame name
driver.switchTo().frame(“iframe1”);
//Switch by frame ID
driver.switchTo().frame(“IF1”);
//First find the element using any of locator stratedgy
WebElement iframeElement = driver.findElement(By.id(“IF1”));
//switch to frame by using frame element
driver.switchTo().frame(iframeElement);
//Switch back to the main window
driver.switchTo().defaultContent();
// It will return the parent window name as a String
String parent=driver.getWindowHandle();
// This will return the number of windows opened by Webdriver and will return Set of St//rings
Sets1=driver.getWindowHandles();
// Now we will iterate using Iterator
Iterator I1= s1.iterator();
while(I1.hasNext())
{
String child_window=I1.next();
// Here we will compare if parent window is not equal to child window then we will close
if(!parent.equals(child_window))
{
driver.switchTo().window(child_window);
System.out.println(driver.switchTo().window(child_window).getTitle());
driver.close();
}
}
// once all pop up closed now switch to parent window
driver.switchTo().window(parent);
}
}//No.of Columns
List col = wd.findElements(By.xpath(“.//*[@id=\”leftcontainer\”]/table/thead/tr/th”));
System.out.println(“No of cols are : ” +col.size());
//No.of rows
List rows = wd.findElements(By.xpath(“.//*[@id=’leftcontainer’]/table/tbody/tr/td[1]”));
System.out.println(“No of rows are : ” + rows.size());
Fetch 3rd row and 2nd cell data
———————————————-
//To find third row of table
WebElement tableRow = baseTable.findElement(By.xpath(“//*[@id=\”leftcontainer\”]/table/tbody/tr[3]”));
String rowtext = tableRow.getText();
System.out.println(“Third row of table : “+rowtext);
//to get 3rd row’s 2nd column data
WebElement cellIneed = tableRow.findElement(By.xpath(“//*[@id=\”leftcontainer\”]/table/tbody/tr[3]/td[2]”));
String valueIneed = cellIneed.getText();
System.out.println(“Cell value is : ” + valueIneed);
//No. of Columns
List col = wd.findElements(By.xpath("".//*[@id='leftcontainer']/table/thead/tr/th""));
System.out.println(""Total No of columns are : "" +col.size());
//No.of rows
List rows = wd.findElements(By.xpath ("".//*[@id='leftcontainer']/table/tbody/tr/td[1]""));
System.out.println(""Total No of rows are : "" + rows.size());
for (int i =1;ir)
{
r=m;
}
}
System.out.println(""Maximum current price is : ""+ r);Desired Capabilities are needed because every Testing scenario should be executed on some specific testing environment. The testing environment can be a web browser, Mobile device, mobile emulator, mobile simulator, etc. The Desired Capabilities Class helps us to tell the webdriver, which environment we are going to use in our test script.
//it is used to define IE capability
DesiredCapabilities capabilities = DesiredCapabilities.internetExplorer();
capabilities.setCapability(CapabilityType.BROWSER_NAME, "IE");
capabilities.setCapability(InternetExplorerDriver.INTRODUCE_FLAKINESS_BY_IGNORING_SECURITY_DOMAINS,true);
System.setProperty("webdriver.ie.driver", "C:\\IEDriverServer.exe");
//it is used to initialize the IE driver
WebDriver driver = new InternetExplorerDriver(capabilities);ChromeOptions is a class that can be used to manipulate capabilities specific to ChromeDriver. For instance, you can disable Chrome extensions with:
ChromeOptions options = new ChromeOptions()
options.addArgument(“disable-extensions”);
ChromeDriver driver = new ChromeDriver(options);
DesiredCapabilities can also be used to manipulate a ChromeDriver session. To change individual web driver properties, DesiredCapabilities class provides key-value pairs.
But, ChromeOptions supports limited clients whereas DesiredCapabilities supports a vast number of clients. ChromeOptions is supported by Java and other languages. DesiredCapabilities is available in Java, but its use is deprecated. When working with a client library, like Selenium Ruby Client, the ChromeOption class will not be available and DesiredCapabilities will have to be used.
DesiredCapabilities are commonly used with Selenium Grid, for parallel execution of test cases on different browsers. However, one can use both DesiredCapabilities and ChromeOptions using merge:
DesiredCapabilities capabilities = new DesiredCapabilities();
options = new ChromeOptions();
options.merge(capabilities);
driver = new ChromeDriver(options);
driver.get(""http://www.google.co.in/"");
List links=driver.findElements(By.tagName(""a""));
System.out.println(""Total links are ""+links.size());
for(int i=0;i<links.size();i++)
{
WebElement ele= links.get(i);
String url=ele.getAttribute(""href"");
verifyLinkActive(url);
----------------------------------------------
public static void verifyLinkActive(String linkUrl)
{
try
{
URL url = new URL(linkUrl);
HttpURLConnection httpURLConnect=(HttpURLConnection)url.openConnection();
httpURLConnect.setConnectTimeout(3000);
httpURLConnect.connect();
if(httpURLConnect.getResponseCode()==200)
{
System.out.println(linkUrl+"" - ""+httpURLConnect.getResponseMessage());
}
if(httpURLConnect.getResponseCode()==HttpURLConnection.HTTP_NOT_FOUND)
{
System.out.println(linkUrl+"" - ""+httpURLConnect.getResponseMessage() + "" - ""+ HttpURLConnection.HTTP_NOT_FOUND);
}
} catch (Exception e) {
}
} During test execution, the Selenium WebDriver has to interact with the browser all the time to execute given commands. At the time of execution, it is also possible that, before current execution completes, someone else starts execution of another script, in the same machine and in the same type of browser.
In such situation, we need a mechanism by which our two different executions should not overlap with each other. This can be achieved using Session Handling in Selenium.
To work with Basic Authentication pop-up (which is a browser dialogue window), you just need to send the user name and password along with the application URL.
#1 (Chrome & Firefox)
By passing user credentials in URL. Its simple, append your username and password with the URL.
e.g., http://Username:Password@SiteURL
http://rajkumar:myPassword@www.softwaretestingmaterial.com
#2 (IE)
First create AutoIt script as below and save it as basicauth.au3
To pass user name and password
WinWaitActive(“Windows Security”)
Send(“admin”)
Send(“{TAB}”)
Send(“admin”)
Send(“{ENTER}”)
————————————————–
try {
Runtime.getRuntime().exec(“G:/basicauth.exe”);
} catch (Exception e) {
e.printStackTrace();
}
//Create an object of File class to open xlsx file
File file = new File(filePath+""\\""+fileName);
//Create an object of FileInputStream class to read excel file
FileInputStream inputStream = new FileInputStream(file);
Workbook workBook = null;
//Find the file extension by splitting file name
String fileExtensionName = fileName.substring(fileName.indexOf("".""));
//Check condition if the file is xlsx file
if(fileExtensionName.equals("".xlsx"")){
workBook = new XSSFWorkbook(inputStream);
} else if(fileExtensionName.equals("".xls"")){
workBook = new HSSFWorkbook(inputStream);
}
//Read sheet inside the workbook by its name
Sheet sheet = workBook.getSheet(sheetName);
//Find number of rows in excel file
int rowCount = sheet.getLastRowNum()-sheet.getFirstRowNum();
//Create a loop over all the rows of excel file to read it
for (int i = 0; i < rowCount+1; i++) {
Row row = sheet.getRow(i);
//Create a loop to print cell values in a row
for (int j = 0; j < row.getLastCellNum(); j++) {
//Print Excel data in console
System.out.print(row.getCell(j).getStringCellValue()+""|| "");
File file = new File(filePath+""\\""+fileName);
FileInputStream inputStream = new FileInputStream(file);
Workbook workBook = null;
workBook = new XSSFWorkbook(inputStream);
Sheet sheet = workBook .getSheet(sheetName);
int rowCount = sheet.getLastRowNum()-sheet.getFirstRowNum();
Row row = sheet.getRow(0);
//Create a new row and append it at last of sheet
Row newRow = sheet.createRow(rowCount+1);
for(int j = 0; j < row.getLastCellNum(); j++){
Cell cell = newRow.createCell(j);
cell.setCellValue(dataToWrite[j]);
inputStream.close();
FileOutputStream outputStream = new FileOutputStream(file);
workBook.write(outputStream);
outputStream.close();Create a new file and give file name as Object_Repo (depends on you)with extension .properties
// Specify the file location I used . operation here because
//we have object repository inside project directory only
File src=new File("".Object_Repo.properties"");
// Create FileInputStream object
FileInputStream fis=new FileInputStream(src);
// Create Properties class object to read properties file
Properties pro=new Properties();
// Load file so we can use into our script
pro.load(fis);
System.out.println(""Property class loaded"");
// Open FirefoxBrowser
WebDriver driver=new FirefoxDriver();
// Maximize window
driver.manage().window().maximize();
// Pass application
driver.get(""http://www.facebook.com"");
// Enter username here I used keys which is specified in Object repository.
// Here getProperty is method which
// will accept key and will return value for the same
driver.findElement(By.xpath(pro.getProperty(""facebook.login.username.xpath""))).
sendKeys(""Selenium@gmail.com"");Selenium Webdriver is limited to Testing your applications using Browser. To use Selenium Webdriver for Database Verification you need to use the JDBC (“Java Database Connectivity”).
JDBC (Java Database Connectivity) is a SQL level API that allows you to execute SQL statements. It is responsible for the connectivity between the Java Programming language and a wide range of databases. The JDBC API provides the following classes and interfaces
Driver Manager
Driver
Connection
Statement
ResultSet
SQLException
//You also need to load the JDBC Driver using the code
Class.forName("com.mysql.jdbc.Driver");
Connection con = DriverManager.getConnection(dbUrl,username,password);
ex URL: jdbc:mysql://localhost:3036/emp
"//You can use the Statement Object to send queries.
Statement stmt = con.createStatement();
//Once the statement object is created use the executeQuery method to execute the SQL queries:
ResultSet rs = stmt.executeQuery(select * from employee;);
while (rs.next()){
String myName = rs.getString(1);
String myAge = rs.getString(2);
System. out.println(myName+"" ""+myAge);
}
// closing DB Connection
con.close();
Results from the executed query are stored in the ResultSet Object.
JAVA provides loads of advanced methods to process the results:
- String getString() – to fetch the string type data from resultset.
- int getInt() – to fetch the integer type data from resultset
- double getDouble() – to fetch double type data from resultset
- Date getDate() – to fetch Date type object from resultset
- boolean next() – moves to the next record in the resultset
- boolean previous() – move to the previous record in the resultset
- boolean first() – moves to the first record in the resultset
- boolean last() – moves to the last record in the resultset
- bolean absolute – to move to specific record in the resultset
//Convert web driver object to TakeScreenshot
TakesScreenshot screenshot=((TakesScreenshot)driver);
//Call getScreenshotAs method to create image file
File SrcFile=screenshot.getScreenshotAs(OutputType.FILE);
//Copy file to Desired Location
FileUtils.copyFile(SrcFile, DestFilePath);10 seconds ImplicitlyWait for a element is not a valid statement. Explicit Wait of 5 second you have to put for a certain state/behavior of the element (e.g. element_to_be_clickable). If the element doesn’t shows that behavior within the defined time slot Selenium will throw an exception.
Using explicit wait/implicit wait is the best practice, Lets check what actually the explicit wait,Thread.sleep(), Implicit wait’s working logic.
Explicit wait: An explicit waits is a kind of wait for a certain condition to occur before proceeding further in the code.
Implicit wait: An implicit wait is to tell WebDriver to poll the DOM for a certain amount of time when trying to find an element or elements if they are not immediately available. The default setting is 0
Thread.sleep() In sleep code will always wait for mentioned seconds in side the parentheses even in case working page is ready after 1 sec. So this can slow the tests.
System.setProperty(""webdriver.chrome.driver"", ""D:\\softwares\\chromedriver_win32\\chromedriver.exe"");
WebDriver driver = new ChromeDriver();
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
driver.manage().window().maximize();
driver.get(""https://mail.google.com/"");
String selectLinkOpeninNewTab = Keys.chord(Keys.CONTROL,Keys.RETURN);
//driver.findElement(By.linkText(""www.facebook.com"")).sendKeys(selectLinkOpeninNewTab);
driver.findElement(By.linkText(""www.facebook.com"")).sendKeys(Keys.CONTROL +""t"");
----------------------------------------------------------------------------
WebDriver driver = new ChromeDriver();
driver.get(""http://yahoo.com"");
((JavascriptExecutor)driver).executeScript(""window.open()"");
ArrayList tabs = new ArrayList(driver.getWindowHandles());
driver.switchTo().window(tabs.get(1));
driver.get(""http://google.com"");1. Use Actions() method
WebElement element = driver.findElement(By(“element_path”));
Actions actions = new Actions(driver);
actions.moveToElement(element).click().perform();
————————————————————————-
2. Use Waits to let the page load completely before the click is performed
driver.manage().timeouts().implicitlywait(15 TimeUnit.seconds)
———————————————————————–
3. The element is not clickable because of a Spinner/Overlay on top of it:
By loadingImage = By.id(“loading image ID”);
WebDriverWait wait = new WebDriverWait(driver, timeOutInSeconds);
wait.until(ExpectedConditions.invisibilityOfElementLocated(loadingImage));
WebElement element = driver.findElement(By.id(“gbqfd”));
JavascriptExecutor js= (JavascriptExecutor)driver;
js.executeScript(“arguments[0].click();”, element);
driver.get(“https://www.hireqa.co.in”);
List list= driver.findElements(By.className(“store-name”));
System.out.println(list.size());
for (WebElement webElement : list) {
String name = webElement.getText();
System.out.println(name);
}
JavascriptExecutor js = ((JavascriptExecutor)driver);
js.executeScript(""window.scrollTo(0, document.body.scrollHeigh)"").;
js.executeScript(""arguments[0].scrollIntoView(true);"",element);
js.executeScript(""window.scrollBy(0,500)"");
String output = driver.findElement(By.xpath(“/html/body/div[1]/div[5]/div/div/div[1]/div[2]/div[1]/div”)).getText();
File DestFile= new File(“extractedFilePath”);
FileUtils.writeStringToFile(DestFile, output);
Robot robot = new Robot();
StringSelection filepath = new StringSelection(""file path"");
Toolkit.getDefaultToolkit().getSystemClipboard().setContents(filepath,null);
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_ENTER);
robot.keyRelease(KeyEvent.VK_ENTER);DesiredCapabilities cap = DesiredCapabilities.chrome();
cap.acceptInsecureCert();
cap.setCapability(CapabilityType.ACCEPT_INSECURE_CERTS, true);
cap.setCapability(CapabilityType.ACCEPT_SSL_CERTS, true);
ChromeOptions options = new ChromeOptions();
options.merge(cap);
WebDriverManager.chromeDriver.setup();
WebDriver driver = new ChromeDriver(options);
----------------------------------------------------------
FirefoxOption options = new FirefoxOptions();
FirefoxProfile profile = new FirefoxProfile();
profile.setAcceptUntrustedCertificates(true);
options.setProfile(profile);
WebDriverManager.firefoxDriver.setUp();
WebDriver driver = new FirefoxDriver(options);System.out.println(((RemoteWebDriver)driver).getCapabilities().toString();
WebDriverWait by default calls the ExpectedCondition every 500 milliseconds until it returns successfully hence the default polling time for ExplicitWait is 500 milliseconds.
An implicit wait is to tell Web Driver to poll the DOM for a certain amount of time when trying to find an element or elements if they are not immediately available. The default setting is 0. Once set, the implicit wait is set for the life of the Web Driver object instance until it changed again.
driver.manage () is a method that returns instance of options interface, now the options interface has method window () that returns instance of window interface, this window interface has method maximize () which maximizes the window.
get() is used to navigate particular URL (website) and wait till page load. driver. navigate() is used to navigate to particular URL and does not wait to page load. It maintains browser history or cookies to navigate back or forward.
Both click () and submit () both are used to click Button in Web page. Selenium WebDriver has one special method to submit any form and that method name Is submit (). submit () method works same as clicking on submit button. You can use .click () method to click on any button. There is no restriction for click buttons.
Solution 1: Refreshing the web page
Solution 2: Using Try Catch Block
Solution 3: Using Explicit Wait
Solution 4: Using PageFactory
We could avoid StaleElementException using POM. In POM, we use initElements() method which loads the element but it won’t initialize elements. initElements() takes latest address. It initializes during run time when we try to perform any action on an element. This process is also known as Lazy Initialization.
Here we are creating an object of the ChromeDriver() by taking reference to the WebDriver interface.
| ABSTRACTION In Page Object Model design pattern, we write locators (such as id, name, xpath etc.,) in a Page Class. We utilize these locators in tests but we can’t see these locators in the tests. Literally we hide the locators from the tests. Abstraction is the methodology of hiding the implementation of internal details and showing the functionality to the users. |
| INTERFACE WebDriver driver = new FirefoxDriver(); we are initializing Firefox browser using Selenium WebDriver. It means we are creating a reference variable (driver) of the interface (WebDriver) and creating an Object. Here WebDriver is an Interface as mentioned earlier and FirefoxDriver is a class. An interface can have methods and variables just like the class but the methods declared in interface are by default abstract. |
| INHERITANCE We create a Base Class in the Framework to initialize WebDriver interface, WebDriver waits, Property files, Excels, etc., in the Base Class. We extend the Base Class in other classes such as Tests and Utility Class. Extending one class into other class is known as Inheritance. |
| POLYMORPHISM Combination of overloading and overriding is known as Polymorphism. We will see both overloading and overriding below. Polymorphism allows us to perform a task in multiple ways. |
| METHOD OVERLOADING We use implicit wait in Selenium. Implicit wait is an example of overloading. In Implicit wait we use different time stamps such as SECONDS, MINUTES, HOURS etc., A class having multiple methods with same name but different parameters is called Method Overloading |
| METHOD OVERLOADING We use implicit wait in Selenium. Implicit wait is an example of overloading. In Implicit wait we use different time stamps such as SECONDS, MINUTES, HOURS etc., A class having multiple methods with same name but different parameters is called Method Overloading |
| ENCAPSULATION In POM classes, we declare the data members using @FindBy and initialization of data members will be done using Constructor to utilize those in methods. Encapsulation is a mechanism of binding code and data together in a single unit. |
ChromeOptions options = new ChromeOptions();
options.addArguments(“disable-infobars”);
WebDriver player = new ChromeDriver(options);
The parallel attribute of suite tag can accept four values:
tests – All the test cases inside tag of testng.xml file will run parallel
classes – All the test cases inside a java class will run parallel
methods – All the methods with @Test annotation will execute parallel
instances – Test cases in same instance will execute parallel but two methods of two different instances will run in different thread.
By adding the exclude tag in the testng.xml
By adding the exclude tag in the testng.xml
@Test(enabled = false)
Using attributes dependsOnMethods in @Test annotations.
@Test(dependsOnMethods = {""testCase2""})
Using attributes dependsOnGroups in @Test annotations.
The invocationcount attribute tells how many times TestNG should run a test method.
@Test(invocationCount = 10)
public void testCase1(){
The threadPoolSize attribute tells to form a thread pool to run the test method through multiple threads.
Note: This attribute is ignored if invocationCount is not specified.
@Test(threadPoolSize = 3, invocationCount = 10) public void testCase1(){
In this example, the method testCase1 will be invoked from three different threads
@Test(threadPoolSize = 3, invocationCount = 10, timeOut = 10000)
public void testCase1(){
In this example, the function testCase1 will be invoked ten times from three different threads. Additionally, a time-out of ten seconds guarantees that none of the threads will block on this thread forever.
@Test (dataProvider=""getData"")
// Number of columns should match the number of input parameters
public void loginTest(String Uid, String Pwd){
System.out.println(""UserName is ""+ Uid);
System.out.println(""Password is ""+ Pwd);
}
@DataProvider(name=""getData"")
public Object[][] getData(){
//Object [][] data = new Object [rowCount][colCount];
Object [][] data = new Object [2][2];
data [0][0] = ""FirstUid"";
data [0][1] = ""FirstPWD"";
data[1][0] = ""SecondUid"";
data[1][1] = ""SecondPWD"";
return data;
}WebDriver driver = new HtmlUnitDriver()
Fastest implementation of WebDriver compared to other browsers
A pure Java solution and so it is platform independent.
Supports JavaScript
It allows you to choose other browser versions to run your scripts.
| JavaScript In HtmlUnit Driver: HtmlUnitDriver uses Rhino JavaScript engine. Other browsers are using separate JavaScript engine. So the test results may differ when compared to other browsers when you test JavaScript applications using HtmlUnit. By default, JavaScript is disabled in HtmlUnitDriver. Don’t worry, there is a way to enable it. |
| Enabling JavaScript while initializing the HtmlUnitDriver: HtmlUnitDriver driver = new HtmlUnitDriver(true); Setting ‘setJavascriptEnabled’ to true HtmlUnitDriver driver = new HtmlUnitDriver(); setJavascriptEnabled(true); |
@Test(expectedExceptions = ArithmeticException.class)
public void testException() {
System.out.println(""SoftwareTestingMaterial.com"");
int i = 1 / 0;
}"
----------------------------------------------------------------------------------------
@Test
@Parameters(""browser"")
public void parameterizedTest(String browser){"REST Assured is a Java library that offers programmers a domain-specific language (DSL) to write maintainable, robust tests for RESTful APIs. It is widely used to test web applications based on JSON and XML. Additionally, it supports all methods, including GET, DELETE, PUT, POST, and PATCH.
REST is an acronym for “representational state transfer.” It’s a design pattern or architectural style for APIs. A RESTful web application reveals information about itself as resource information.
JSON stands for “JavaScript Object Notation” which is a lightweight , language independent and self describing format in text for data storing and interchange. JSON is easy to read, write and create for humans which makes it famous over XML.
JSON was derived from JavaScript but now it is supported by many languages. A file containing JSON is saved using “.json” extension.
When we want to create a new resource or say want to add a new student details in to a student database, we need to send a POST request with a payload to API end point. This payload can be a JSON format. So , JSON is majorly used to exchange data between Web Server and Client.
An example JSON is below:-
{
“firstName”:”Phani”,
“lastName”:”Nagula”,
“age”: 45,
“salary”: 00.01
}
As you see above, JSON stores data as a key-value pair. Key is left side and value is right side and a semi colon is used to separate both. One key-value pair is separated with another key-value pair using comma (,).
A key is always a string and a string must be enclosed in double quotes. A value can be a string, number ( With decimal and without decimal ), a Boolean ( true and false) , an object , an array or a null.
JSON can be found in two formats :- JSON Object and JSON Array.
A JSON Object is an unordered data structure which starts with opening braces ( ‘{‘) and ends with a closing braces (‘}’). A JSON Array is a ordered collection which starts with opening bracket ( ‘[‘) and ends with a closing bracket(‘]’). A JSON array consists of values separated by comma. A JSON array can be hold multiple JSON Objects as well.
RESTful web services use the HTTP protocol to communicate between the client and the server.
The REST architecture treats any content as a resource. This content includes HTML pages, text files, images, videos, or dynamic business information. A REST Server gives users access to these resources and modifies them, and URIs or global IDs identify each resource.
In the context of object-oriented programming languages, method chaining is an often-used syntax for invoking any number of method calls. Each method returns an object, so multiple calls can be chained together in a single line. This characteristic means that variables aren’t needed to hold interim results.
Because REST Assured can customize reports, Postman can’t do this. Additionally, since REST Assured is a Java client, you can reuse code, which Postman doesn’t allow. Finally, REST Assured has no restrictions on data file submission for collections, whereas Postman is limited to one data file.
Request specification in REST Assured is used to group common request specs and change them into a single object. This interface has the means to define the base URL, headers, base path, and other parameters. You must use the given() function of the REST Assured class to obtain a reference for the Request specification.
A RequestSpecification with some specifications can be created as below:-
RequestSpecification requestSpecification = RestAssured.given();
requestSpecification.baseUri(“https://hireqa.co.in”)
requestSpecification.basePath(“/register”);
Or instead of calling RequestSpecification reference multiple times, we can use the builder pattern as below:-
RequestSpecification requestSpecification = RestAssured.given()
.baseUri(“https://restful-booker.herokuapp.com”)
.basePath(“/booking”);
We can add a RequestSpecification to a request in multiple ways as shown below:-
RestAssured.given(requestSpecification)
OR
RestAssured.given().spec(requestSpecification)
import org.testng.annotations.Test;
import io.restassured.RestAssured;
import io.restassured.http.Method;
import io.restassured.response.Response;
import io.restassured.specification.RequestSpecification;
public class EmployeesTest {
@Test
public void GetAllEmoloyees()
{
// base URL to call
RestAssured.baseURI = "http://localhost:8080/employees/get";
//Provide HTTP method type - GET, and URL to get all employees
//This will give respose
Response employeesResponse = RestAssured.given().request(Method.GET, "/all");
// Print the response in string format
System.out.println(employeesResponse.getBody().asString());
}
}Use a blacklist to prevent sensitive data from appearing in the log. Here’s how:
Set headers = new HashSet();
headers.add("X-REGION");
headers.add("content-type");
given().baseUri("http://localhost:8080").header("X-REGION", "NAM")
// blacklist headers
.config(config.logConfig(LogConfig.logConfig().blacklistHeaders(headers)))
// blacklist multiple headers
.config(config().logConfig(LogConfig.logConfig().blacklistHeader("Accept","set-cookie")))
.log().all()
.when()
.get("/employees")
.then()
.assertThat()
.statusCode(200);A JsonPath (io.restassured.path.json.JsonPath) is an easy way to get values from an Object document without resorting to XPath. It conforms to the Groovy GPath syntax when it retrieves an object from a document. Consider it a JSON-specific version of XPath. Here’s an example:
{
"company":{
"employee":[
{
"id":1,
"name":"User1",
"role":"Admin"
},
{
"id":2,
"name":"User2",
"role":"User"
},
{
"id":3,
"name":"User3",
"role":"User"
}
]
}
}Response employeesResponse = RestAssured.given().request(Method.GET, "/all");
JsonPath jsonPathObj = employeesResponse.jsonPath();
//get a list of all employees id:
List employeeIds = jsonPathObj.get("company.employee.id");
//get the first employee name:
String empName = jsonPathObj.get("company.employee[0].name");If the test validation fails, log().ifValidationFails() will log everything in a request and response.
@Test
public void testIfValidationFails() {
given().
baseUri("http://localhost:8080").
header("X-REGION", "NAM").
log().ifValidationFails().
when().
get("/employees").
then().
log().ifValidationFails().
assertThat().
statusCode(200);
}Response employeesResponse = RestAssured.given().request(Method.GET, “/all”);
JsonPath jsonPathObj = employeesResponse.jsonPath();
//get all employees id between 15 and 300
List employees = jsonPathObj.get(“company.employee
.findAll { employee -> employee.id >= 15 && employee.id <= 300 }");Static import is a Java programming language function that lets members (e.g., fields and methods) scoped as public static within their container class to be employed in Java code without mentioning the field’s defined class.
import static io.restassured.RestAssured.*;
public class EmpControllerTest {
@Test
public void testGetEmployees() {
// with static import
given();
// without static import
/**
* import io.restassured.RestAssured;
* RestAssured.given();
*/
}
}Serialization is defined as the process of changing an object’s state into a byte stream. On the other hand, deserialization is the process of recreating the Java object in memory using the byte stream. This approach keeps the object alive.
RequestSpecBuilder is a class in Rest Assured, which contains methods to set cookies, headers, multipart details, body, authentication, form parameters, query parameters, path parameters, base path, base URI, proxy, etc. These all are required to construct a Requestspecification. After adding all required details, we need to use “build()” method of RequestSpecBuilder class to get a RequestSpecification reference.
// Creating an object of RequestSpecBuilder
RequestSpecBuilder reqBuilder = new RequestSpecBuilder();
// Setting Base URI
reqBuilder.setBaseUri(“https://restful-booker.herokuapp.com”);
// Setting Base Path
reqBuilder.setBasePath(“/booking”);
// Getting RequestSpecification reference using builder() method
RequestSpecification reqSpec = reqBuilder.build();
// We can directly call http verbs on RequestSpecification
Response res1= reqSpec.get();
System.out.println(res1.asString());
or
// We can also pass RequestSpecification reference variable in overloaded given() method
Response res2 = RestAssured.given(reqSpec).get();
System.out.println(res2.asString());
or
// We can also pass RequestSpecification using spec() method
Response res3 = RestAssured.given().spec(reqSpec).get();
System.out.println(res3.asString());
RequestSpecification req= RestAssured.given()
.accept(ContentType.JSON)
.auth().preemptive().basic("username", "password")
.header("headername", "headervalue")
.param("paramname", "paramvalue")
.cookie("cookieName", "value");Rest Assured allows you to arrange your test script in BDD style using Given, When and Then.
Prerequisites to perform Request:- GIVEN
E.g.- Setting the Base URI, Base Path, Content Type , Request body (Payload) , cookies, headers , authentication , params etc.
Performing Request :- WHEN
E.g:- Which HTTP request to hit i.e. HTTP verbs – GET, POST etc
Verification and extracting response post hitting :- THEN
E.g. Verify status code, response data, log, extracting data etc.
// Given
RestAssured.given()
.baseUri("https://hireqa.co.in")
// When
.when()
.get("/register")
// Then
.then()
.statusCode(200)
.statusLine("HTTP/1.1 200 OK")
// To verify register count
.body("registerid", Matchers.hasSize(10))
// To verify booking id at index 3
.body("registerid[3]", Matchers.equalTo(1)); // There is no need to add escape character manually. Just paste string within double
// quotes. It will automatically add escape sequence as required.
String jsonString = "{\"username\" : \"admin\",\"password\" : \"password123\"}";
//GIVEN
RestAssured
.given()
.baseUri("https://hireqa.co.in/register")
.contentType(ContentType.JSON)
.body(jsonString)
// WHEN
.when()
.post()
// THEN
.then()
.assertThat()
.statusCode(200)
.body("token", Matchers.notNullValue())
.body("token.length()", Matchers.is(15))
.body("token", Matchers.matchesRegex("^[a-z0-9]+$")); //GIVEN
RestAssured
.given()
.baseUri("https://hireqa.co.in/register/1")
.cookie("token", "12345678")
.contentType(ContentType.JSON)
.body(jsonString)
// WHEN
.when()
.put()
// THEN
.then()
.assertThat()
.statusCode(200)
.body("firstname", Matchers.equalTo("Phani"))
.body("lastname", Matchers.equalTo("Nagula"));RestAssured
.given()
.baseUri("https://hireqa.co.in/register/1")
.cookie("token", "12345678")
.contentType(ContentType.JSON)
.body(jsonString)
// WHEN
.when()
.patch()
// THEN
.then()
.assertThat()
.statusCode(200)
.body("firstname", Matchers.equalTo("Phani"))
.body("lastname", Matchers.equalTo("Nagula")); //GIVEN
RestAssured
.given()
.baseUri("https://hireqa.co.in/register/1")
.cookie("token", "12345678")
// WHEN
.when()
.delete()
// THEN
.then()
.assertThat()
.statusCode(204);
// Verifying booking is deleted
// Given
RestAssured
.given()
.baseUri("https://hireqa.co.in/register/1")
// When
.when()
.get()
// Then
.then()
.statusCode(404);Rest Assured provides below methods to get a response as:-
- As byte array :- asByteArray()
- As input stream :- asInputStream()
- As string :- asString()
All the above methods output can be used to write into a JSON file.
// Create a request specification
RequestSpecification request = RestAssured.given();
// ContentType is an ENUM.
.contentType(ContentType.JSON)
// Adding URI
.baseUri("https://hireqa.co.in/auth")
// Adding body as string
.body(jsonString)
Response response = request .when().post();
// Getting response as a string and writing in to a file
String responseAsString = response.asString();
// Converting in to byte array before writing
byte[] responseAsStringByte = responseAsString.getBytes();
// Creating a target file
File targetFileForString = new File("D:/RestAssured/targetFileForString.json");
// Writing into files
Files.write(responseAsStringByte, targetFileForString);
// Getting response as input stream and writing in to a file
InputStream responseAsInputStream = response.asInputStream();
// Creating a byte array with number of bytes of input stream
byte[] responseAsInputStreamByte = new byte[responseAsInputStream.available()];
// Reads number of bytes from the input stream and stores them into the byte
// array responseAsInputStreamByte.
responseAsInputStream.read(responseAsInputStreamByte);
// Creating a target file
File targetFileForInputStream = new File(D:/RestAssured/targetFileForInputStream.json");
// Writing into files
Files.write(responseAsInputStreamByte, targetFileForInputStream);
// Directly getting a byte array
byte[] responseAsByteArray = response.asByteArray();
// Creating a target file
File targetFileForByteArray = new File("D:/RestAssured/targetFileForByteArray.json");
// Writing into files
Files.write(responseAsByteArray, targetFileForByteArray);// Creating request specification using given()
RequestSpecification request1= RestAssured.given();
// Setting Base URI
request1.baseUri(“https://hireqa.co.in”);
// Setting Base Path
request1.basePath(“/booking”);
// We can directly call http verbs on RequestSpecification
Response res1= request1.get();
System.out.println(res1.asString());
// We can also pass RequestSpecification reference variable in overloaded given() method
Response res2 = RestAssured.given(request1).get();
System.out.println(res2.asString());
// We can also pass RequestSpecification using spec() method
Response res3 = RestAssured.given().spec(request1).get();
System.out.println(res3.asString());
To query or retrieve details from RequestSpecification, Rest Assured provides a class named SpecificationQuerier. This class has a static method called query(RequestSpecification specification) which returns reference of QueryableRequestSpecification interface. This interface has methods to retrieve request details such as getBasePath(), getBody() etc.
// Creating request specification using given()
RequestSpecification request1= RestAssured.given();
// Setting Base URI
request1.baseUri("https://hireqa.co.in")
// Setting Base Path
.basePath("/register")
.body(JsonBody)
.header("header1", "headerValue1")
.header("header2", "headerValue2");
// Querying RequestSpecification
// Use query() method of SpecificationQuerier class to query
QueryableRequestSpecification queryRequest = SpecificationQuerier.query(request1);
// get base URI
String retrieveURI = queryRequest.getBaseUri();
System.out.println("Base URI is : "+retrieveURI);
// get base Path
String retrievePath = queryRequest.getBasePath();
System.out.println("Base PATH is : "+retrievePath);
// get Body
String retrieveBody = queryRequest.getBody();
System.out.println("Body is : "+retrieveBody);
// Get Headers
Headers allHeaders = queryRequest.getHeaders();
System.out.println("Printing all headers: ");
for(Header h : allHeaders)
{
System.out.println("Header name : "+ h.getName()+" Header value is : "+h.getValue());
}Suppose you have a request payload (JSON or XML) in a file and you required to directly send that file as a payload to request in stead of reading it first and then passing. Sending file as a payload directly is a good idea when you have static payloads or minimal modification.
“body()” method of RequestSpecification interface is a overloaded method to allow you to pass payload in different ways. We will use body() method which accepts “File” as argument.
// Creating a File instance
File jsonFile = new File("D:/RestAssured/jsonPayload.json");
//GIVEN
RestAssured
.given()
.baseUri("https://hireqa.co.in")
.contentType(ContentType.JSON)
.body(jsonFile)
// WHEN
.when()
.post()
// THEN
.then()
.assertThat()
.statusCode(200)
.body("token", Matchers.notNullValue())
.body("token.length()", Matchers.is(15))
.body("token", Matchers.matchesRegex("^[a-z0-9]+$"));When a request is sent to a server, it responds with a response. The amount of time taken between sending a request to server and retrieving a response back form a server is called Response Time. An API must be faster. As a part of API testing, we must check the response time as well.
- If you just want to retrieve response time in milliseconds or other time units, you need to use time(), getTime(), timeIn(TimeUnit timeunit), getTimeIn( TimeUnit timeunit ) from Response interface. Response interface inherits these methods from ResponseOptions. You can not use Matchers in above methods.
- If you want to use Matchers i.e. assertion like response time is greater than a specific value, you need to use overloaded time() methods from ValidatableResponse which inherits time() method from ValidatableResponseOptions interface.
Interface ResponseOptions contains four methods :-
- getTime() – The response time in milliseconds (or -1 if no response time could be measured)
- getTimeIn(TimeUnit timeunit) – The response time in the given time unit (or -1 if no response time could be measured)
- time() – The response time in milliseconds (or -1 if no response time could be measured)
- timeIn( TimeUnit timeunit ) – The response time in the given time unit (or -1 if no response time could be measured)
// Create a request specification
RequestSpecification request= RestAssured.given();
// Setting content type to specify format in which request payload will be sent.
// ContentType is an ENUM.
request.contentType(ContentType.JSON);
//Adding URI
request.baseUri("https://hireqa.co.in/register");
// Adding body as string
request.body(jsonString);
// Calling POST method on URI. After hitting we get Response
Response response = request.post();
// By default response time is given in milliseconds
long responseTime1 = response.getTime();
System.out.println("Response time in ms using getTime():"+responseTime1);
// we can get response time in other format as well
long responseTimeInSeconds = response.getTimeIn(TimeUnit.SECONDS);
System.out.println("Response time in seconds using getTimeIn():"+responseTimeInSeconds);
// Similar methods
long responseTime2 = response.time();
System.out.println("Response time in ms using time():"+responseTime2);
long responseTimeInSeconds1 = response.timeIn(TimeUnit.SECONDS);
System.out.println("Response time in seconds using timeIn():"+responseTimeInSeconThis ValidatableResponseOptions interface has overloaded time() methods which accepts Matcher.
- time(Matcher matcher) – Validate that the response time (in milliseconds) matches the supplied matcher.
- time(Matcher macther, TimeUnit timeunit) – Validate that the response time matches the supplied matcher and time unit.
// Calling POST method on URI. After hitting we get Response
Response response = request.post();
// Getting ValidatableResponse type
ValidatableResponse valRes = response.then();
// Asserting response time is less than 2000 milliseconds
// L just represent long. It is in millisecond by default.
valRes.time(Matchers.lessThan(2000L));
// Asserting response time is greater than 2000 milliseconds
valRes.time(Matchers.greaterThan(2000L));
// Asserting response time in between some values
valRes.time(Matchers.both(Matchers.greaterThanOrEqualTo(2000L)).and(Matchers.lessThanOrEqualTo(1000L)));
// If we want to assert in different time units
valRes.time(Matchers.lessThan(2L), TimeUnit.SECONDS);We can create a JSON Object using a Map in Java. You must note here that I am using the word “JSON Object”. A JSON Object is a key-value pair and can be easily created using a Java Map. A Map in Java also represents a collection of key-value pairs.
{
“username” : “Phani”,
“lastname” : “Nagula”
}
Map mapPayload = new HashMap();
mapPayload .put("username", "Phani");
mapPayload .put("lastname", "Nagula");
RestAssured
.given()
.baseUri("https://hireqa.co.in/register")
.contentType(ContentType.JSON)
.body(mapPayload )
.log()
.all()
// WHEN
.when()
.post()
// THEN
.then()
.assertThat()
.statusCode(200)
.log()
.all();Example Json Array Object:
[
{
"firstname" : "Phani",
"lastname" : "Nagula"
}
{
"firstname" : "Swapna",
"lastname" : "Nalla"
}
]
====================================
Map objectOne = new HashMap();
objectOne.put("firstname","Phani");
objectOne.put("lastname", "Nagula");
Map objectTwo = new HashMap();
objectOne.put("firstname","Swapna");
objectOne.put("lastname", "Nalla");
// Creating JSON array to add both JSON objects
List<Map> jsonArrayPayload = new ArrayList();
jsonArrayPayload.add(objectOne);
jsonArrayPayload.add(objectTwo);
//GIVEN
RestAssured
.given()
.baseUri("https://hireqa.co.in/register")
.contentType(ContentType.JSON)
.body(jsonArrayPayload)
.log()
.all()
// WHEN
.when()
.post()
// THEN
.then()
.assertThat()
// Asserting status code as 500 as it does not accept json array payload
.statusCode(500)
.log()
.all();Jackson API is a high performance JSON processor for Java. We can perform serialization, deserialization , reading a JSON file, writing a JSON file and a lot more things using Jackson API.
To use Jackson API, we need to add it in java project build path. You can add using Maven or download a jar file with transitive jars.
Maven dependency
com.fasterxml.jackson.core
jackson-databind
2.14.1
jackosn-databind dependency will automatically download transitive dependencies of same version i.e. jackson-annotations and jackson-core as well.We will use Class ObjectMapper to create a JSON Object or ObjectNode.
- To create a JSON Object using Jackson, we need to use createObjectNode() method of ObjectMapper class which returns an ObjectNode class instance.
- ObjectNode class has overloaded methods put(String fieldName, T fieldValue ) which takes field Name as String and values of different primitive and wrapper class types like String, Boolean etc.
- All field names should be unique. If you pass duplicate field name, it will not throw any error but override field values by latest. It is similar to put() method of Map in Java.
To get the created JSON Object as string, use writeValueAsString() provided by ObjectMapper class. If you want in proper JSON format, use writerWithDefaultPrettyPrinter() method for formatting.
Example Code for Json Object:
{
"firstname" : "Phani",
"lastname" : "Nagula"
}
// Create an object to ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeDetails = objectMapper.createObjectNode();
employeeDetails.put("firstname", "Phani");
employeeDetails.put("lastname", "Nagula");
// To print created json object
String createdPlainJsonObject = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(employeeDetails);
System.out.println("Created plain JSON Object is : \n"+ createdPlainJsonObject);Example Code for Nested Json Object:
{
"employee" : {
"firstname" : "Phani",
"lastname" : "Nagula"
}
}
// Create an object to ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeInfo = objectMapper.createObjectNode();
ObjectNode employeeDetails = objectMapper.createObjectNode();
employeeDetails.put("firstname", "Phani");
employeeDetails.put("lastname", "Nagula");
employeeInfo.set("employee", "employeeDetails");
// To print created json object
String createdPlainJsonObject = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(employeeInfo);
System.out.println("Created plain JSON Object is : \n"+ createdPlainJsonObject);To create a nested JSON Object or put another JSON Object as field value, we can not use put(String fieldName, JsonNode fieldValue) as it is deprecated. We use set(String fieldName, JsonNode fieldValue) or replace(String fieldName, JsonNode fieldValue)
// Create an object to ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeInfo = objectMapper.createObjectNode();
ObjectNode employeeDetails = objectMapper.createObjectNode();
employeeDetails.put("firstname", "Phani");
employeeDetails.put("lastname", "Nagula");
employeeInfo.set("employee", "employeeDetails");
// To print created json object
String createdPlainJsonObject = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(employeeInfo);
System.out.println("Created plain JSON Object is : \n"+ createdPlainJsonObject);To retrieve a field value we need to use get(String fieldName). If passed field name does not have a value or if there is no field with such name, null is returned. It returns a JsonNode. To get value in actual data types we need to use respective methods like asText() to get value as String or asBoolean() to get value as boolean. Be careful when field value is another ObjectNode.
//defining a JSON string
String s="{\"name\":\"Phani\",\"Salary\":50000.0}";
Object obj=JSONValue.parse(s);
//creating an object of JSONObject class and casting the object into JSONObject type
JSONObject jsonObject = (JSONObject) obj;
//getting values form the JSONObject and casting that values into corresponding types
String name = jsonObject.get("name").asText();
double salary = jsonObject.get("Salary").asDouble();
//printing the values
System.out.println("Name: "+name);
System.out.println("Salary: "+salary);
To retrieve all field names from a ObjectNode, we need to use fieldNames() methods which returns an Iterator. To get count of fields in an ObjectNode, we can use size() method.
Example Code for Json Object:
{
"firstname" : "Phani",
"lastname" : "Nagula"
}
// Create an object to ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeInfo = objectMapper.createObjectNode();
employeeInfo.put("firstname", "Phani");
employeeInfo.put("lastname", "Nagula");
// To get all field names
System.out.println("Count of fields in ObjectNode : "+ employeeInfo.size());
Iterator allFieldNames = employeeInfo.fieldNames();
System.out.println("Fields are : ");
while(allFieldNames.hasNext())
{
System.out.println(allFieldNames.next());
}To retrieve all field values from an ObjectNode, use elements() method which returns an Iterator of JsonNode.
Example Code for Json Object:
{
"firstname" : "Phani",
"lastname" : "Nagula"
}
// Create an object to ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeInfo = objectMapper.createObjectNode();
employeeInfo.put("firstname", "Phani");
employeeInfo.put("lastname", "Nagula");
// To get all field values
Iterator allFieldValues = employeeInfo.elements();
System.out.println("Fields values are : ");
while(allFieldValues.hasNext())
{
System.out.println(allFieldValues.next());
}We can use fields() method to get all fields (with both names and values) of a JSON Object. It returns an Iterator<Entry>.
Example Code for Json Object:
{
"firstname" : "Phani",
"lastname" : "Nagula"
}
// Create an object to ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeInfo = objectMapper.createObjectNode();
employeeInfo.put("firstname", "Phani");
employeeInfo.put("lastname", "Nagula");
// To get all key-value pair
Iterator<Entry> allFieldsAndValues = employeeInfo.fields();
System.out.println("All fields and their values are : ");
while(allFieldsAndValues.hasNext())
{
Entry node = allFieldsAndValues.next();
System.out.println("Key is : "+node.getKey()+" and its value is : "+node.getValue());
}
Use remove(String fieldName) method to remove a field from ObjectNode. It will return value of the field, if such field existed; null if not.
Example Code for Json Object:
{
"firstname" : "Phani",
"lastname" : "Nagula"
}
// Create an object to ObjectMapper
ObjectMapper objectMapper = new ObjectMapper();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeInfo = objectMapper.createObjectNode();
employeeInfo.put("firstname", "Phani");
employeeInfo.put("lastname", "Nagula");
// To remove a field
String removedFieldValue = employeeInfo.remove("firstname").asText();
System.out.println("Value of Removed field is " + removedFieldValue);
String removedJsonObject = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(employeeInfo);
System.out.println("After removing field , JSON Object is : \n"+ removedJsonObject);
We need to use put() method to update a field value if fieldValue is not another ObjectNode. If fieldValue is an ObjectNode use set() or replace() method.
// To replace a field value, use put() method for non ObjectNode type and replace() or set() for ObjectNode
employeeInfo.put("firstname", "Swapna");
employeeInfo.put("firstname", "Nalla");
String updatedJsonObject = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(employeeInfo);
System.out.println("After updating field , JSON Object is : \n"+ updatedJsonObject);- Whether it will be serialized to JSON or XML that depends upon what we pass as Content-Type. If we pass Content-Type as application/json then Rest Assured will serialize the Object to JSON. To serialize to JSON , Rest Assured will look for which JSON parser is available in class path.
- First it looks for Jackson. If Jackson is not found it looks for GSON. If both are not found then an exception IllegalArgumentException stating “Cannot serialize because no JSON or XML serializer found in classpath.” will be thrown.
- If we pass Content-Type as “application/xml” then Rest Assured will serialize Object in to XML and for that it looks for JAXB library in class path of project. If it is not found then an exception IllegalArgumentException stating “Cannot serialize because no JSON or XML serializer found in classpath.” will be thrown.
Note :- This works for the POST and PUT methods only.
To create a JSON Object we used createObjectNode() method of ObjectMapper class. Similarly to create JSON Array we use createArrayNode() method of ObjectMapper class. createArrayNode() will return reference of ArrayNode class.
Example Json Array Object:
[
{
"employeeDetails" : {
"firstname" : "Phani",
"lastname" : "Nagula"
}
}
]
ObjectMapper objectMapper = new ObjectMapper();
// Create an array which will hold two JSON objects
ArrayNode parentArray = objectMapper.createArrayNode();
// Creating Node that maps to JSON Object structures in JSON content
ObjectNode employeeInfo = objectMapper.createObjectNode()
employeeInfo.put("firstname", "Phani");
employeeInfo.put("lastname", "Nagula");
employeeInfo.set("employeeDetails", employeeDetails);
parentArray .add(employeeInfo);
To print created JSON array as string with proper format:
String jsonArrayAsString = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(parentArray);
System.out.println("Created Json Array is : ");
System.out.println(jsonArrayAsString);
Retrieving JSON Object from JSON array using index
// To get json array element using index
JsonNode firstElement = parentArray.get(0);
System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(firstElement));
Get size of JSON Array
size() method can be used to get size of JSON Array.
int sizeOfArray = parentArray.size();
System.out.println("Size of array is "+sizeOfArray);
Remove a JSON Object from JSON Array
// To remove an element from array
parentArray.remove(0);
System.out.println("After removing first element from array : "+ objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(parentArray));
Empty JSON Array
// To empty JSON Array
parentArray.removeAll();
System.out.println("After removing all elements from array : "+ objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(parentArray));POJO stands for Plain Old Java Object and it is an ordinary Java objects not a special kind of. The term POJO was coined by Martin Fowler, Rebecca Parsons and Josh MacKenzie in September 2000 when they were talking on many benefits of encoding business logic into regular java objects rather than using Entity Beans or JavaBeans.
From the full form of OOPs , we can understand that it is a programming approach which is oriented around something called “Object” and an Object can contain data (Member variables ) and mechanism (member functions) to manipulate on these data.
A POJO class can follow some rules for better usability. These rules are :-
- Each variable should be declared as private just to restrict direct access.
- Each variable which needs to be accessed outside class may have a getter or a setter or both methods. If value of a field is stored after some calculations then we must not have any setter method for that.
- It Should have a default public constructor.
- Can override toString(), hashcode and equals() methods.
- Can contain business logic as required.
There are some restrictions imposed by Java language specifications on POJO. A POJO should not :-
- Extend prespecified classes
- Implement prespecified interfaces
- Contain prespecified annotations
Advantages of POJO :-
- Increases readability
- Provides type checks
- Can be serialized and deserialized
- Can be used anywhere with any framework
- Data Manipulation is easier. We can have logic before setting and getting a value.
- Builder pattern can be used with POJO.
- Frequently used to create payloads for API.
- Reusability
Example Json Object:
{
“firstName”: “Phani”,
“lastName”: “Nagula”,
“gender”: “Male”,
“age”: 45,
“salary”: 50000,
“married”: true
}
public class Employee {
// private variables or data members of pojo class
private String firstName;
private String lastName;
private String gender;
private int age;
private double salary;
private boolean married;
// Getter and setter methods
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public boolean getMarried() {
return married;
}
public void setMarried(boolean married) {
this.married = married;
}
}We have created a POJO class of employee JSON.
Using above POJO class you can create any number of custom Employee objects and each object can be converted in to a JSON Object and Each JSON object can be parsed in to Employee POJO. If you have an API which requires dynamic payload of Employee then you can easily create as many as required employee payloads with different data in stead of creating hard coded JSON objects. In simple words POJO gives you flexibility of creating and manipulating data in simple ways.
We will create a JSON object form POJO and vice versa now which is generally called as serialization and deserialization using Jackson APIs.
serialization – Convert Employee class object to JSON representation or Object
deserialization – reverse of serializing . Convert a JSON Object to Employee class object
package RestAssuredPojo;
import org.testng.annotations.Test;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class EmployeeSerializationDeserialization {
@Test
public void createEmployeeJSONFromEmployeePOJOClass() throws JsonProcessingException
{
// Just create an object of Pojo class
Employee employee = new Employee();
// Set value as you wish
employee.setFirstName("Phani");
employee.setLastName("Nagula");
employee.setAge(45);
employee.setGender("Male");
employee.setSalary(50000);
employee.setMarried(true);
// Converting a Java class object to a JSON payload as string
ObjectMapper objectMapper = new ObjectMapper();
String employeeJson = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(employee);
System.out.println(employeeJson);
}
@Test
public void getPojoFromEmployeeObject() throws JsonProcessingException
{
// Just create an object of Pojo class
Employee employee = new Employee();
// Set value as you wish
employee.setFirstName("Phani");
employee.setLastName("Nagula");
employee.setAge(45);
employee.setGender("Male");
employee.setSalary(50000);
employee.setMarried(true);
// Converting a Java class object to a JSON payload as string
ObjectMapper objectMapper = new ObjectMapper();
String employeeJson = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(employee);
// Converting Employee json string to Employee class object
Employee employee2 = objectMapper.readValue(employeeJson, Employee.class);
System.out.println("First Name of employee : "+employee2.getFirstName());
System.out.println("Last Name of employee : "+employee2.getLastName());
System.out.println("Age of employee : "+employee2.getAge());
System.out.println("Gender of employee : "+employee2.getGender());
System.out.println("Salary of employee : "+employee2.getSalary());
System.out.println("Marital status of employee : "+employee2.getMarried());
}
}Simple Json Array Object:
[
{
“firstName”: “Phani”,
“lastName”: “Nagula”,
“gender”: “Male”,
“age”: 45,
“salary”: 50000,
“married”: true
}
]Create POJO Class:
package RestAssuredPojo;
public class Employee {
// private variables or data members of pojo class
private String firstName;
private String lastName;
private String gender;
private int age;
private double salary;
private boolean married;
// Getter and setter methods
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public boolean getMarried() {
return married;
}
public void setMarried(boolean married) {
this.married = married;
}
}package RestAssuredPojo;
import java.util.ArrayList;
import java.util.List;
import org.testng.annotations.Test;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
public class ListOfEmployeesSerializationDeserialization {
public String allEmployeeJson;
@Test
public void createListOfEmployeesJSONArrayFromEmployeePOJOClass() throws JsonProcessingException {
// Create first employee
Employee phani = new Employee();
amod.setFirstName("Phani");
amod.setLastName("Nagula");
amod.setAge(45);
amod.setGender("Male");
amod.setSalary(50000);
amod.setMarried(true);
// Creating a List of Employees
List allEmployees = new ArrayList();
allEmployees.add(phani );
// Converting a Java class object to a JSON Array payload as string
ObjectMapper objectMapper = new ObjectMapper();
allEmployeeJson = objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(allEmployees);
System.out.println(allEmployeeJson);
}
@Test
public void getPojoFromEmployeeObject() throws JsonProcessingException {
// Converting EMployee json Array string to Employee class object
ObjectMapper objectMapper = new ObjectMapper();
List allEmploeesDetails = objectMapper.readValue(allEmployeeJson,
new TypeReference<List>() {
});
for (Employee emp : allEmploeesDetails) {
System.out.println("========================================================");
System.out.println("First Name of employee : " + emp.getFirstName());
System.out.println("Last Name of employee : " + emp.getLastName());
System.out.println("Age of employee : " + emp.getAge());
System.out.println("Gender of employee : " + emp.getGender());
System.out.println("Salary of employee : " + emp.getSalary());
System.out.println("Marital status of employee : " + emp.getMarried());
System.out.println("========================================================");
}
}
}Appium is an open-source mobile automation testing tool used to test web, native and hybrid applications. It supports multiple languages, including Java, PHP and Perl.
- Driver Client: Appium drives mobile applications as though it were a user. Using a client library you write your Appium tests which wrap your test steps and sends to the Appium server over HTTP.
- Appium Session: You have to first initialize a session, as such Appium test takes place in the session. Once the Automation is done for one session, it can be ended and wait for another session
- Desired Capabilities: To initialize an Appium session you need to define certain parameters known as “desired capabilities” like PlatformName, PlatformVersion, Device Name and so on. It specifies the kind of automation one requires from the Appium server.
- Driver Commands: You can write your test steps using a large and expressive vocabulary of commands.
Yes, it is possible to interact with App while using Javascript. When the commands run on Appium, the server will send the script to your app wrapped into an anonymous function to be executed.
- Appium does not support testing of Android Version lower than 4.2
- Limited support for hybrid app testing. E.g., not possible to test the switching action of application from the web app to native and vice-versa
- No support to run Appium Inspector on Microsoft Windows
To find the DOM element use “UIAutomateviewer” to find DOM element for Android application.
- Appium is an “HTTP Server” written using Node.js platform and drives iOS and Android session using Webdriver JSON wire protocol. Hence, before initializing the Appium Server, Node.js must be pre-installed on the system
- When Appium is downloaded and installed, then a server is setup on our machine that exposes a REST API
- It receives connection and command request from the client and execute that command on mobile devices (Android / iOS)
- It responds back with HTTP responses. Again, to execute this request, it uses the mobile test automation frameworks to drive the user interface of the apps. Framework like
- Apple Instruments for iOS (Instruments are available only in Xcode 3.0 or later with OS X v10.5 and later)
- Google UIAutomator for Android API level 16 or higher
- Selendroid for Android API level 15 or less
- It responds back with HTTP responses. Again, to execute this request, it uses the mobile test automation frameworks to drive the user interface of the apps. Framework like
- Apple Instruments for iOS (Instruments are available only in Xcode 3.0 or later with OS X v10.5 and later)
- Google UIAutomator for Android API level 16 or higher
- Selendroid for Android API level 15 or less
Appium support any language that support HTTP request like Java, JavaScript with Node.js, Python, Ruby, PHP, Perl, etc.
Appium has an “Inspector” to record and playback. It records and plays native application behavior by inspecting DOM and generates the test scripts in any desired language. However, Appium Inspector does not support Windows and use UIAutomator viewer in its option.
- Java Client uses AppiumServiceBuilder to start a node server programmatically. With the updated version, it works slightly differently with different Appium server versions.
- The default URL for the server has been changed at the server-side and it does not contain the /wd/hub by default.
- Java Client starting from v8.0.0 has made required changes to align to Appium V2.
- If you still would like to use Java Client v8 with Appium 1.2.X then consider providing the –base-path explicitly while building the AppiumServiceBuilder.
// From Appium 2.0 Beta
AppiumDriverLocalService service;
service = new AppiumServiceBuilder()
.withIPAddress("127.0.0.1")
.usingPort(4723)
.build();
service.start();
// Older approach: Appium 1.22.X
AppiumDriverLocalService service;
service = new AppiumServiceBuilder()
.withIPAddress("127.0.0.1")
.withArgument(GeneralServerFlag.BASEPATH, "/wd/hub")
.usingPort(4723)
.build();
service.start();- Java Development Kit (JDK) – It should have at least JDK version 8 or higher.
- Android SDK version 22 has separate platforms and build tools, suitable for Appium.
- Node.js is needed for a non-blocking event-based server to handle multiple WebDriver sessions for iOS and Android platforms.
- Microsoft WebDriver– also known as WinAppDriver, Appium compatible WebDriver server – Need Windows 10 or above.
- PDANet+ – It is a free application that converts Android and iOS mobile into Modem and enables tethering.
- Appium – Client libraries and Desktop application of Appium is mandatory
- GenyMotion – It is required to run Appium tests in multiple virtual Android devices in parallel.
- ADT Plugin to access Android SDK within Eclipse.
- Java Client Drivers are also known as language binding for creating testing in multiple programming languages.
- Appium Client Libraries supports Appium extensions to WebDriver protocol by Appium Server.
AppiumServiceBuilder() appiumLocalService = new AppiumServiceBuilder().usingAnyFreePort().build();
appiumLocalService.start();URL testAppUrl = getClass().getClassLoader().getResource("ApiDemos.apk");
File testAppFile = Paths.get(Objects.requireNonNull(testAppUrl).toURI()).toFile();
String testAppPath = testAppFile.getAbsolutePath();DesiredCapabilities desiredCaps = new DesiredCapabilities();
desiredCaps.setCapability(MobileCapabilityType.DEVICE_NAME, "android25-test");
desiredCaps.setCapability(AndroidMobileCapabilityType.APP_PACKAGE, "com.example.android.apis");
desiredCaps.setCapability(MobileCapabilityType.PLATFORM_NAME, "Android");
desiredCaps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "7.1");
desiredCaps.setCapability(AndroidMobileCapabilityType.APP_ACTIVITY, ".view.Controls1");
desiredCaps.setCapability(MobileCapabilityType.APP, testAppPath);By ID : AndroidElement button = driver.findElementById(“com.example.android.apis:id/button”);
By Class : AndroidElement checkBox = driver.findElementByClassName(“android.widget.CheckBox”);
By XPath : AndroidElement secondButton = driver.findElementByXPath(“//*[@resource-id=’com.example.android.apis:id/button’]”);
By AndroidUIAutomator : AndroidElement thirdButton = driver.findElementByAndroidUIAutomator(“new UiSelector().textContains(\”BUTTO\”);”);
TouchAction touchAction = new TouchAction(driver);
AndroidElement element = driver.findElementById(“android:id/content”);
Point point = element.getLocation();
Dimension size = element.getSize();
touchAction.press(PointOption.point(point.getX() + 5, point.getY() + 5))
.waitAction(WaitOptions.waitOptions(Duration.ofMillis(200)))
.moveTo(PointOption.point(point.getX() + size.getWidth() – 5, point.getY() + size.getHeight() – 5))
.release()
.perform();
public void tapByElement (AndroidElement androidElement) {
TouchAction touch = new TouchAction(driver);
touch.tap(tapOptions().withElement(element(androidElement))).waitAction(waitOptions(ofMillis(250))).perform();
}public void tapByCoordinates (int x, int y) {
TouchAction touch = new TouchAction(driver);
touch.tap(point(x,y))
.waitAction(waitOptions(ofMillis(250))).perform();
}public void pressByElement (AndroidElement element, long seconds) {
TouchAction touch = new TouchAction(driver);
touch.press(element(element))
.waitAction(waitOptions(ofSeconds(seconds)))
.release()
.perform();
} public void pressByCoordinates (int x, int y, long seconds) {
TouchAction touch = new TouchAction(driver);
touch.press(point(x,y))
.waitAction(waitOptions(ofSeconds(seconds)))
.release()
.perform();
}public void horizontalSwipeByPercentage (double startPercentage, double endPercentage, double anchorPercentage) {
Dimension size = driver.manage().window().getSize();
int anchor = (int) (size.height * anchorPercentage);
int startPoint = (int) (size.width * startPercentage);
int endPoint = (int) (size.width * endPercentage);
TouchAction touch = new TouchAction(driver);
touch.press(point(startPoint, anchor))
.waitAction(waitOptions(ofMillis(1000)))
.moveTo(point(endPoint, anchor))
.release().perform();
}public void verticalSwipeByPercentages(double startPercentage, double endPercentage, double anchorPercentage) {
Dimension size = driver.manage().window().getSize();
int anchor = (int) (size.width * anchorPercentage);
int startPoint = (int) (size.height * startPercentage);
int endPoint = (int) (size.height * endPercentage);
TouchAction touch = new TouchAction(driver);
touch.press(point(anchor, startPoint))
.waitAction(waitOptions(ofMillis(1000)))
.moveTo(point(anchor, endPoint))
.release().perform();
}public void swipeByElements (AndroidElement startElement, AndroidElement endElement) {
int startX = startElement.getLocation().getX() + (startElement.getSize().getWidth() / 2);
int startY = startElement.getLocation().getY() + (startElement.getSize().getHeight() / 2);
int endX = endElement.getLocation().getX() + (endElement.getSize().getWidth() / 2);
int endY = endElement.getLocation().getY() + (endElement.getSize().getHeight() / 2);
TouchAction touch = new TouchAction(driver);
touch.press(point(startX,startY))
.waitAction(waitOptions(ofMillis(1000)))
.moveTo(point(endX, endY))
.release().perform();
}public void multiTouchByElement (AndroidElement androidElement) {
TouchAction touch = new TouchAction(driver);
touch.press(element(androidElement))
.waitAction(waitOptions(ofSeconds(1)))
.release();
MultiTouchAction multiTouch = new MultiTouchAction(driver).
multiTouch.add(touch)
.perform();
}Managing your mobile device capabilities need so much effort in case you change your device frequently. During the test, there are mandatory capabilities that you need to manage like “Platform Name”, “Device Version”, “Device Name” or “UDID” information.
You need to run ADB command to extract those kinds of data or you need to manually find them out.
You need to run ADB command to extract those kinds of data or you need to manually find them out.
Bahadır Üstün, has recently developed a library to fetch information from devices connected to your computer. It fetches any information that can be captured from your IOS or Android device.
Here is the library GitHub Link: https://github.com/Testinium/MobileDeviceInfo
You can add your project as a maven dependency.

You have to add our repository to your pom.xml because it hasn’t released to Maven Central repositories.

DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability(CapabilityType.PLATFORM, device.getDeviceProductName());
capabilities.setCapability("platformName", device.getDeviceProductName());
capabilities.setCapability(CapabilityType.VERSION, device.getProductVersion());
capabilities.setCapability("deviceName", device.getModelNumber());
capabilities.setCapability("udid", device.getUniqueDeviceID());
capabilities.setCapability("app", "#Your App File#");
driver = new RemoteWebDriver(new URL(URL), capabilities);UIAutomator is for Android only.
With UI Automator I can scroll and find element\elements with text\text contains\id\text starts with.
Searching for element via UIAutomator allows to actually scroll view up/down to the searchable element. First of all, it is a search action, you can use it for scrolling if you have a scrollable view and know element inside of it. So it requires:
View with scrollable=true attribute.
Know element id, text, etc. to locate it.
Can’t use coordinates.
Fails if element is not found.
Not precise, stops scrolling as soon as element is found.
- MobileElement firstClickableEl = driver.findElement(MobileBy.AndroidUIAutomator(“new UiSelector().clickable(true)”))
- MobileElement elementInView = driver.findElement(MobileBy.AndroidUIAutomator(“new UiScrollable(new UiSelector().scrollable(true).instance(0)).scrollIntoView(new UiSelector().text(“‘ + text + ‘”).instance(0))’)
driver.swipe is with x and y coordinates.
Actions API is used for different gestures like touch, tap, drag&drop, swipe, etc.
- no need to locate elements
- Can use both coordinates and elements
- More precise if you pass the right coordinates
public void swipeScreen() {
// final value depends on your app and could be greater
final int ANIMATION_TIME = 200; // ms
final int PRESS_TIME = 200; // ms
int edgeBorder = 10; // better avoid edges
PointOption pointOptionStart, pointOptionEnd;
// init screen variables
Dimension dims = driver.manage().window().getSize();
// init start point = center of screen
pointOptionStart = PointOption.point(dims.width / 2, dims.height / 2);
pointOptionEnd = PointOption.point(dims.width / 2, dims.height - edgeBorder);
TouchAction touch = new TouchAction(driver);
touch.press(pointOptionStart)
// a bit more reliable when we add small wait
.waitAction(WaitOptions.waitOptions(Duration.ofMillis(PRESS_TIME)))
.moveTo(pointOptionEnd)
.release().perform();
}- UIScrollable is a powerful Android class that performs element lookups in scrollable layouts. In most cases you should use “scrollIntoView” class which performs scroll action until the destination element is found on the screen.
- We can use UIScrollable swipe in following cases: – search elements in a list (e.g. country list) – search elements outside of the screen (e.g. input field, text or button).
- ScrollIntoView has UiSelector as search criteria input that allows you to find elements by: – by text (exact, contains, match, starts with or regex) – id (exact or regex) – some other methods (rarely used) see in Android developer documentation – a combination of available search methods.
Search by text
// Page object
@AndroidFindBy(uiAutomator = "new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().text(\"exact_text\"))")
MobileElement element;
@AndroidFindBy(uiAutomator = "new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().textContains(\"part_text\"))")
MobileElement element;
// FindElement
MobileElement element = (MobileElement) driver.findElement(MobileBy.AndroidUIAutomator(
"new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().text(\"exact_text\"))"));
MobileElement element = (MobileElement) driver.findElement(MobileBy.AndroidUIAutomator(
"new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().textContains(\"part_text\"))"));
Search by id
// Page object
@AndroidFindBy(uiAutomator = "new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().resourceIdMatches(\".*part_id.*\"))")
MobileElement element;
// FindElement
MobileElement element = (MobileElement) driver.findElement(MobileBy.AndroidUIAutomator(
"new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().resourceIdMatches(\".*part_id.*\"))"));
Search by id and text
// Page object
@AndroidFindBy(uiAutomator = "new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().resourceIdMatches(\".*part_id.*\").text(\"exact_text\"))")
MobileElement element;
// FindElement
MobileElement element = (MobileElement) driver.findElement(MobileBy.AndroidUIAutomator(
"new UiScrollable(new UiSelector().scrollable(true))" +
".scrollIntoView(new UiSelector().resourceIdMatches(\".*part_id.*\").text(\"exact_text\"))"));
Long view issue
For some longer views it is necessary to increase “setMaxSearchSwipes”. This value allows to set the maximum count of swipe retries made until the search is stopped.
// set max swipes to 10
// FindElement
MobileElement element = (MobileElement) driver.findElement(MobileBy.AndroidUIAutomator(
"new UiScrollable(new UiSelector().scrollable(true)).setMaxSearchSwipes(10)" +
".scrollIntoView(new UiSelector().text(\"exact_text\"))"));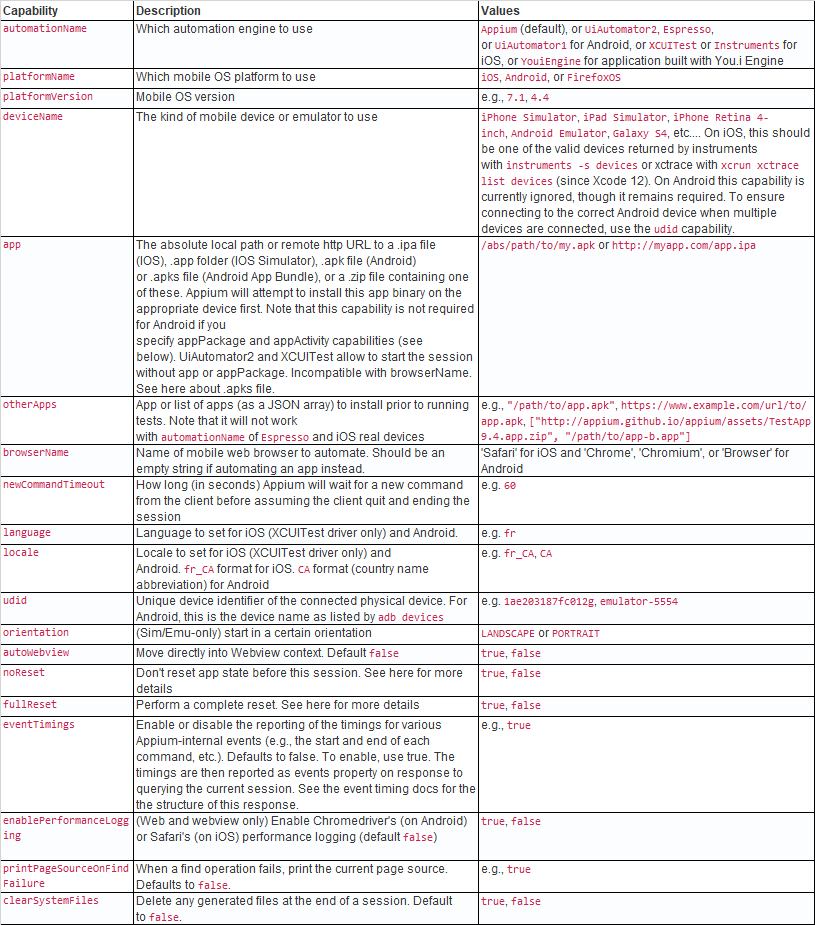
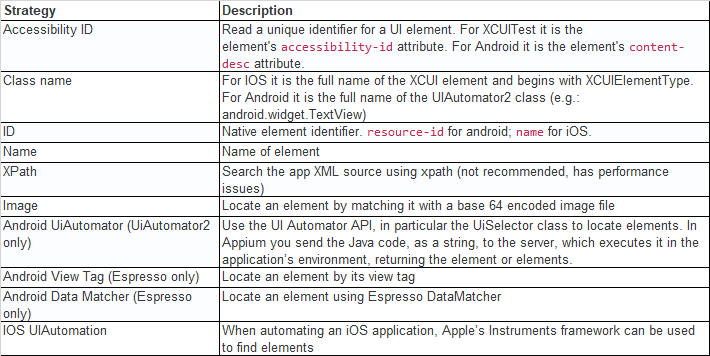
For Example:-
MobileElement elementOne = (MobileElement) driver.findElementByAccessibilityId("SomeAccessibilityID");
MobileElement elementTwo = (MobileElement) driver.findElementByClassName("SomeClassName");
List elementsOne = (List) driver.findElementsByAccessibilityId("SomeAccessibilityID");
List elementsTwo = (List) driver.findElementsByClassName("SomeClassName");Get Element Text
MobileElement element = (MobileElement) driver.findElementByClassName(“SomeClassName”);
String elText = element.getText();
Get Tag Name
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
String tagName = element.getTagName();
Get Element Attribute
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
String tagName = element.getAttribute(“content-desc”);
Is Element Selected
Determine if a form or form-like element (checkbox, select, etc…) is selected
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
boolean isSelected = element.isSelected();
Is Element Enabled
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
boolean isEnabled = element.isEnabled();
Is Element Displayed
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
boolean isDisplayed = element.isDisplayed();
Get Element Location
Determine an element’s location on the page or screen
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
Point location = element.getLocation();
Get Element Size
Determine an element’s size in pixels
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
Dimension elementSize = element.getSize();
Get Element Rect
Gets dimensions and coordinates of an element
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
Rectangle rect = element.getRect();
Get Element CSS Value
Query the value of a web element’s computed CSS property
MobileElement element = (MobileElement) driver.findElementById(“SomeId”);
String cssProperty = element.getCssValue(“style”);
Click
Click element at its center point.
MobileElement el = driver.findElementByAccessibilityId(“SomeId”);
el.click();
Send Keys
Send a sequence of key strokes to an element
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
element.sendKeys(“Hello world!”);
Clear Element
Clear an element’s value
MobileElement element = (MobileElement) driver.findElementByAccessibilityId(“SomeAccessibilityID”);
element.clear();
Get Current Context
Retrieve the current context. This can be either NATIVE_APP for the native context, or a web view context, which will be:
iOS – WEBVIEW_
Android – WEBVIEW_
String context = driver.getContext();
Get All Contexts
Retrieve all the contexts available to be automated. This will include, at least, the native context. There can also be zero or more web view contexts.
Set contextNames = driver.getContextHandles();
Set Current Context
Set the current context to that passed in. If this is moving into a web view context it will involve attempting to connect to that web view:
Set contextNames = driver.getContextHandles();
driver.context(contextNames.toArray()[1]);
// …
driver.context(“NATIVE_APP”);
Appium can automate the Safari browser on real and simulated iOS devices. It is accessed by setting the browserName desired capabilty to “Safari” while leaving the app capability empty.
Mobile Safari on Simulator
First of all, make sure developer mode is turned on in your Safari preferences so that the remote debugger port is open.
Mobile Safari on a Real iOS Device
For XCUITest
We use appium-ios-device to handle Safari since Appium 1.15. You no longer need to install additional dependencies.
For Instruments
For iOS 9.3 and below (pre-XCUITest), we use the SafariLauncher App app to launch Safari and run tests against mobile Safari. This is because Safari is an app that is owned by Apple, and Instruments cannot launch it on real devices. Once Safari has been launched by SafariLauncher, the Remote Debugger automatically connects using the ios-webkit-debug-proxy. When working with ios-webkit-debug-proxy, you have to trust the machine before you can can run tests against your iOS device.
Setup for an iOS real device
Before you can run your tests against Safari on a real device you will need to:
XCUITest and Instruments
Turn on web inspector on iOS device (settings > safari > advanced)
Only for Instruments
Have the ios-webkit-debug-proxy installed, running and listening on port 27753
Make sure that SafariLauncher will work
//setup the web driver and launch the webview app.
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability(MobileCapabilityType.PLATFORM_NAME, “iOS”);
capabilities.setCapability(MobileCapabilityType.PLATFORM_VERSION, “13.2”);
capabilities.setCapability(MobileCapabilityType.AUTOMATION_NAME, “XCUITest”);
capabilities.setCapability(MobileCapabilityType.BROWSER_NAME, “Safari”);
capabilities.setCapability(MobileCapabilityType.DEVICE_NAME, “iPhone 11”);
URL url = new URL(“http://127.0.0.1:4723/wd/hub”);
AppiumDriver driver = new AppiumDriver(url, desiredCapabilities);
// Navigate to the page and interact with the elements on the guinea-pig page using id.
driver.get(“http://saucelabs.com/test/guinea-pig”);
WebElement div = driver.findElement(By.id(“i_am_an_id”));
Assert.assertEquals(“I am a div”, div.getText()); //check the text retrieved matches expected value
driver.findElement(By.id(“comments”)).sendKeys(“My comment”); //populate the comments field by id.
//close the app.
driver.quit();
Hire QA is hiring for the position of API Automation Engineers for our clients.
- Location: Hyderabad / Bengaluru / Pune
- Experience: 3-6 Years
- Skills Required: Selenium WD, Rest Assured, Java/Python, POM, TestNG, BDD, ExtentReport, Git, Jenkins
Strong knowledge and experience in
- Immediate joiners with strong experience in Rest Assured using Java.
- Automation Framework using Maven, Apache POI, TestNG, BDD, Extent Reports.
- API Testing using Postman.
- Strong knowledge in SQL.
- Version control using Git and CI/CD using Jenkins.
Hire QA is hiring for the position of Test Automation Lead for our clients.
- Location: Hyderabad / Bengaluru / Pune
- Experience: 8-12 Years
- Skills Required: Selenium WD, Rest Assured, Java/Python, POM, TestNG, BDD, ExtentReport, Git, Jenkins
Strong knowledge and experience in
- Must have skills:
- 7+ years of experience in automated testing, with at least 2 years in a lead role
- Experience with test automation tools and frameworks, such as Selenium WebDriver, RestAssured, TestNG/Cucumber
- Experience with continuous integration and continuous delivery (CI/CD) tools, such as Jenkins
- Strong understanding of software development and testing methodologies
- Excellent communication and leadership skills
- Experience with API testing and integration testing
- Experience with programming languages such as Java or Python
- Key responsibilities:
- Lead the development and execution of automated testing strategies for our platforms
- Identify and prioritize areas of the platform that would benefit from automated testing
- Write and maintain automated test cases using a variety of tools and frameworks
- Coordinate the execution of automated tests with the development and release schedules
- Work closely with the development team to identify and fix defects
- Participate in the continuous improvement of our testing processes and tools
- Mentor and guide junior team members in automated testing best practices
- Load Testing – Load tests are performed to evaluate the system’s behavior under an expected number of concurrent users who perform a specific number of transactions during a predefined time. These tests make it possible to measure the response times of the transactions, as well as to evaluate if the system resources limit the system’s performance.
- Stress Testing – Stress tests are performed to determine the system’s behavior when faced with extreme loads. They are performed by increasing the number of concurrent users and the number of transactions they execute, exceeding the expected load. They give an insight into how the system’s performance is, in case the actual load exceeds the expected load, determining which components and/or resources fail first and limit the system’s performance.
- Spike Testing – These types of tests are very similar to stress tests, but are performed over short periods of time, simulating significant load changes at a given time. They allow us to know the behavior of the system when there is a spike in its use, and to evaluate whether the system is able to return to a stable state afterwards. In JMeter, Spike testing can be performed using Synchronizing Timer. This timer keeps on blocking the threads until a particular number of threads get reserved. It then releases them at once thus creating large instantaneous load.
- Endurance Testing – Endurance tests allows us to determine whether the system can support an expected load continuously during a period of time that corresponds to the context of the system use. They help evaluate the performance of the different resources; for example, if there are memory leaks, or degradations due to bad management of the database connections, among others.
- Scalability Testing – Scalability tests are performed to evaluate the system’s ability to grow. Typically, the number of concurrent users, the number of transactions they can perform, the volume of information in the database, and other non-functional aspects of the system, are projected into the future.
- Volume Testing – Under Volume Testing large no. of. Data is populated in a database and the overall software system’s behavior is monitored.
- HyperText Transfer Protocol (HTTP) is a protocol using which hypertext is transferred over the Web.
- The data (i.e. hypertext) exchanged using http isn’t as secure. hyper-text exchanged using http goes as plain text i.e. anyone between the browser and server can read it relatively easy if one intercepts this exchange of data.
- But why do we need this security over the Web? Think of ‘Online shopping’ at Amazon or Flipkart. You might have noticed that as soon as we click on the Check-out on these online shopping portals, the address bar gets changed to use https. This is done so that the subsequent data transfer (i.e. financial transaction etc.) is made secure.
- And that’s why https was introduced so that a secure session is setup first between Server and Browser. In fact, cryptographic protocols such as SSL and/or TLS turn http into https i.e. https = http + cryptographic protocols. Also, to achieve this security in https, Public Key Infrastructure (PKI) is used because public keys can be used by several Web Browsers while private key can be used by the Web Server of that particular website. The distribution of these public keys is done via Certificates which are maintained by the Browser. You can check these certificates in your Browser settings. We’ll detail out this setting up secure session procedure in another post.
- Also, another syntactic difference between http and https is that http uses default port 80 while https uses default port 443. But it should be noted that this security in https is achieved at the cost of processing time because Web Server and Web Browser needs to exchange encryption keys using Certificates before actual data can be transferred. Basically, setting up of a secure session is done before the actual hypertext exchange between server and browser.
- HTTP Works at Application Layer and HTTPS works at Transport Layer.
- In HTTP, Encryption is absent and Encryption is present in HTTPS as discussed above HTTP does not require any certificates and HTTPS needs SSL Certificates
- Test Planning – Define test scenarios, workload modelling
- Test Data
- Test infrastructure
- Acceptance Criteria
- Test Scenarios Specification
- Test Scenarios
- Test Scripts
- Test Automation – develop the scripts
- Test Environment Setup
- Test Execution
- Baseline
- Scenario Execution
- System monitoring
- Results analysis
- Re-execution of the tests
- Test report
- Extended response time of user
- Extended response time of server
- High CPU usage
- Invalid data returned
- HTTP errors (4xx, 5xx)
- Lots of open connections
- Lengthy queues of requests
- Memory leaks
- Extensive table scans of database
- Database deadlocks
- Pages unavailable
Network architecture refers to how computers are organized in a system and how tasks are allocated between these computers. Two of the most widely used types of network architecture are peer-to-peer and client/server.
The configuration, or topology, of a network is key to determining its performance. Network topology is the way a network is arranged, including the physical or logical description of how links and nodes are set up to relate to each other.
The term topology was introduced by Johann Benedict Listing in the 19th century.
Application architecture is formed by several components and there could be dozens of bad performance symptoms in each component. Being a good performance tester, one must know the list of performance symptoms on each tier to diagnose bottlenecks effectively.
Below is the detailed list of symptoms of each of the web applications 3-tier component.
- Network Performance Bottlenecks
- Web Server Performance Bottlenecks
- Application Server Performance Bottlenecks
- Database Server Performance Bottlenecks
- Client Side Performance Bottlenecks
- Third Party Services Performance Issues
Network bottlenecks contribute very little however they are important enough to be discussed in detail because you cannot afford minor issues as well because they can lead to disasters. Following are the major network performance symptoms in context of 3-tier web applications,
- Load balancing ineffectiveness
- Network interface card insufficient/poor configuration
- Very tight security
- Inadequate over all bandwidth
- Pathetic network architecture
Like network performance bottlenecks, web server bottlenecks don’t have major contribution to the performance issues as well. Web servers act as a liaison between client and processing servers (application and database). So web server performance bottlenecks need to be addressed properly since they can affect other components performance to great extent.
Below is the list of bottlenecks which can affect web server performance,
- Broken links
- Inadequate transaction design
- Very tight security
- Inadequate hardware capacity
- High SSL transactions
- Server poorly configured
- Servers with ineffective load balancing
- Less utilization of OS resources
- Insufficient throughput
Business logic of an application resides on the application server. Application server hardware, software and application design can affect the performance to great extent. Poor application server performance can be a critical source of performance bottlenecks.
Below is the list of application server bad performance causes,
- Memory leaks
- Useless/inefficient garbage collection
- DB connections poor configuration
- Useless/inefficient code transactions
- Sub-optimal session model
- Application server poor configuration
- Useless/inefficient hardware resources
- Useless/inefficient object access model
- Useless/inefficient security model
- Less utilization of OS resources
Object caching, SQL and database connection polling are the main causes of application server bottlenecks and they contribute 60% to the application server. 20% of the times inefficient application server causes poor performances.
Database performance is most critical for application performance as this is the main culprit in performance bottlenecks. Database software, hardware and design can really impact the whole system performance.
Following is the comprehensive list of database poor performance causes,
- Inefficient/ineffective SQL statement
- Small/insufficient query plan cache
- Inefficient/ineffective SQA query model
- Inefficient/ineffective DB configurations
- Small/insufficient data cache
- Excess DB connections
- Excess rows at a time processing
- Missing/ineffective indexing
- Inefficient/ineffective concurrency model
- Outdated statistics
- Deadlocks
1. Measurable Scenarios
2. Most frequently accessed scenarios
3. Business critical scenarios
4. Resource Intensive Scenarios
5. Technology specific scenarios
6. Stakeholder concerned scenarios
7. Time dependent frequently used scenarios
8. Contractually obligated scenarios
- Actual users can experience major slowdown in application response
- Real users may not be able to complete their business transactions due to the slow response time
- Application can be slow even after test completion due to the data generated during the performance test execution
- Real user can start experiencing application errors and even the application can stop responding
- It will be difficult to identify the root-cause of the performance bottlenecks in the presence of real users along with simulated users load
- Real users need to stop the work on the application to get accurate test results but it will make the application unavailable during this time, which might not be possible on business critical applications
- Third party Content Deliver Network (CDN) performance is not tested
- Firewall effects on application performance are not tested
- Application load balancing is not tested in test environment
- Application internet connection performance is not tested
- DNS lookup time is not tested in test lab
- Server Infra – Replicating a number of physical servers at each application tier in test env is a real challenge.
- Network Infra – Preparing the servers network infra is possible with some efforts but deploying the test servers on production servers locations is a hard thing to do.
- Number of Application Tiers – Test environment should have the exact number of application tiers as the production environment to achieve the accurate results which is also a challenge.
- Database Size – A database with different size will not be able to generate accurate test results.
- Load Injection from Different Geographical Locations – simulating users’ locations is also important to achieve proper test results.
- IP Spoofing Implementation – In few cases, load balancing is implemented based on the IP addresses. Users are distributed on different servers based on their IP addresses and if all incoming requests are from the same IP address, they will be directed to a single server and hence load balancing will never be observed.
- Complete Knowledge of AUT Production and Test Environment – The details of AUT production environment should be completely documented and understood in the initial stage of the performance testing. Performance testing engineer must know the AUT architecture details and ensure that the exact architecture is being implemented in the test environment.
- Test Environment Isolation – It’s highly recommended that no other activity should be carried out on the performance test environment during the test execution. Performance test results can greatly vary and it’s always difficult to analyze and reproduce performance bottlenecks in a test environment where other users are also interacting with the system.
- Network Isolation – So in order to provide the maximum network bandwidth to your test environment, one solution is that you should isolate your test network from other users.
- Load Injectors Requirements – Load Injector machines should have sufficient hardware resources to support the running users.The amount of load that can be generated from one load injector depends on various factors like machine resources (RAM, CPU, Disk), network bandwidth, script complexity and think time etc.
- Test Data Generators – a number of database records always have a great impact on performance test results. Reading a record from 1000 rows will be much faster than reading it from 10,000 database records.
- Proxy Servers Removal from Network Path – Having a proxy server between the client and the web server can affect performance results. In case of having a proxy server in middle of client and web server, the proxy will serve the client with data in cache instead of sending requests to web server, which results in lower AUT response time than actual. The issue can be resolved either by bringing the web server in an isolated environment or by hitting directly to the web server by editing HOSTS file by including server IP address.
- Complete Servers Access – Complete servers access during the test helps in identifying all server resources and bottlenecks root-causes.
- Simulate Clients Closer to Web Server – Latency can be one of the major factors in application response time. Closer users requesting from less distance will receive less response time as compared to the users sitting on long distance. Moreover, less network issues will occur on simulating closer user requests.
Advantages:
- No need to reproduce the production site data set
- It helps in validating performance test results performed on test environment
- It reduces test infrastructure cost and time
- Application recovery process and its complexities are well known
Disadvantages:
- Real application users will receive slower application and errors
- Difficult to identify the bottleneck root cause in presence of real application users
- Real users access might have to be blocked to properly achieve the performance test results
- In case of generating lots of data on production database, database may become very slow even after the test
Advantages
- Cost effective and results can be mapped by using extrapolation techniques
- Easy to setup as it requires less infrastructure
- Easy to identify application bottlenecks and tune it on the scaled environment
Disadvantages
- It’s difficult to find out performance issues past the scaled environment
- Application tolerance and capacity is reduced on scaled environment and more performance issues are revealed in production
Advantages
- Cloud testing provides the flexibility of deploying the production system on discrete environment to conveniently test the application
- It’s extremely simple to fix the defects and quickly configure the changes
- It reduces the test cost due to its convenient rental models
- It provides greater test control to simulate required user load and to identify and simulate the bottlenecks
Disadvantages
- Security and privacy of data is the biggest concern in cloud computing
- Cloud computing works on-line and completely depends on the network connection speed
- Complete dependency on Cloud Service Provider for quality of service
- Although cloud hosting is a lot cheaper in long run but its initial cost is usually higher than the traditional technologies
- Although it’s a short-term issue due to the emerging technology and it’s difficult to upgrade it without losing the data
Service virtualization is a mode used to simulate the AUT specific components behavior which is not accessible to test the application completely. Through service virtualization, complete AUT is not emulated rather only specific and required components are emulated to fulfill the requirements.
Advantages
- It helps in emulating realistic performance for dependent application
- It provides access to AUT constrained components at convenient times
- It helps in testing application performance with different parameter settings
- It helps in simulating extreme loads on third party components without much additional costs
- It can test the AUT components performance which are not yet completely developed
Disadvantages
- Virtualized components performance vary greatly from live AUT components which yield incorrect performance results
- There isn’t any guarantee that AUT performing as per requirements when tested it in virtualized environment will also performed similarly in production
- You can’t virtualize all the complex and secure systems
- You can’t emulate the production data in virtualized environment which can greatly affect the performance of AUT
- Budget, Types of license, Vendor support and online forums, Protocol support, Scripting languages, Protocol analyser
- Record and Playback options, Data Parameterization, Checkpoints, Transactions, Actions, Iterations, Built-in functions, Custom Functions for reusability, Compare scripts utility,
- Bandwidth simulation, Browser support / compatibility, Log Levels, Real time Workload Model, Scheduling, IP Proofing
- Intuitive Graphs and Charts for identifying bottleneck, Different formats of Result Generation like *.html, *.csv, *.xls, *.xlsx, *.pdf etc., Diagnostics,
- Resource Monitoring, Batch execution
- Direct jump to multi-user tests
- Test results not validated
- Unknown workload details
- Too small run duration
- Lacking long duration sustainability test
- Confusion on definition of concurrent users
- Data not populated sufficiently
- Significant difference between test and production environment
- Network bandwidth not simulated
- Underestimating performance testing schedules
- Incorrect extrapolation of pilots
- Inappropriate base-lining of configurations
Benchmark Testing – It is the method of comparing performance of your system performance against an industry standard that is set by other organization.
Baseline Testing – It is the procedure of running a set of tests to capture performance information. When future change is made in the application, this information is used as a reference.
Profiling tools are used on running code to identify which processes are taking the most time.
Profiling tools are usually only used once it has been identified that the system has a performance problem — if the server is taking a long time to respond, and you can’t identify any resource problem (e.g. lack of memory or poorly configured garbage connection), profiling might be your next choice of strategy.
1. Client Side – A performance testing tool gathers all the client-side metrics and displays them either during the test or at the end of the test. Client-side metrics are the initial points to start the investigation of the bottlenecks.
2. Server Side – An application monitoring tool needs to be set-up to collect the server-side stats. Following the clue getting from the client-side graph and correlating with the server-side metrics will provide the exact address of hidden bottleneck.
Server-side stats include GC analysis, Heap dump analysis along with basic CPU and Memory usage graph.
3. Network Side – This part covers the performance metrics of the network. Such metrics help to find out the obstacles of the network which increase the network latency. Low bandwidth is one of them which occurs so often.
| Performance Testing | Performance engineering |
| Performance Testing verifies how a system will perform under production load and to anticipate issues that might arise during heavy load conditions. | Performance engineering aims to design the application by keeping the performance metrics in mind and also to discover potential issues early in the development cycle. |
| Performance Testing is a distinctive QA process that occurs once a round of development is completed | performance engineering is an ongoing process that occurs through all phases of the development cycle i.e. from the design phase to development, to QA. |
| A dedicated performance tester or team conduct the Performance Testing who has sound knowledge of performance testing concept, tool operation, result analysis etc. | A Performance Engineer is a person who has enough knowledge of application design, architecture, development, tuning, performance optimization and bottleneck root cause investigation and fixing. |
| When a bottleneck is identified during performance testing then the role of the performance tester is to analyse the test result and raise a defect. | performance engineer is to investigate the root cause and propose the solution to resolve the bottleneck. |
- Cookies are text files with small pieces of data — like a username and password — that are used to identify your computer as you use a computer network. Specific cookies known as HTTP cookies are used to identify specific users and improve your web browsing experience.
- Data stored in a cookie is created by the server upon your connection. This data is labeled with an ID unique to you and your computer.
- When the cookie is exchanged between your computer and the network server, the server reads the ID and knows what information to specifically serve to you.
With a few variations, cookies in the cyber world come in two types: session and persistent.
Session cookies are used only while navigating a website. They are stored in random access memory and are never written to the hard drive.
When the session ends, session cookies are automatically deleted. They also help the “back” button or third-party anonymizer plugins work. These plugins are designed for specific browsers to work and help maintain user privacy.
Persistent cookies remain on a computer indefinitely, although many include an expiration date and are automatically removed when that date is reached.
Persistent cookies are used for two primary purposes:
Authentication. These cookies track whether a user is logged in and under what name. They also streamline login information, so users don’t have to remember site passwords.
Tracking. These cookies track multiple visits to the same site over time. Some online merchants, for example, use cookies to track visits from particular users, including the pages and products viewed. The information they gain allows them to suggest other items that might interest visitors. Gradually, a profile is built based on a user’s browsing history on that site.
The HTTP protocol used to exchange information files on the web is used to maintain the cookies.
There are two types of the HTTP protocol. Stateless HTTP and Stateful HTTP protocol. The stateless HTTP protocol does not keep any record of previously accessed web page history. While Stateful HTTP protocol does keep some history of previous web browser and web server interactions and this protocol is used by the cookies to maintain the user interactions.
Whenever a user visits a site or page that is using a cookie, the small code inside that HTML page (Generally a call to some language script to write the cookie like cookies in JAVAScript, PHP, Perl) writes a text file on users machine called a cookie.
Here is one example of the code that is used to write a Cookie and can be placed on any HTML page:
Set-Cookie: NAME=VALUE; expires=DATE; path=PATH; domain=DOMAIN_NAME;
When a user visits the same page or domain later time this cookie is read from disk and used to identify the second visit of the same user on that domain. The expiration time is set while writing the cookie. This time is decided by the application that is going to use the cookie.
1. Understand the objective for workload model creation (performance testing or capacity planning)
2. Understand system objectives, application landscape and end users of the system
3. Understand the business drivers that impact the end user load on the system.
4. Identify the top critical use cases and navigation patterns
5. Identify the user load distribution level across use cases and its transactions. Workload characterization should focus on creating realistic load on all tiers.
6. Gather the average and peak access statistics like users per unit time, page views per unit time, average session duration, current and target load levels, user abandonment rate, etc.
1. System understanding
2. identify key use cases
3. identify transactions, test data and think times to be used
4. Identify user distribution levels
5. identify current and projected user load targets / transactional volume targets
6. Create workload model and validate using Little’s Law
1. Performance modelling is the process of creating performance models
2. Performance models are built early, usually defined during design phase and continuously refined throughout SDLC phase
3. Performance models are built using analytical modelling (queuing theory) or simulation modelling or statistical modelling techniques.
4. performance models are used to evaluate architectural or design trade offs before building full system
5. performance models are used to predict performance behavior of the system by feeding in the performance data captured from the system as its get deployed
1. Requirement specification / use case documents
2. architectural diagrams
3. interview with business stakeholders (functional experts, business analysts, technical SMEs, etc)
4. Questionnaire answered by Beta Users
5. Marketing brochures / release manuals
6. Performance benchmarks of similar applications
7. Use case prioritization index
8. Analysis of end user access pattern by releasing the application to beta users
JMeter is a free and open source tool created by the Apache Software Foundation to carry out performance testing. The tool is a Java-based application and was originally designed to test web applications.
It allows for load simulations to be carried out through different types of applications and protocols:
● Web – HTTP, HTTPS (Java, NodeJS, PHP, ASP.NET, etc.)
● SOAP/REST web services
● FTP, FTPS
● Database via JDBC
● LDAP
● Message-oriented middleware (MOM) via JMS
● Mail – SMTP, POP3 e IMAP
● Native commands or shell scripts
● TCP
● Java objects
JMeter features an integrated development environment (IDE), which allows for tests to be created quickly using its script-recording function from a web browser and to be subsequently executed.
It includes a command line execution mode, which makes it possible to run the tests from any Java-compatible operating system (Windows, Linux, Mac OS, among others).
It provides the means to export the test results through a complete HTML report.
JMeter allows the extension of its functionalities through add-ons. Several are available through the Apache community, but it is also possible to build new ones when needed.
It also allows an integration with tools and libraries in continuous integration schemes, such as Maven, Gradle and Jenkins.
Understanding that JMeter is not a web browser is essential; the tool works on a protocol level. More specifically, JMeter does not execute embedded code on the pages as a web browser would; therefore, it does not execute JavaScript and does not render HTML pages.
A test plan in JMeter defines a tree structure of how, when and what to test, providing for the execution of a sequence of actions.
The element categories that JMeter handles are:
- Requests (Sampler): the different types of requests for different protocols can be found here.
- Logic Controllers: the logic controllers that allow you to define the flow of the tests are located here.
- Pre Processors: this category comprises all the elements that can be executed before making a request.
- Post Processors: this category comprises all the elements that can be executed after making a request.
- Assertions: all the elements used to carry out verifications and validations during the execution of the tests are grouped here.
- Timer: the elements related to waiting times are located here.
- Script fragments (Test Fragment): this category contains a single element with the same name. This element allows us to define script fragments to be reused in different sections of the script.
- Config Element: this category contains all the configuration elements for the script.
- Listener: the elements related to the results listeners and test execution reports can be found here.
The threads or users are represented in JMeter through groups of threads.
Each group of threads represents a set of system users, and they are used to execute the performance tests to simulate the concurrence of users on the application.
This is the very first options of Thread Group element, but not many people pay attention to it. It determines what happens if a sampler error occurs, either because the sample itself failed or an assertion failed. The possible choices are:
Continue (default)- ignore the error and continue with the test and run next sampler.
Start Next Loop – ignore the error, start next loop and continue with the test
Stop Thread – current thread exits
Stop Test – the entire test is stopped at the end of any current samples. It means the pending samplers are still run until done.
Stop Test Now – the entire test is stopped immediately. Any current samplers are interrupted if possible.
The ramp-up period tells JMeter how long to take to “ramp-up” to the full number of threads chosen.If 10 threads are used, and the ramp-up period is 100 seconds, then JMeter will take 100 seconds to get all 10 threads up and running. Each thread will start 10 (100/10) seconds after the previous thread was begun.
The delayed threads creation functionality was introduced in JMeter version 2.8. “Delayed threads” feature that allows allocating memory for new threads only when they start their execution. Previously, when you were going to spin up 1000 users during your performance tests, even if you had a ramp up time for users, JMeter allocated memory for all the threads right away.
This mode enables rapid validation of a Thread Group by running it with 1 thread, 1 iteration, no timers and no Startup delay set to 0.
The 3 first properties can be modified by setting in jmeter.properties:
testplan_validation.nb_threads_per_thread_group : Number of threads to use to validate a Thread Group, by default 1
testplan_validation.ignore_timers : Ignore timers when validating the thread group of plan, by default true.
testplan_validation.number_iterations : Number of iterations to use to validate a Thread Group, by default 1.
There are at least four ways to run JMeter behind the Proxy.
1. –> Config the Proxy Server into each HTTP Request.
In HTTP Request Sampler, you can find the Proxy Server under Advanced Tab.
2. Config the Proxy Server into HTTP Request Defaults.
3. Launch JMeter from the command line with the following parameters:
jmeter -H localhost -P 8888 -u username -a password -N localhost
NOTE: You can also use –proxyHost, –proxyPort, –username, and –password as parameter names.
jmeter –proxyHost localhost –proxyPort 8888
jmeter -n -H localhost -P 8888 -t C:\jmeter\my-test-plan.jmx -l C:\jmeter\my-test-plan-result.jtl -j C:\jmeter\my-test-plan-result.log
4. Set the Proxy properties into the System properties file.
Open the system.properties in edit mode, this file is located under /JMeter/bin/ directory
Add the following properties to the end of file.
If a non-proxy host list is provided, then JMeter sets the following System properties:
http.proxyHost=localhost
http.proxyPort=8888
https.proxyHost=localhost
https.proxyPort=8888
http.nonProxyHosts=example.com
https.nonProxyHosts=example.com
– setUp Thread Group: will be executed BEFORE the test proceeds to the executing of regular Thread Groups.
– tearDown Thread Group: will be executed AFTER the test proceeds to the executing of regular Thread Groups.
Deleting users that were created in the setUp Thread Group.
Cleaning up the system, deleting the data which were created during the test.
Send the email or any kind of notification to notify that the test has been stopped.
Collect some reporting stuff on response data.
A group of virtual users is represented in the JMeter application by a Thread Group.
A thread group is the base element (parent) needed in every test plan.
It is actually an assembly of threads executing the same scenario.
Thread Group – This can be used for simple load test scenarios, where you set a predefined number of users and ramp-up period and you start running your script in times. We can use Thread Group for Stress Testing also by increasing the concurrent users. This can be used for Endurance Testing by maintaining the load for predefined period of time.
JMeter Arrivals Thread Group element is specially created for the case where no. of orders to be submitted in an hour; is known. In such type of scenarios, more preference is given to the quantity of order irrespective no. of users. Apache JMeter adjust the number of threads according to the target arrival rate.
“Arrivals Rate” word is used for the rate of iteration (order submission). If I say 10 licenses are purchased in a minute which signifies that 10 iterations need to be started and completed in 1 minute. Hence the arrival rate will be 10/min. If I say 1000 movie tickets booking in an hour (16.6 = ~17/min), then it signifies that around 17 iterations should be started and completed in 1 minute, so arrival rate will be 17.
Target Rate = 120 Arrivals / min
Ramp-up Time: 1min
Step-Count: 10
Hold: 2min
Total Arrivals = Arrivals between 0-30 Sec + Arrivals between 30-60 Sec + Arrivals between 60-180Sec
0-30 Sec = 30 Arrivals
30-60 Sec = 60 based on (120 * 30/60)
60-180 = 120*2 = 240
Total Arrivals = 30+60+240 = 330 Arrivals/Min
It is similar to arrivals thread group, the difference is that this thread group does not have ramp up time and steps options.
The Start and End Values: Start value means arrival rate at the beginning of the time frame (duration) and end value means arrival rate at the end of the time frame (duration).
Start Value=30
End Value=60
Duration= 60 Sec
30 Arrivals will be added per Sec at the beginning of timeframe. 1 arrival for every 2 sec to reach target 60 arrivals by end of 60 sec.
Adding up all the arrival rates from 1st to 60th second gives total number of arrivals=30+30+31+31+32+32+….+60 ~= 2700.
This Thread group is also suitable for goal oriented scenarios, but the goal here is to have control over the number of concurrent users over a period of time.
Target Concurrency: The number of concurrent users which should be maintained after the ramp up.
Ramp Up Time: Timeframe required to reach target concurrency rate.
Ramp Up Steps: It refers to the granularity of the concurrency increase rate. More steps results in smoother pattern.
Hold Target Rate Time: The duration to maintain the target concurrency before starting to gradually shut down all threads.
Thread Iterations Limit: Limits the number of iterations.
The ultimate thread group is highly customizable and unlike the arrivals, or freeform and concurrency thread groups, this one kills the active threads after the set time has expired.
The start threads count field: You set the target thread concurrency.
The initial delay: Set how much time you wait before starting to execute the threads from that specific row.
The startup time: The ramp up time for all the threads set in the thread count. For example, for 20 threads and a start time of 20 seconds, you would have 1 new thread firing up every 1 second.
The hold load for field: This is where you set the duration to maintain the defined number of concurrent users and is totally independent from the ramp-up time.
The shutdown time: The time interval for killing all the active threads.
Timers can help to simulate a virtual user’s “think time”.
Timers allows JMeter to delay/pause between each request which a thread makes.
Rule 1: The Timers are executed before the sampler’s execution but after the PreProcessor.
Rule 2: The response time of the sampler does not include the execution time of the Timer.
The purpose of Constant Timer is to pause for the same amount of time between requests from each thread.
Parameterized the delay time: ${timer}
Random the delay time: ${__Random(1000,5000,)}
Uniform random timer is one of the Jmeter timer which is used to generate fixed+random amount of time delay between 2 requests.
Total amount of delay = Random Delay Maximum + Constant Delay Offset
Random Delay Maximum : This is outer boundary limit of random time delay. It will decide maximum random pause time.
Constant Delay Offset : This is the fixed delay time which will be added in random delay.
For Example:
Random Delay Maximum = 3000 milliseconds and Constant Delay Offset = 7000 milliseconds. That means it will put random delay between 7 seconds to 10 seconds between two requests.
You can use Synchronizing Timer If you wants to release X number of threads at given point. It will block the threads until given X number of threads have been reached at specific point. It will release all threads at once when given number of threads are reached on specific point of time.
You can use synchronizing timer on controller level or request level as per your requirement.
Using constant throughput timer, You can decide how many samples should be executed per minute. Constant throughput timer will add random pauses between requests during test execution to match required throughput.
Note : If you are using constant throughput timer in your software load test plan and server is not capable to handle the load or any other time consuming elements are available in your test plan then your targeted throughput(Which is set in constant throughput timer) will be not achieved.
Test Fragment:
Test Fragment element is a special controller which can be added directly under JMeter test plan like Thread Group. But It does nothing except holding other elements inside!! It gets executed only when it is referenced by a Module/Include controller from other Thread Groups. It acts like a library of reusable of scripts.
Module Controller:
Module Controller in JMeter is useful in referencing any of the logic controller in the JMeter Test Plan.
Parameterized Controller:
Parameterized Controllers contains the ‘User Defined Variables’ section, where you can specify your parameters. Put the credentials of the first user in the first parameterized controller and the second user credentials in the second parameterized controller.
Include Controller:
As a Module controller is used to call a logic controller in the Test Plan, Include Controller is used to reference an existing .jmx file itself.
Logic Controllers help you to control the flow of the order of processing of samplers in a thread. It can also change the order of requests coming from their child elements.
| Interleave Controller | Interleave controller will select only one sample / request stored in it, to run in each loop of the thread. It will execute the samplers in sequentially. |
| Once Only Controller | Requests added to this controller will run only once irrespective of number of users/loop count specified in the thread group. This comes into use, when one wants all other requests run more than once but a particular request or set of requests to run only once during the entire test plan. |
| Include Controller | Include Controller is made to use an external test plan. This controller allows the usage of multiple test plans in JMeter. |
| Runtime Controller | Runtime Controller controls the execution of its samplers/requests for the given time. For example, if you have specified Runtime(seconds) to 20, JMeter will run your test for 20 seconds only. |
| Loop Controller | Loop Controller will run the samplers/requests stored in it for the definite number of times or forever (if forever checkbox is selected). |
| Module Controller | The module controller adds modularity to the JMeter Test Plan. Module controller allows you to redirect test execution to a given fragment of the test or you can say selected module. |
| Recording Controller | Recording Controller is a place holder where the proxy servers can save recorded requests. It has no effects on test execution. |
| Transaction Controller | Useful to measure over all time taken to perform complete transaction. Transaction controller will add additional sample after nested samples to show total time taken by it’s nested samples. Generate parent sample Transaction controller has option “Generate parent sample” and “Include duration of timer and pre-post processors in generated sample” |
| Random Order Controller Example | Random order controller in apache jmeter is used to execute requests of jmeter software load test plan in random order. This is the only difference between simple controller and random order controller. |
| Random Controller | As you know, controllers in jmeter are useful to control execution flow in different ways. Random controller will execute any request randomly. It will pick any request from it’s request tree and force to execute is. Every time it will pick different request randomly. |
| Switch Controller | As name suggest, You can switch your targeted software application page request to run using Switch Controller. |
| IF Controller | If controller in jmeter allows you to set condition to evaluate it and based on condition evaluation result it will decide to run or not to run if controller’s child elements. If condition evaluation result is positive then child elements of if controller will run else child elements of if controller will not run. “${title}”==”Yahoo” |
| Throughput Controller | This controller does not control the Throughput. Primary objective of Throughput Controller is to define and control the User Load for each group separately under same Thread Group. Throughput Controller has 2 options: Total Executions, Percent Executions. 1) Total Executions: All child requests placed under this controller will be executed as per defined number. The thread creation will stop after the defined number of execution have occurred. – Per User Checked: The number given for throughput will be the total number of executions for current controller. – Per User Unchecked: Total number of Threads(Users) given under Thread Group will be the total number of executions for current controller. 2) Percent Executions: All child requests placed under this controller will be executed according to the percentage defined under Throughput field. |
| While Controller | The purpose of the While Controller is to repeat a given set of actions until the condition is broken. For example, you simulate a user who buys all the goods within a random product category. The number of goods to buy varies depending on the category. In JMeter, the While controller runs all the Samplers which are located underneath, unless some predetermined “Condition” is “true” where “Condition” could be: blank: exits when the last sampler in the loop fails, LAST: the same as blank, but with an additional check for the last Sampler before the loop result. If the preceding Sampler is not successful, the While Controller and its children won’t be executed at all, JMeter Function or Variable: children will be run until a variable or function evaluation result is false, JMeter Property: it works the same way as a Function or Variable, but assumes the value of a JMeter property instead. “${myVar}” != “some value” – doesn’t work, as it is neither a function nor a single variable. ${__javaScript(“${myVar}” != “some value”,)} – works OK as the expression resolves it to either be “true” or “false”. ${__javaScript(${counter}<=5)} ${__javaScript(parseInt(vars.get(“counter”))<=5)} ${__javaScript(! “${CFY_g4}”.endsWith(‘label1’) || (! “${CFY_g6}”.match(‘Current Fiscal YTD’)) )} |
Configuration elements can be used to set up defaults and variables for later use by samplers.
Types of Config Elements:
CSV Data Set Config – CSV Data Set Config is used to read lines from a file, and split them into variables. We can use __CSVRead() and _StringFromFile() JMeter in built functions to read data from file.
By default, the file is only opened once, and each thread will use a different line from the file. However the order in which lines are passed to threads depends on the order in which they execute, which may vary between iterations. Lines are read at the start of each test iteration.
| FTP Request Defaults | FTP Request Defaults config element is associated with FTP Request Sampler. This element is used when your going to send multiple requests to same FTP server. |
| HTTP Authorization Manager | The Authorization Manager lets you specify one or more user logins for web pages that are restricted using server authentication. You see this type of authentication when you use your browser to access a restricted page, and your browser displays a login dialog box. JMeter transmits the login information when it encounters this type of page. |
| HTTP Cookie Manager in Jmeter | Each JMeter thread has its own cookie storage area. The use of cookies eventually becomes necessary when your application has to maintain a session. Once you login to an application, it maintains the session of that user so that he/she can work inside the application. If that session is not maintained (via Cookie Manager in case of JMeter), then the user will be logged out of the application as soon as he/she sends the next request, which requires Authentication. You can take it like this, if your application has a session or uses cookies, then your script will not work without adding cookies in cookie manager, as then your script will not be able to maintain the session and the users (Threads) will be kicked-off the application as soon as they enter into it. Each JMeter thread has its cookie storage area. So, if you are testing a web site that uses a cookie for storing session information, each JMeter thread will have its session. |
| HTTP Request Defaults | This element lets you set default values that your HTTP Request controllers use. For example, if you are creating a Test Plan with 25 HTTP Request controllers and all of the requests are being sent to the same server, you could add a single HTTP Request Defaults element with the “Server Name or IP” field filled in. Then, when you add the 25 HTTP Request controllers, leave the “Server Name or IP” field empty. The controllers will inherit this field value from the HTTP Request Defaults element. |
| HTTP Header Manager | The Header Manager lets you add or override HTTP request headers. Ex: User-Agent Accept Accept-Encoding Accept-Language |
| User Defined Variables | The User Defined Variables element lets you define an initial set of variables , just as in the Test Plan . Note that all the UDV elements in a test plan – no matter where they are – are processed at the start. UDVs can be used with functions such as __P(), for example: HOST ${__P(host,localhost)} |
| Counter | Allows the user to create a counter that can be referenced anywhere in the Thread Group. The counter config lets the user configure a starting point, a maximum, and the increment. The counter will loop from the start to the max, and then start over with the start, continuing on like that until the test is ended. |
| Login Config Element | The Login Config Element lets you add or override username and password settings in samplers. |
| Simple Config Element | ‘Simple Config Element’ is used to add or override arbitrary values in samplers. You can choose the name of the value and the value itself. |
| JAVA Request Defaults | ‘Java Request Defaults’ is used to set default parameters to pass them into Java Request. Sleep_time Sleep_mask Label Response Code ResponseMessage Status SamplerData ResultData |
When testing your APIs, web service or other system parts, you might need to record or retrieve data from a database.
Before you start working with a database by using JMeter, you need to do the following:
Make sure there is a user who has permission to connect and perform common actions CRUD in the database.
Make sure the database is available for remote or local access.
To interact with the database it is necessary to:
1. Download the DB Connector Driver for specific DB (MySQL/MSSQL,etc)
2. Copy the DB Connector jar to ..\apache-jmeter-3.2\lib folder
3. Restart JMeter
4. Right click on Thread Group -> Add -> Config Element -> JDBC Connection Configuration
5. Fill in the Variable Name field. The value of this field is used to associate a specific connection configuration (JDBC Connection Configuration) to the database and a specific request (JDBC Request) sent by JMeter
6. Configure the JDBC Connection Configuration. Ex: jdbc:mysql://localhost:3306/DB_Name
7. JDBC driver class : com.mysql.jdbc.Driver
8. Provide User name and password for accessing the DB
JDBC Request:
1. Use the same variable name what given in JDBC Connection Configuration.
2. Set the Query Type. Ex: Select Statement
3. Result variable name – This variable will store all fields and field values received from the database.
If the variable name is blank.
java.lang.IllegalArgumentException: Variable Name must not be empty for element:JDBC Connection Configuration.
If the DB_Name is not given:
Response message: java.sql.SQLException: No database selected”
If the driver class was not found:
DataSourceElement: Could not load driver: {classname} java.lang.ClassNotFoundException: {classname}
If the database server is not running or is not accessible, then JMeter will report a java.net.ConnectException .
Clear Cache Each Iteration: The DNS Cache Manager caches the IP address -> the DNS hostname pairs and returns the cached value if the DNS hostname has a match in its internal cache. If this checkbox is ticked, the cache will be cleared at the start of the thread.
Use System DNS Resolver: The DNS Cache Manager will query DNS Server(s) defined in your OS network configuration in order to determine the hostname for each thread representing virtual users. In this case, you need to override the networkaddress.cache.ttl property in the $JAVA_HOME/jre/lib/security/java.security file and set it to 0 (the property defaults to “-1” which stands for “forever”)
Use Custom DNS Resolver: You can specify one or more DNS servers in the list.
If more than one server is provided, the DNS Cache Manager will choose a random one for each call – and will run as a round-robin mechanism.
If nothing is provided, the system DNS resolver will be used (the DNS server/s defined in your OS network configuration).
The DNS Cache Manager – Quick Tips and Troubleshooting
1. Where to put the DNS Cache Manager
The DNS Cache Manager should be added as a child of the Test Plan or a Thread Group element.
2. Always Use HTTPClient4
Make sure that you have HTTPClient4 selected in “Implementation” drop-down
3. Enable Logging
It’s easy to enable logging on the DNS Cache Manager. Just append the following parameter to the JMeter startup script:
-Ljmeter.protocol.http.control.DNSCacheManager=DEBUG
as
java -jar ApacheJMeter.jar -Ljmeter.protocol.http.control.DNSCacheManager=DEBUG
or
jmeter.bat -Ljmeter.protocol.http.control.DNSCacheManager=DEBUG
Keystore configuration element in JMeter helps to configure the Client’s side certificate. Some systems require a Client-side certificate which helps the server to know exactly who is connecting.
Before adding a Keystore Configuration element, you must set up a Java Key Store with the client certificates that you want to test. Follow the below steps:
#1 Create your certificates either with Java keytool utility or through your PKI and converting them to a format acceptable by JKS: If you have a PKCS12 file, use the following command line to convert it to a JKS file:
keytool -importkeystore -srckeystore certificate.p12 -srcstoretype PKCS12
-srcstorepass
-keystore -storepass
#2 Changes need to be done in system.properties file (if not available (or commented) then add (or uncomment) them:
javax.net.ssl.keyStore=path_to_keystore
javax.net.ssl.keyStorePassword=password_of_keystore
#3 Change your HTTP sampler implementation to Java (instead of HC3.1 or HC4)
Keystore Configurations:
Preload: This option helps you to choose whether you want preload Keystore or not?
Variable name holding certificate alias: Variable name that will contain the alias to use for authentication by client certificate.
Alias Start Index: The index of the first key to use in Keystore, 0-based
Alias End Index: The index of the last key to use in Keystore, 0-based. When using “Variable name holding certificate alias” ensure it is large enough so that all keys are loaded at startup.
The assertion in JMeter is used to validate the response of the request, that you have sent to the server. The assertion is a process where you verify the expected result with the actual result of the request at run time. If you need to apply assertion on a particular Sampler, then add it as a child of that Sampler.
Response Assertion – It facilitates the user by comparing the server response against a string pattern to check that the result is as expected.
Duration Assertion – Duration assertion is used to verify how long a request takes to complete. The Duration measured in milliseconds, and, if any request lasts longer than the value specified, the sample is marked as failed.
Size Assertion – It is to test that each response coming from server holds the expected number of bytes. It facilitates the user to specify the size.
XML Assertion – The XML Assertion checks that the returned response body is XML-compliant. Only the syntax is checked. Any external resources are neither downloaded nor validated.
HTML Assertion – The HTML Assertion checks that the response HTML syntax is a well-formed HTML/XHTML/XML document. So it is handy if your Web application or site requires zero HTML validation errors.
Beanshell Assertion:
String path = SampleResult.getURL().getPath();
if (!path.contains(“blazemeter”)) {
Failure = true;
FailureMessage = “URL Path: didn’t contain ‘blazemeter'” + System.getProperty(“line.separator”) + “URL Path detected: ” + path;
}
Compare Assertion:
The Compare Assertion checks the response content or confirms that the response time of all samplers under the assertion scope is equal.
User Parameter is a preprocessor whereas CSV Data Set Config and User Defined Variables are Config Elements.
In User Defined Variables, there is only one value of the variable can be defined whereas, in User Parameters and CSV Data Set Config, multiple values can be defined for a variable.
Test Data cannot be added via an external file in User Parameters and User Defined Variables whereas CSV Data Set Config use .csv file format as a test data.
Since there is only one value can be given in User Variables so bulk test data can not be used. The bulk test data can be added manually in User Parameters, but it is time-consuming. Although the primary purpose of CSV Data Set Config is to access an external file so that bulk test data can be available for the test.
The use of the regular expression is to extract the data from the responses in JMeter. It is also used in capturing dynamic value from the response.
The special characters above are −
( and ) − these enclose the portion of the match string to be returned
. − match any character
+ − one or more times
? − stop when first match succeeds
Template: $1$ to refers to group 1, $2$ to refers to group 2, etc. $0$ refers to whatever the entire expression matches.
Match No: 1 for first match, 2 for second match, 0 for random.
CSS Selectors are patterns to select elements with the following syntax:
.class
#id
* All elements
div, p all div and p elements
div p all p elements inside div elements
JQuery Selectors can just do the same as CSS Selectors, but with a different syntax:
$(“*”) All elements
$(“#id”)
$(“.class”)
$(“.class,.class”) — $(“.intro, .demo”) – all class elements with the class intro or demo
$(“h1,div,p”) all h1, div and p elements
option used for html response which for cleaning up malformed and faulty html. It doesn’t work with XML or XHTML response
Result Status Action Handler allows the user to stop the thread or whole test according to sampler result.
Here it defines the action to be taken after a sampler error.
Continue: This option ignores the error and continues the test.
Start next thread loop: It does not execute the test for current iteration when it found an error and restarts the loop on next iteration.
Stop Thread: In this option current thread exits.
Stop Test: In this option, the whole test is stopped at the end of any current sample.
Stop Test Now: The entire test is stopped here. Any current samplers are interrupted if possible.
Java applications obtain objects in memory as needed. It is the task of garbage collection (GC) in the Java virtual machine (JVM) to automatically determine what memory is no longer being used by a Java application and to recycle this memory for other uses.
Java garbage collection is the process by which Java programs perform automatic memory management. The garbage collector finds these unused objects and deletes them to free up memory.
What are the different types of garbage collectors in Java?
- Serial Garbage Collector – it works for standalone application. If you use serial GC for distributed applications, u will observe high performance issues.
- Parallel Garbage Collector.
- CMS Garbage Collector (Concurrent Mark Sweep).
- G1 Garbage Collector.
The Java heap is the area of memory used to store objects instantiated by applications running on the JVM. Objects in the heap can be shared between threads. Many users restrict the Java heap size to 2-8 GB in order to minimize garbage collection pauses.
Heap memory should not be greater than physical memory on your system.
Min size of heap memory can be 1/64th sized of system physical memory.
Max size of heap memory can be 1/4th size of system physical memory.
Jave Heap contains New/Young Generation and Old/Tenured Generation.
In New/Young Generation, we have Eden and Survival space. Survivor has two survivor spaces S0 and S1.
Till JDK7, we have perm gen space. From JDK8 onwards, this has been converted to metaspace.
Increasing the heap memory doesn’t fix the outofmemory exception. It might reproduce after sometime.
Increasing the heap size, will improve the response time.
When heap size is increased, GC activities will increase (Minor/Major/Full GC).
When GC activities increases, it suspends all threads for the time GC is running and it impacts the total response time.
| To check the default Heap and PermGen sizes | Run this command: java -XX:+PrintFlagsFinal -version | findstr /i “HeapSize PermSize ThreadStackSize” |
| How to check which GC is running on your system? | Run this command: java -XX:+PrintCommandLineFlags -version |
| To change from Parallel GC mode to G1GC mode | Run this command: java -XX:+UseG1GC -XX:+PrintCommandLineFlags – version |
| Garbage collection happens in three phases | 1. Marking – Marks all the objects which are referenced/reachable 2. Delete / Sweep – deletes all the unreachable objects 3. Compaction – brings the used memory to one side and free to other side |
| Why should we use G1GC | It will go to either Young, Old or Perm Gen space, whichever is full and performs GC activity. |
| Serial GC | It is available right from the first version of JAVA. It is single threaded, Mark and Sweep Collector. USed for small applications. Disadvantages: It pauses all application threads whenever it is working. It is single threaded. When should we use Serial GC: 1. It is used for small amount of heap (approx. 100MB) 2. It runs in single thread. It is best suited to single processor machine 3. Application with medium sized to large sized data sets that run on multiprocessor or multithreaded hardware. |
| Parallel Collector | It is similar to Serial Collector but multiple threads are used to speedup garbage collection. Does not kick in until heap is full or almost full. Stops the world pause when runs. When should we use Parallel GC: If peak application performance (throughput) is the priority. If there are no pause time requirements or pauses of 1 second or longer are acceptable. |
| Concurrent Mark Sweep (CMS) Collector | Iniitial Mark – pauses all application threads. It will identify the live objects which are connected to GC roots. Concurrent Mark – It identifies objects which are directly or indirectly connected to the initially markd live objects. Concurrent Preclean – If any new objects created during the above process. Re-mark – Pauses all application threads. Usually longer than the initial mark. Sweep – all unreach objects are sweeped. Concurent Reset – resets the heap memory Works on old generation. It works when the old generation is amost 80% full. Advantages: very low pause time; as many phases run concurrently with application. Disadvantages: It causes heap fragmentation, as there is no compacting phase. Concurrent mode failure: If the CMS collector is unable to finish reclaiming the unreachable objects before the tenured generation fills up. If the CMS is unable to move the objects from young generation to tenured generation and there is no space for this object in tenured generation, this is called concurrent mode failure. When should we use Serial GC: If application response time is more important than overall throughput. If garbage collector pauses must be kept shorter than 1 sec. |
| G1 GC | New in JAVA 6. Officially supported in Java 7. G1 is planned as long term replacement for CMS. G1 supports heaps larger than 4 GB. and is parallel, concurrent and incrementally compacting low pause garbage collector. With G1, heap is partitioned into a set of equal size heap regions. A total of approx. 2000 regions, in which each region would be of size 1MB to 32 MB. determined by JVM. The principle of G1GC is to reclaim the JAVA heap by collecting the region with mostly occupied unreachable objects, hence the name Garbage first. Evacuation – Live objects are moved from young generation either into survivor regions or old/tenured generation. Remembered Sets or RSets – track object references into a given region. There is one RSet per region in the heap. Collection Sets or Csets the set of regions that will be collected in a GC. CSet is evacuated (copied/moved) during a GC. Set of regions can be Eden, Survivor, and/or old generation. When should we use Serial GC: 1. Large heapsize. 2. Full GC durations are too long or too frequent 3. The rate of object allocation rate or promotion varies significantly 4. Undesired long garbage collection or compaction pauses (longer than 0.5 to 1 sec) |
Preconditions:
Make sure that you will have the same JMeter version (always use the latest one) on all machines (slaves and master).
Confirm that master and slaves are under the same subnet.
Assure that firewalls on the operative systems are turned off.
It is recommended to have the same java version on all machines (master and slaves).
Check that all slaves have the plugins that will be used by the test script that will have its execution triggered by the master node. Master sends the .jmx file to its slaves but it does not send the required plugins.
Test data files (such as .csv files) also need to be manually copied to the slaves once it is also not done by the master.
Slaves Setup
RMI Keystore Generation
Since JMeter 4.0, the default transport mechanism for RMI will use SSL by default. If you don’t want to use it, then it will be needed to open the jmeter.properties file, uncomment the line where server.rmi.ssl.disable property is located and change it from false to true.
server.rmi.ssl.disable=false
Configuring the slaves’ firewalls
By default, RMI uses dynamic ports for the JMeter server engine. This can cause problems for firewalls once you would need to allow incoming connections from different ports every time you start the jmeter-server script (.bat for windows and .sh for Unix) on a JMeter slave.
In order to avoid using random ports, you will need to set a specific value:
server.rmi.localport=4000
Master Setup
Configuring the master node is simpler than doing that for the slave nodes. You just need to open the jmeter.properties file, find the remote_hosts property, uncomment it and type the ip addresses
remote_hosts=172.10.0.40
Starting Slaves and Master
We are almost there, but before executing the test script we just need to initialize the slaves and master. In order to start a slave (or server) you need to go to the JMeter/bin folder, find the jmeter-server (.bat on Windows and .sh on Unix) file and execute it.
Starting the master is pretty straight forward. Just go to jmeter/bin and open jmeter (.jar or .bat on Windows and .sh on Unix). Open a .jmx file and go to Run >> Remote Start All
Limitations
RMI cannot communicate across subnets without a proxy; therefore neither can jmeter without a proxy.
Since JMeter sends all the test results to the controlling console, it is easy to saturate the network IO. It is a good idea to use the simple data writer to save the results and view the file later with one of the graph listeners.
Unless the server is a large multiprocessor system, in most cases 1–2 clients is sufficient to overwhelm the server.
Processor is used to modify the Samplers in their scope.
There are 2 Types of processors:
Pre-processor – Pre-processor executes some action before making Sampler Request.
Post-processor – Pos-Processor will be executed when a Sampler Request finishes its execution.
Post-Processor in JMeter
1. Regular Expression Extractor: – Regular Expression Extractor is used to extract values from the response of test server using a Perl-Type Regular Expression.
2. XPath Extractor: – XPath Extractor element is used to extract values from structured response XML or (X)HTML by using XPath query language. use Tidy to parse HTML response into XHTML.
3. Result Status Action Handler: – Result Status Action Handler element can be used to stop the thread or the test if the relevant sampler gets failed.
Pre-Processor in JMeter
A Post-Processor executes after a sampler finishes its execution. This element is most often used to process the response data.
The Transaction Controller generates an additional sample which measures the overall time taken to perform the nested test elements.
When the check box “Include duration of timer and pre-post processors in generated sample” is checked, the time includes all processing within the controller scope, not just the samples.
The Throughput Controller allows the user to control how often it is executed. There are two modes – percent execution and total executions.
Percent executions causes the controller to execute a certain percentage of the iterations through the test plan. Total executions causes the controller to stop executing after a certain number of executions have occurred.
In JMeter, spike testing can be achieved by using Synchronizing Timer. The threads are jammed by synchronizing the timer until a specific number of threads have been successfully blocked, and then release them at once thus creating large immediate load.
Correlation is the process of capturing and storing the dynamic response from the server and passing it on to subsequent requests. … Correlation is a critical process during performance load test scripting, because if it isn’t handled correctly, our script will become useless.
- Configuration elements
- Pre-Processors
- Timers
- Sampler
- Post-Processors (unless SampleResult is null)
- Assertions (unless SampleResult is null)
- Listeners (unless SampleResult is null)
Pacing in load testing refers to the time between the iterations of your test scenarios. This is unlike Think Time, which refers to the delay between actions or interactions inside iterations. Pacing allows the load test to better simulate the time gap between two sessions.
By using pacing in your test, you will be able to regulate the rate of requests that hit your application and accurately achieve a desired load. This will allow you find out the exact load capacity your application can handle.
Below timers are used to implement pacing in Jmeter to achieve the desired load/Business transactions.
1.Precise Throughput Timer
2.Constant Throughput Timer
3.Throughput Shaping Timer
Think Time: The wait time between transactions is called think time.
Pacing Time: The wait time between iterations is called Pacing Time.
The first thing which you need to check is ‘Type of Error‘. Without knowing the type you can not investigate. During the performance test, you may get different types of error like client-side error, server-side error etc.
Scriptings Errors:
a). Missed to replace old URLs in some places: This causes the failure of a particular transaction.
b). Lack of test data: Sometimes tester forgets to set “recycle the test data list” or “continue with last value”
c). LG failed during the test: This issue occurs when LG(s) are unable to handle user load during the test.
d). LG memory issue: This issue comes when there is no enough memory in LG. LG may get disconnected in between the test.
e). HTTP 4XX: Refer response code graph, if the test result having HTTP 4XX error then this indicates something wrong has been sent to the server.
HTTP 4XX followed by 5XX: Again this is a syntax of client-side error, but not always. This is a tricky scenario where you have to carefully analyse the previous requests having 4XX response code and the following request having 5XX response code.
Following are the tricks that help in reducing resource usage.
1. Use a non-GUI mode.
jmeter -n -t test.jmx -l test.jtl
2. It is better to use as few Listeners as possible. Applying the “-l” flag as shown in above point may delete or disable all the Listeners.
3. Disable the “View Result Tree” listener as it consumes a lot of memory and may result in JMeter tool running out of memory. It will freeze the console too. It is, however, safe to use the “View Result Tree” listener with only “Errors” kept checked.
4. Instead of using a similar Sampler a large number of times, use the same Sampler in a loop and use variables (CSV Data Set) to vary the sample data. Or perhaps use the Access Log Sampler.
5. Avoid using functional mode.
6. Use CSV output rather than XML.
Also, you may like to read some of the common points.
7. Try to save the data that you need.
8. Use as few Assertions as possible.
9. Disable all JMeter graphs as they consume a lot of memory. All the real-time graphs can be viewed using the JTL tab in the web interface.
10. Do not forget to erase the local path from CSV Data Set Config when used.
11. Cleaning of the Files tab before every test run.
JMeter has all the capabilities to behave like a real browser and still maintain high scalability. For this, the following config elements should be added to JMeter:
A cache manager to simulate the browser’s cache.
A cookie manager to simulate the browser’s cookies.
In the header manager include a user agent line. (We recommend recording from your own browser).
Use thread/connection pool to simulate the browser parallel fetching (use between 2-4).
Ask JMeter to retrieve embedded resources to simulate a browser retrieving embedded resources (such as gifs, css, js etc).
In Apache JMeter, we can simulate network bandwidth very easily.
Following are the steps to simulate network bandwidth:
Open ‘jmeter.properties’ file in notepad (location: apache-jmeter/bin)
Search ‘cps’ (characters per second) you will find
Define characters per second > 0 to emulate slow connections
#httpclient.socket.http.cps=0
#httpclient.socket.https.cps=0
Change cps value as per your need
cps = rb*128 (rb= Required Bandwidth)
cps = (target bandwidth in kbps * 1024) / 8
| Bandwidth | cps Value |
| GPRS | 21888 |
| 3G | 2688000 |
| 4G | 19200000 |
| WIFI 802.11a/g | 6912000 |
| ADSL | 1024000 |
| 100 Mb LAN | 12800000 |
| Gigabit Lan | 128000000 |
- IConfigurable
- IExecutionListener
- IAnnotationTransformer
- IHookable
- IInvokedMethodListener
- IInvokedMethodListener2
- IConfigurationListener
- IReporter
- ITestListener
- IMethodInterceptor
- ISuiteListener
The Robot class helps in providing control over the mouse and keyboard devices. It includes:
- KeyPress()
Invoked when you want to press any key
- KeyRelease()
Invoked to release the pressed key on the keyboard
- MouseMove()
Invoked to move the mouse pointer in the X and Y coordinates
- MousePress()
Invoked to press the left button of the mouse
String PROXY = "199.201.125.147:8080";
org.openqa.selenium.Proxy proxy = new.org.openqa.selenium.Proxy();
proxy.setHTTPProxy(Proxy)
.setFtpProxy(Proxy)
.setSslProxy(Proxy)
DesiredCapabilities cap = new DesiredCapabilities();
cap.setCapability(CapabilityType.PROXY, proxy);
WebDriver driver = new FirefoxDriver(cap);JavaScriptExecutor is an interface which provides a mechanism to execute Javascript through the Selenium WebDriver. It provides “executescript” and “executeAsyncScript” methods, to run JavaScript in the context of the currently selected frame or window. An example of that is:
JavascriptExecutor js = (JavascriptExecutor) driver;
js.executeScript(Script,Arguments);public static void main(String[] args)
{
String baseUrl = “https://www.facebook.com”;
WebDriver driver = new FirefoxDriver();
driver.get("baseUrl");
WebElement txtUserName = driver.findElement(By.id(“Email”);
Actions builder = new Actions(driver);
Action seriesOfActions = builder
.moveToElement(txtUerName)
.click()
.keyDown(txtUserName, Keys.SHIFT)
.sendKeys(txtUserName, “hello”)
.keyUp(txtUserName, Keys.SHIFT)
.doubleClick(txtUserName);
.contextClick();
.build();
seriesOfActions.perform();
}To maximize the size of browser window, you can use the following piece of code:
driver.manage().window().maximize(); – To maximize the window
To resize the current window to a particular dimension, you can use the setSize() method. Check out the below piece of code:
System.out.println(driver.manage().window().getSize());
Dimension d = new Dimension(420,600);
driver.manage().window().setSize(d);To set the window to a particular size, use window.resizeTo() method. Check the below piece of code:
((JavascriptExecutor)driver).executeScript(“window.resizeTo(1024, 768);”);
To upload a file we can simply use the command element.send_keys(file path). But there is a prerequisite before we upload the file. We have to use the html tag: ‘input’ and attribute type should be ‘file’.
element = driver.find_element_by_id(”uploaded_file")
element.send_keys("C:myfile.txt")We can enter/ send text without using sendKeys() method. We can do it using JavaScriptExecutor.
JavascriptExecutor jse = (JavascriptExecutor) driver;
jse.executeScript("document.getElementById(‘Login').value=Test text without sendkeys");WebDriverWait wait = new WebDriverWait(driver, 10);
Alert alert = wait.until(ExpectedConditions.alertIsPresent());
alert.authenticateUsing(new UserAndPassword(**username**, **password**));Since there will be popup for logging in, we need to use the explicit command and verify if the alert is actually present. Only if the alert is present, we need to pass the username and password credentials.
@Test(invocationCount=?) is a parameter that indicates the number of times this method should be invoked.
@Test(threadPoolSize=?) is used for executing suites in parallel. Each suite can be run in a separate thread.
To specify how many times @Test method should be invoked from different threads, you can use the attribute threadPoolSize along with invocationCount.
@Test(threadPoolSize = 3, invocationCount = 10)
public void testServer() {
}This can be done by simulating key presses on the focused element. One way is to perform “actions” on the web driver object:
new Actions(webDriver).sendKeys(“some text”).perform();
An alternative way is to switch to the active element first, and send keys to it directly:
webDriver.switchTo().activeElement().sendKeys(“some text”);
import java.time.format.DateTimeFormatter;
import java.time.LocalDateTime;
public class CurrentDateTimeExample1 {
public static void main(String[] args) {
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss");
LocalDateTime now = LocalDateTime.now();
System.out.println(dtf.format(now));
}
} Charles Proxy is a web debugging proxy tool that can be used to monitor and tamper with web traffic. It can be used to debug web applications, inspect HTTP requests and responses, and even simulate slow internet connections.
- Executing test cases with various operating systems
- Testing application’s functionalities on a wide range of handsets
- Screen size fragmentation
- Testing applications on different mobile networks
- Different application types (native, hybrid or web app) require different ways to test
- The choice of the right mobile testing tool for QA team
There are various tools available in the market like google play or app store from where you can install apps like CPU Monitor, Usemon, CPU Stats, CPU-Z etc these are an advanced tool which records historical information about processes running on your device.
Hire QA is hiring for the position of Trainee Test Engineers for our clients.
- Location: Hyderabad
- Experience: 0-2 Years
- Skills Required: Manual Testing, Test Case Design, Test Execution, Bug Reporting, Postman, API Testing, Mobile App Testing, SQL, Selenium WebDriver, JAVA
Strong knowledge and experience in
- SDLC Models, Agile Methology.
- Requirement analysis, test case design, test case execution.
- Identify, record and track bugs to closure.
- Test Strategy and Test Planning.
- Good experience in testing Web Apps, REST APIs, Mobile Apps
- Good knowledge on SQL Queries
Seetest, Perfecto Mobile, BlazeMeter, AppThwack, Manymo, DeviceAnywhere etc.
The number of digits in a mobile phone number decide the maximum mobile phones we can have without dialing the country code.
- Accurate, or specific about the purpose.
- Economical, meaning no unnecessary steps or words are used.
- Traceable, meaning requirements can be traced.
- Repeatable, meaning the document can be used to perform the test numerous times.
- Reusable, meaning the document can be reused to successfully perform the test again in the future.
// identify text
WebElement t = driver.findElement(By.tagName("h1"));
//obtain color in rgba
String s = t.getCssValue("color");
// convert rgba to hex
String c = Color.fromString(s).asHex();
System.out.println("Color is :" + s);
System.out.println("Hex code for color:" + c);// identify element
WebElement l=driver.findElement(By.className("fb_logo _8ilh img")); // getAttribute() to get src value
String value = l.getAttribute("src");
System.out.println("Src attribute is: "+ value);// identify element
WebElement l=driver.findElement(By.cssSelector(".gsc-input"));
//activeElement() to verify element focused
if(l.equals(driver.switchTo().activeElement()))
System.out.println("Element is focused");
else
System.out.println("Element is not focused");We can click on an element which is hidden with Selenium webdriver. The hidden elements are the ones which are present in the DOM but not visible on the page. Mostly the hidden elements are defined by the CSS property style=”display:none;”. In case an element is a part of the form tag, it can be hidden by setting the attribute type to the value hidden.
Selenium by default cannot handle hidden elements and throws ElementNotVisibleException while working with them. Javascript Executor is used to handle hidden elements on the page. Selenium runs the Javascript commands with the executeScript method. The commands to be run are passed as arguments to the method.
Now let us enter some text inside the hidden text box.
// Javascript executor class with executeScript method
JavascriptExecutor j = (JavascriptExecutor) driver;
// identify element and set value
j.executeScript ("document.getElementById('text-box').value='Selenium';");
String s = (String) j.executeScript("return document.getElementById('text-box').value");
System.out.print("Value entered in hidden field: " +s);We can perform double click on elements in Selenium with the help of Actions class. In order to perform the double click action we will use moveToElement() method, then use doubleClick() method. Finally use build().perform() to execute all the steps.
// doubleClick() method for double click to an element after moving to
//element to with the moveToElement()
Actions a = new Actions(driver);
a.moveToElement(driver.findElement(By.xpath(“input[@type=’text’]))).
doubleClick().
build().perform();We can click on a button with across browsers with Selenium webdriver. First of all we need to identify the element with the help of locators like xpath or css, then apply sendKeys() method where the path of the file to be uploaded is passed.
// identify element
WebElement l=driver.findElement(By.cssSelector("input[type='file']"));
// file path passed with sendkeys()
l.sendKeys("C:\Users\ghs6kor\Pictures\Desert.jpg");Hire QA is hiring for the position of Web App Automation Engineers for our clients.
- Location: Hyderabad / Chennai
- Experience: 3-6 Years
- Skills Required: Cypress, Javascript
Strong knowledge and experience in
- Immediate joiner with strong experience in web app automation using Cypress and Javascript
- Experience or knowledge in automation framework design or improvisation.
The following are the two different ways you can type text into the text box fields in Selenium:
Using sendKeys():
– driver.findElement().sendKeys();
Using JavascriptExecutor:
– JavascriptExecutor jse = (JavascriptExecutor)driver;
– jse.executeScript(“document.getElementById(“username”).setAttribute(‘value’,’hireqa’)”);
Different types of verification points in Selenium are:
To check element is present
if(driver.findElements(By.Xpath(“value”)).size()!=0){
System.out.println(“Element is present”);
}else{
System.out.println(“Element is absent”);
}
To check element is visible
if(driver.findElement(By.Id(“submit”)).isDisplayed()){
System.out.println(“Element is visible”);
}else{
System.out.println(“Element is visible”);
}
To check element is enabled
if(driver.findElement(By.Id(“submit”)).isEnabled()){
System.out.println(“Element is enabled”);
}else{
System.out.println(“Element is disabled”);
}
To check text is present
if(driver.getPageSource().contains(“Text”)){
System.out.println(“Text is present”);
}else{
System.out.println(“Text is not present”);
}
We can pause test execution for 5 seconds by using the wait command.
driver.wait(5);
java -jar selenium-server.jar -htmlSuite “*firefox” “localhost” “C:\mytestsuite.html” “C:\results.html”
if(driver.findElements(Locator).size()>0
{
return true
}else
{
return false
}
}driver.getPageSource().contains(“TEXT that you want to see on the page”);
This function will fetch message on Pop-up
public static String getPopupMessage(final WebDriver driver) {
String message = null;
try {
Alert alert = driver.switchTo().alert();
message = alert.getText();
alert.accept();
} catch (Exception e) {
message = null;
}
System.out.println("message"+message);
return message;
}This function will Canceling pop-up in Selenium-WebDriver
public static String cancelPopupMessageBox(final WebDriver driver) {
String message = null;
try {
Alert alert = driver.switchTo().alert();
message = alert.getText();
alert.dismiss();
} catch (Exception e) {
message = null;
}
return message;
}public static String tooltipText(WebDriver driver, By locator){
String tooltip = driver.findElement(locator).getAttribute("title");
return tooltip;
}
public static void selectRadioButton(WebDriver driver, By locator, String value){
List select = driver.findElements(locator);
for (WebElement element : select)
{
if (element.getAttribute("value").equalsIgnoreCase(value)){
element.click();
}
}public static void selectCheckboxes(WebDriver driver, By locator,String value)
{
List abc = driver.findElements(locator);
List list = new ArrayListArrays.asList(value.split(",")));
for (String check : list){
for (WebElement chk : abc){
if(chk.getAttribute("value").equalsIgnoreCase(check)){
chk.click();
}}}}public static void downloadFile(String href, String fileName) throws Exception{
URL url = null;
URLConnection con = null;
int i;
url = new URL(href);
con = url.openConnection();
// Here we are specifying the location where we really want to save the file.
File file = new File(".//OutputData//" + fileName);
BufferedInputStream bis = new BufferedInputStream(con.getInputStream());
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream(file));
while ((i = bis.read()) != -1) {
bos.write(i);
}
bos.flush();
bis.close();
}Advantages:
- Cypress framework captures snapshots at the time of test execution. This allows QAs or developers to hover over a specific command in the Command Log to see exactly what happened at that particular step.
- One doesn’t need to add explicit or implicit wait commands in test scripts, unlike Selenium. Cypress waits automatically for commands and assertions.
- Developers or QAs can use Spies, Stubs, and Clocks to verify and control the behavior of server responses, functions, or timers.
- The automatic scrolling operation ensures that an element is in view before performing any action (for example Clicking on a button)
- Earlier Cypress supported only Chrome testing. However, with recent updates, Cypress now provides support for Firefox and Edge browsers.
- As the programmer writes commands, Cypress executes them in real-time, providing visual feedback as they run. Cypress carries excellent documentation.
Limitations:
- One cannot use Cypress to drive two browsers at the same time
- It doesn’t provide support for multi-tabs
- Cypress only supports JavaScript for creating test cases
- Cypress doesn’t provide support for browsers like Safari at the moment.
- Limited support for iFrames
Cypress only supports the Cascading Style Sheets (CSS) selectors to identify the elements.However, it can also work with xpath, with the help of the ‘Cypress-Xpath’ plugin.
Syntax with attribute-id and tagname is tagname#id − input#user_email_login or #user_email_login
Syntax with attribute-class and tagname is tagname.class − input.user_email_ajax or .user_email_ajax
Syntax with any attribute value and tagname is tagname[attribute=’value’] − input[id=’user_email_login’]
* Match all element that contains the value
cy.get(‘[class*=”class-name”]’)
$ Match all element that ends with the value
cy.get(‘[class$=”class-name”]’)
^ Match all element that starts with the value
cy.get(‘[class^=”class-name”]’)Cypress provides various methods to work with the first element, last element, or element at a specific index, then you need to use the first(), last(), or eq() functions along with cy.get().
Get the first Element in Cypress
The function .first() is used to get the first element in a set of elements
For Example:
cy.get(‘.name-text-box’).first()
Get the last Element in Cypress
Similar to the above example, here .last() function is used to get the last element in a set of elements.
For Example:
cy.get(‘.mobile-text-box’).last()
Get the specific element by index in Cypress
To get a specific element in the set of elements, using eq() function along with cy.get(‘.msg-body’) as shown below
For Example:
cy.get(‘.text-box’).eq(2)
Get Element By Containing Text in Cypress
Cypress provides contains() function along with the tag name and should be able to get the element.
The above approach is most useful to find the href link by Text in Cypress
For Example:
cy.get(‘a:contains(“Forgotten password?”)’).first().click()
Get DOM Element containing Text in Cypress
Cypress provides contains() function, which can be used with cy command or can be chained with cy.get() command to get the DOM element as seen in the examples below
Example 1:
Find the element having Text Sign In
cy.contains(‘Sign In’);
The above command searches for Text ‘Sign In’ inside the web page and returns the element. However, the command doesn’t check which type of element it is.
Example 2:
Find the DOM element having Text Sign In
cy.get(‘a’).contains(‘Sign In’);
The above command searches for all tags and returns the element if is having text ‘Sign In’. So, considering the first example, this approach is more specific to the tag name.
Cypress allows the use of regular expressions inside contains() function.
As seen in the below example, you can search for the element containing text that starts with b and has one or more word characters (numbers, alphabets, and _)
cy.contains(/^b\w+/)
To ignore the Case Sensitivity while using regular expressions inside contains() function, use { matchCase: false }
cy.get(‘div’).contains(‘capital sentence’, { matchCase: false })
To get the descended DOM element of a specific locator, use cy.find() function as seen in the example below:
For HTML Code
The following command returns all ordered list (li) elements inside the unordered list (ul) element
cy.get(‘#parent’).find(‘li’)
Get the Next Sibling in Cypress
The .next() function returns the next sibling in Cypress as seen below
cy.get('#my_ele').next();
Get the next sibling which is an input tag:
cy.get('#my_ele').next('input');
Get the Previous Sibling in Cypress
The .prev() function returns the previous sibling in Cypress as seen below
cy.get('#my_ele').prev();
Get the previous sibling which is an input tag, use the following command:
cy.get('#my_ele').prev('input');
Get All Next Siblings in Cypress
The .nextAll() function returns the next sibling in Cypress as seen below
cy.get('#my_ele').nextAll();
Get All Previous Sibling in Cypress
The .prevAll() function returns the previous sibling in Cypress as seen below
cy.get('#my_ele').prevAll();
Get Any Siblings
The .siblings() function is used to find the siblings in Cypress as seen below
cy.get('li').siblings('.active')
Or
cy.get('li').siblings()Get The Siblings Until in Cypress
The functions .nextUntil() and .prevUntil() allows you to get all the siblings before or after a certain condition.
For example, to get all the next sibling elements until the element class name is ‘my_class_name’, use the command as seen below:
cy.get('li').nextUntil('.my_class_name')
Get previous sibling element until the element class name is ‘my_class_name’, use the command as seen below:
cy.get('li').prevUntil('.my_class_name')Within Command in Cypress
The .within() function scopes all subsequent cy commands within this element as seen in the example below:
For HTML Code
The following command will search for the elements only within the form, instead of searching the whole code, and returns only the relevant elements within the form,
cy.get('form').within(($form) => {
// cy.get() will only search for elements within form,
// not within the entire document
cy.get('input[name="email"]').type('eaxample@email.com')
cy.get('input[name="password"]').type('mypassword')
cy.root().submit()
})Cypress doesn’t support XPath out of the box, however, if you are already familiar with XPath then you can use the third-party plugin cypress-xpath to get the HTML element by XPath by using the following steps:
Step 1: Install the cypress-xpath plugin using the below command:
npm install -D cypress-xpath
Step 2: Set Up XPath plugin
Navigate to cypress/support/index.js and add the below line
require('cypress-xpath')
Step 3: Use cy.xpath() command in the script as seen in the example below
it('finds list items', () => {
cy.xpath('//ul[@class="todo-list"]//li')
.should('have.length', 3)
})
To get specific elements using XPath you can also chain the cy.xpath() to another command as seen below
it('finds list items', () => {
cy.xpath('//ul[@class="todo-list"]')
.xpath('./li')
.should('have.length', 3)
})- Download and install node.js from https://nodejs.org/en/download/
- Once the installation is done, a nodejs file gets created in the Program files.
- In the System Properties pop-up, move to Advanced, click on Environment Variables. Then click on OK.
- In the Environment Variables pop-up, move to the System variables section and click on New.
- Enter NODE_HOME and the node.js path (noted earlier) in the Variable name and the Variable value fields respectively in the New System Variable pop-up.
- Once the path of the node.js file is set, we shall create an empty folder (say cypressautomation) in any desired location.
- Next, we need to have a JavaScript editor to write the code for Cypress. For this, we can download Visual Studio Code from the link https://code.visualstudio.com/
- Once the executable file is downloaded, and all the installation steps are completed, the Visual Studio Code gets launched.
- Select the option Open Folder from the File menu. Then, add the CypressAutomation folder (that we have created before) to the Visual Studio Code.
- We need to create the package.json file with the below command from terminal −
- We have to enter details like the package name, description, and so on, as mentioned in the image given below −
- npm init
- Once done, the package.json file gets created within the project folder with the information we have provided.
- Finally, to install Cypress run the command given below −
- npm install cypress –save-dev
Cypress Test Runner helps to trigger the test execution.
To open the Test Runner, we have to run the below mentioned command −
node_modules/.bin/cypress open
The Test Runner window opens up after some time with the message that a sample project folder structure has been provided by Cypress under examples folder.
Click on the OK, got it! button.
fixtures − Test data in form of key-value pairs for the tests are maintained here.
integration − Test cases for the framework are maintained here.
plugins − Cypress events (prior and post events to be executed for a test) are maintained here.
support − Reusable methods or customized commands, which can be utilised by test cases directly, without object creation are created here.
videos − Executed test steps are recorded in the form of videos and maintained here.
node_modules − Project dependencies from the npm are maintained in this folder.It is the heart of the Cypress project execution.
cypress.json − Default configurations are set in this folder. The values of the current configurations can be modified here, which overrules the default configurations.
package.json − Dependencies and scripts for the projects are maintained in this folder.Basic Test Script
// test suite name
describe('Cypress Test Suite', function () {
// Test case
it('My First Cypress Test Case', function (){
// test step for URL launching
cy.visit("https://www.google.com/");
});
});Test Execution
For execution from the command line, run the command given below −
./node_modules/.bin/cypress run
All the files within the integration folder get triggered.
For execution from the Test Runner, run the command stated below −
./node_modules/.bin/cypress open
Then, click on the spec file that we want to trigger for execution.
To trigger execution for a specific file from command line, run the command mentioned below −
cypress run --spec ""
Cypress has the capability to run tests across multiple browsers. Currently, Cypress has support for Chrome-family browsers (including Electron and Chromium-based Microsoft Edge), WebKit (Safari’s browser engine), and Firefox.
To run the execution in Chrome, you need to run the below mentioned command:
./node_modules/.bin/cypress run — browser chrome
To run the execution in Firefox, run the command given below:
./node_modules/.bin/cypress run — browser firefox
To run the execution in headed mode, run the command given below:
./node_modules/.bin/cypress run — headed
//element is visible & enabled
cy.get('#username').should('be.visible').and('be.enabled')
//element is checked
cy.contains('Checkbox').and('be.checked')
//checks element having class attribute chkbox
cy.get('.checkbox').check()
//obtains children of element n
cy.get('n').children()
//removes input abc
cy.get('#text').type('abc').clear()
//clear abc cookie
cy.clearCookie('abc')
//clear all cookies
cy.clearCookies()
//clear all local storage
cy.clearLocalStorage ()
//click on element with id username
cy.get('#username').click()
//returns element in #txt having HireQA text
cy.get('#txt').contains('HireQA')
//double clicks element with id submit
cy.get('#submit').dblclick()
//pause to debug at start of command
cy.get('#txt').debug()
//It obtains window.document on the active page.
cy.document()
//iterate through individual li
cy.get('li').each(() => {...})
//obtain third td in tr
cy.get('tr>td').eq(2)
//obtain td from tr
cy.get('tr').find('td')
//obtain first td in tr
cy.get('tr>td').first()
//obtain all td from tr in list
cy.get('tr>td')
//It obtains a particular browser cookie by its name.
cy.getCookie('abc')
//It obtains all the cookies
cy.getCookies()
//navigate back
cy.go('back')
//navigate forward
cy.go('forward')
//It launches an URL.
cy.visit('https://www.hireqa.co.in')
//Wait for a certain time in milliseconds
cy.wait(1000)
//It obtains the document title of the active page.
cy.title()
//It prints the messages to the Command Log.
cy.log('Cypress logging ')
//It is used for page reloading.
cy.reload()
Cypress gives us access to the current URL through the .location() command.
cy.location();Extracting the path parameter:
cy.location('pathname');
Extracting the path using index:
cy.location('pathname').then(path => {
// path is the value from the previous command, `location("pathname").
// In our example, the value of `path` is "/path/1234".
const pathparam= path.split('/')[2];
});
Extract the value and store it for future:
Cypress provides a command named .wrap() to accomplish this. .wrap() takes a value and yields it as the result of a command, which can then be chained to any other Cypress commands.
cy.location('pathname').then(path => {
// path is the value from the previous command, `location("pathname").
// In our example, the value of `path` is "/path/1234".
const pathparam= path.split('/')[2];
cy.wrap(pathparam).as('pathparam');
});
Accessing the aliased pathparam
Aliased values can be accessed using another command: .get(). When retrieving values with named aliases, as in our situation, we specify the name with an @ prefix, like this:
cy.get('@pathparam');
We'll chain another .then() command to work with the result of the call to .get():
cy.get('@pathparam').then(pathparam => {
cy.request(`/api/articles/${pathparam}`).then(response => {
expect(response.status).to.eq(200);
// And any other assertions we want to make with our API response
});
});Cypress Describe
describe() is basically to group our test cases. We can nest our tests in groups as deep as we deem necessary. describe() takes two arguments, the first is the name of the test group, and the second is a callback function. There can be multiple describe in same file. Also one describe can be declared inside another describe.
Cypress Context
context() is just an alias for describe(), and behaves the same way.
Cypress it
it() is used for an individual test case. it() takes two arguments, a string explaining what the test should do, and a callback function which contains our actual test:
Cypress Specify
specify() is an alias for it(), so choose whatever terminology works best for you.
describe('First Describe', () => {
describe('Describe Inside Describe', () => {
it('first test inside', () => {
})
})
it('1st test', () => {
})
specify('2nd test', () => {
})
it('3rd test', () => {
})
})
context('2nd suite', () => {
it('first test', () => {
})
it('2nd test', () => {
})
it('3rd test', () => {
})
})
() => we are declaring call back function, A callback is a function passed as an argument to another function.
-
14
Events
-
54
Hello
---------------------------------
cy.get('.versal-badge')
.closest('ul')
.should('have.class', 'list')
closest command used from this simple example we can conclude that it fetches the element of versal-badge of which its ancestor is ul tag and that ul tag contains a class called a list.1. Implicit Assertion
a) should
b) and
2. Explicit Assertion
a) expect (BDD style)
b) assert (TDD style)
Implicit Assertion - should - example:
cy.visit("https://hireqa.co.in/interview-qa/?include_category=cypress")
cy.url().should('include', 'hireqa.co.in')
cy.url().should('eq', 'https://hireqa.co.in/interview-qa/?include_category=cypress')
cy.url().should('contain', 'hireqa')
//Verify the element is visible
cy.get('webelement').should('be.visible')
//Verify the element exist
cy.get('webelement').should('exist')
//Verify the entered username is correct
cy.get('webelement').type('username')
cy.get('webelement').should('have.value','username')
Implicit Assertion - and - example:
cy.visit("https://hireqa.co.in/interview-qa/?include_category=cypress")
cy.url().should('include', 'hireqa.co.in')
.and('eq', 'https://hireqa.co.in/interview-qa/?include_category=cypress')
.and('contain', 'hireqa')
.and('not.contain', 'xyz');
//Verify the logged-in user is same
let expectedName = 'hireqa';
cy.get('webelement').then((name) => {
let actualName = name.text()
expect(actualName).to.equal(expectedName)
})
//Assert example
assert.equal(actualName, expectedName)
assert.notEqual(actualName,expectedName)//Click on radio button and verify the radio button is clicked
cy.get('.radiobutton').check().should('be.checked')
//Verifying the radio button is not clicked
cy.get('.radiobutton').should('not.be.checked')//Select a single checkbox
cy.get('.checkbox').check().should('be.checked')
//Unselecting the checkbox
cy.get('.checkbox').uncheck().should('not.be.checked')
//Select multiple checkboxes using common locator
cy.get('.common-checkbox-locator').check().should('be.checked')
//Select the first checkbox
cy.get('.common-checkbox-locator').first().check().should('be.checked')
//Select the last checkbox
cy.get('.common-checkbox-locator').last().check().should('be.checked')
//Select the values from the Select dropdown
//First locate the dropdown and then the select the value
cy.get('.dropdown').select('India').should('have.value', 'India')
//Select the value from the dynamic dropdown by entering the value
cy.get('.dynamic-dropdown').click()
cy.get('.dropdown.text').type('India').type('{enter}')
//Verify the default selected value in dropdown
cy.get('.dropdown').should('have.text', 'India')
//Wikipedia search textbox example
cy.visit('https://www.wikipedia.org/')
cy.get('#searchInput').type('hyd')
cy.get('.suggestion-title').contains('Hyderabad').click()
//Google search example
cy.visit('https://www.google.com/')
cy.get('.gLFyf').type('Cypress')
cy.get('.wM6W7d > span').each(($el, index, $list) => {
if($el.text() == 'cypress automation')
{
cy.wrap($el).click()
}//Click on Alert button to generate the alert
cy.get('.alert-button').click()
//Cypress will handle alerts using cy.on and window:alert
cy.on('window:alert', (t) => {
expect(t).to.contains('This is JS Alert')
})
//Alert window automatically will be closed by Cypress
//Fetch the text from web page and validate
cy.get('.alert-message').should('have.text', 'You clicked on Alert')
//Handle JS Confirmation Alert. Confirmation alert will have OK and CANCEL button.
cy.get('.confirmation-alert-button').click()
//Cypress will handle alerts using cy.on and window:confirm
cy.on('window:confirm', (t) => {
expect(t).to.contains('This is JS Confirmation Alert')
})
//Cypress automatically closes the alert by default clicking on OK button
cy.get('.alert-message').should('have.text', 'You clicked on OK')
//Click on CANCEL button on Confirm Alert
cy.on('window:confirm', ()=> false);
//Handle Javascript Prompt Alerts
//Get the control on prompt alert before generate the prompt alert
cy.window().then((win) => {
cy.stub(win, 'prompt').returns('Welcome to JS Prompt Alert');
})
cy.get('prompt-alert-button').click();
//Authentication Prompt Alert
cy.visit("url", { auth:
{
username : "admin",
password : "password"
}
}
);
or
cy.visit("https://username:password@url")//This is applicable when new window opens in new tab and the element has target attribute
For Example:
Open New Window
Option 1 - Remove target attribute and the new window will open in the same browser window. It doesn't open the new tab.
cy.get('link').invoke('removeAttr', 'target').click();
//Verify the child window url
cy.url().should('include', 'child window url');
cy.wait(5000);
cy.go('back'); //back to parent tab
Option 2 - Get href value and use it
cy.visit('parenturl');
cy.get('link').then((e) => {
let childurl = e.prop('href');
cy.visit(childurl)
}
cy.url().should('include','childurl');
cy.wait(5000);
cy.go('back);
Note: Option -2 should have same domainOption 1:
let iframe = cy.get('#iFrameID')
.its('0.contentDocument.body')
.should('be.visible')
.then('cy.wrap');
iframe.clear().type('Welcome to Hire QA');
Option 2:
Install cypress-iframe plugin - npm install -D cypress-iframe
Add the command in cypress/support/command.js : import 'cypress-iframe'
Load the frame or switch to the frame: cy.frameLoaded('#frameID')- Ajax stands for Asynchronous JavaScript and XML. Ajax is a new technology for creating for faster and more interactive web applications. What ajax does is: Update a web page without reloading/refresh it.
- Google search is a best example of ajax. In case of google search, you simply type any keyword in search bar and just below the search bar a suggestion box with matching suggestions appears instantly, this is ajax.
- We can handle ajax in Selenium WebDriver with the use of Explicit Wait command.
// Set Driver path
System.setProperty("webdriver.chrome.driver", "C:\\drivers\chromedriver.exe");
WebDriver driver=new ChromeDriver();
//open google
driver.get("https://www.google.com");
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
//enter selenium in search box
driver.findElement(By.name("q")).sendKeys("selenium ");
//wait for suggestions
WebDriverWait wait=new WebDriverWait(driver, 20);
wait.until(ExpectedConditions.presenceOfElementLocated(By.className("sbtc")));
WebElement list=driver.findElement(By.className("sbtc"));
List rows=list.findElements(By.tagName("li"));
for(WebElement elem:rows) {
System.out.println(elem.getText());
}Execute specific cy.js file - npx cypress run --spec
Execute all cy.js files under the folder - npx cypress run --spec
Execute the cy.js file in Chrome browser (it will run the scripts in headless mode) - npx cypress run --spec --browser=chrome
Execute the cy.js file in Chrome browser (it will run the scripts in headed mode) - npx cypress run --spec --browser=chrome --headed